...........................................................................................................................................................................................................................................................................................................................................................................
خوش آمدید این سایت دارای مجوز می باشد برای مشاهده مجوز ها پایین صفحه را مشاهده فرمائید.
در تحلیل رگرسیون، ضریب بتا یکی از پارامترهای مهم است که برای ارزیابی اثر یک متغیر مستقل (متغیر پیشبین) بر متغیر وابسته (متغیر پاسخ) استفاده میشود. ضریب بتا نشان دهنده تغییر متوسط متغیر پاسخ بر اثر یک واحد تغییر در متغیر پیشبین است، همچنین نشان دهنده جهت و قدرت ارتباط بین دو متغیر است.
بطور رسمی، ضریب بتا توسط مدل رگرسیون تخمین زده میشود. در یک مدل رگرسیون خطی ساده، ضریب بتا نشان دهنده تغییر متوسط متغیر پاسخ بر اثر یک واحد تغییر در متغیر پیشبین است. اگر ضریب بتا مثبت باشد، این نشانگر است که افزایش در متغیر پیشبین همراه با افزایش در متغیر پاسخ است. و اگر ضریب بتا منفی باشد، این نشانگر است که افزایش در متغیر پیشبین همراه با کاهش در متغیر پاسخ است.
چگونه فایل اکسل را غیر قابل ویرایش کنیم
مقدار ضریب بتا نیز نشان میدهد که به چه اندازه تغییر متغیر پاسخ در واحدهای استاندارد تغییر میکند. اگر ضریب بتا بزرگتر از 1 باشد، این نشانگر است که تغییر در متغیر پیشبین بر متغیر پاسخ با تغییر بیشتری همراه است. در صورتی که مقدار ضریب بتا کوچکتر از 1 باشد، تغییر در متغیر پیشبین با تغییر کمتری در متغیر پاسخ همراه است.
بنابراین، ضریب بتا به ما اطلاعاتی در مورد ارتباط بین متغیرهای پیشبین و پاسخ را میدهد و میتواند در تفسیر نتایج و پیشبینی مقادیر پاسخ براساس مقادیر پیشبین مفید باشد.
خلاصه: ضریب مسیر بیان کننده وجود رابطه علی خطی و شدت و جهت این رابطه بین دو متغیر مکنون است.
در حقیقت همان ضریب رگرسیون در حالت استاندارد است که ما در مدل های ساده تر رگرسیون ساده و چندگانه مشاهده می کردیم.
عددی بین 1- تا +1 است که اگر برابر با صفر شوند ، نشان دهنده ی نبود رابطه ی علی خطی بین دو متغیر پنهان است.
توجه: همه ی پرسشنامه هااز منابع معتبر تهیه شده، استاندارد ، دارای روایی و پایایی و منابع داخل و پایان متن می باشند . همه ی پرسشنامه ها قابل ویرایش در قالب نرم افزار ورد Word می باشد.
به متغیر تعدیل کننده گاهی متغیر مستقل فرعیگفته می شود.
متغیر تعدیلگر یک متغیر کمی یا کیفی است که جهت و قدرت رابطه متغیر مستقل و وابسته را تحت تاثیر قرار میدهد.
برای نمونه متغیر عزت نفس در بررسی رابطه فرسودگی شغلی و مدیریت زمان یک متغیر تعدیل کننده است.
حال در نظر بگیرید که اثر تعدیل گری عزت نفس منفی و معنی دار باشد باید به صورت زیر آن را تفسیر کنیم.
عزت نفس بر شدت تأثیر متغیرفرسودگی شغلی بر مدیریت زمان اثر منفی و معکوس دارد . لذا در افرادی که عزت نفس آن ها بالا هست، فرسودگی شغلی کمتر می تواند بر مدیریت زمان تأثیر بگذارد ولی در افرادی که عزت نفس آن ها پایین هست، فرسودگی شغلی بیشتر می تواند بر مدیریت زمان تأثیر بگذارد.
بنابراین عزت نفس ، رابطه فرسودگی شغلی و مدیریت زمان را تعدیل میکند.
انواع متغیر تعدیلکننده و روش محاسبه آن
بارون و کنی (۱۹۸۶) در مقاله خود چهار حالت گوناگون از وضعیت متغیر مستقل و تعدیلگر را به شرح زیر بررسی کردند:
حالت اول: متغیر مستقل و تعدیلگر هر دو از نوع طبقهای (اسمی-رتبهای) باشند.
حالت دوم: متغیر تعدیلگر از نوع طبقهای و متغیر مستقل پیوسته باشد.
حالت سوم: متغیر تعدیلگر پیوسته و متغیر مستقل از نوع طبقهای باشد.
حالت چهارم: هر دو متغیر تعدیلگر و مستقل پیوسته باشند.
در حالت اول برای مثال بخواهید نقش جنسیت را در تاثیر سمت سازمانی بر رضایت شغلی ارزیابی کنید در این حالت میتوانید از تحلیل واریانس دوراهه استفاده کنید.
حالت دوم بیشترین کاربرد را مطالعات مدیریت دارد. برای مثال بخواهید نقش جنسیت را در رابطه اعتماد و رضایت شغلی بسنجید. جنسیت یک متغیر طبقهای است و اعتماد و رضایت متغیرهای پیوسته میباشند. در این حالت میتوانید از روش محاسبه اثر تعدیلگر با رگرسیون خطی استفاده کنید.
برای محاسبه حالت سوم پیشنهادی ندارم زیرا رویه مرسومی نیست ولی برای حالت چهارم میتوانید از محاسبه متغیر تعدیلگر با روش رگرسیون هایس استفاده کنید.
متغیر تعدیلکننده و رگرسیون سلسلهمراتبی
رگرسیون سلسلهمراتبی یا ترتیبی این امکان را فراهم میآورد که تاثیر چند متغیر مستقل بر یک متغیر وابسته طی چند مرحله مشخص شود. از رگرسیون سلسلهمراتبی برای بررسی نقش متغیرهای تعدیلگر براساس رویه پیشنهادی بارون و کنی استفاده کرد.
اگر پرسشنامهای با طیف لیکرت استفاده میکنید تمامی سازههایی که توسط چندین گویه مورد سنجش قرار میگیرند باید به یک شاخص قابل مشاهده تبدیل میشوند. برای این کار میانگین گویههای سنجش آنها را محاسبه کنید.
برای بررسی روابط علی بین متغیرها به طور هماهنگ تلاش های زیادی در دهه اخیر صورت گرفته است. یکی از روش های امید بخش در این زمینه معادلات ساختاری یا تحلیل چند متغیری با متغیرهای پنهان است. از این روش تحت عنوان مدل علی و تحلیل انکوانام شده است. از طریق این روش می توان قابل پذیرش بودن مدل های نظری را در جامعه های خاص با استفاده از داده های همبستگی، غیر آزمایشی و آزمایشی تحلیل کرد. فرضیه مورد بررسی در یک مدل معادلات ساختاری، یک ساختار علی ویژه بین گروهی ا از متغیرهای غیرقابل مشاهده است. این متغیرها ها از طریق گروهی از متغیرهای آشکار اندازه گیری می شود یک مدل معادلات ساختاری کامل از دو جزء بوجود شده است:
الف) یک مدل ساختاری که ساختار علی خاصی را بین متغیرهای پنهان در نظر می گیرد و
ب) یک مدل اندازه گیری که روابطی را بین متغیرهای پنهان و متغیرهای آشکار تعریف می کند. هنگامی که داده های بدست آمده از نمونه مورد بررسی به صورت طیف همبستگی یا کواریانس در آید و توسط گروهی از معادلات رگرسیون تعریف شود، مدل را می توان با استفاده از نرم افزارهای مرتبط تحلیل کرد و نتایج آن را برای جامعه ای که نمونه از آن استخراج شده بدست آورد.
این تحلیل برآوردهایی از پارامترهای مدل (ضرایب مسیر و جملات خطا) و همچنین چند ویژگی برای خوب بودن نتایج بدست آمده فراهم می آورد. تخمین پارامترها و اطلاعات مربوط به خوب بودن تحلیل را می توان برای تغییرات احتمالی در مدل و آزمون دوباره مدل نظری مورد آزمون قرار داد
پایان نامه – مقاله نویسی
مقدمه
یکی از شیوه های تحلیل داده های آماری، تحلیل مسیر است که بیشتر با استفاده از رگرسیون چند متغیره انجام می گیرد. این روش برای تحلیل مدل های علی به کار گرفته می شود و مستلزم طرح مدلی به صورت نمودار علی است و در واقع رابطه علی را نشان می دهد و به ما کمک می کند بدانیم چه می خواهیم بگوییم. علاوه برآن تحلیل مسیر، شکلی از تحلیل رگرسیون عملی است که در آن برای حل کردن مسئله با تحلیل فرضیه های پیچیده، از نمودار مسیر استفاده می شود. تحلیل مسیر یکی از چندین تحلیل آماری است که تحت عنوان مدل معادلات ساختاری شناخته شده اند. این روش امکان تحلیل روابط علی بین دو یا چند متغیر را بوجود می آورد، که ممکن است به صورت مستقل، وابسته، گسسته یا پیوسته، پنهان یا آشکار و یا هر دو در یک معادله خطی به کار روند. تحلیل مسیر معمولا در تحقیقات اکتشافی و تحلیل های نظریه ثانویه بکار می رود. یک محقق می تواند گروهی از داده ها را برای بررسی روابط غیر قابل پیش بینی بین متغیرها تحلیل کند، خواه بطور مستقیم باشد، خواه غیر مستقیم، و به همین ترتیب از طریق مدل های گوناگون بهترین مدل را به دست آورد. همچنین می تواند نظریه ها را به وسیله برقراری ارتباط که پیش بینی شده اند یا مورد شک هستند تحلیل کند و از این طریق بهترین مدل را بدست آورد.
تحلیل چند متغیره تحلیل مسیر
تحلیل مسیر روش آماری به کار بردن ضرایب بتای استاندارد رگرسیون چند متغیرى در مدل هاى ساختاری است. هدف تحلیل مسیر به دست آوردن تخمین های کمى روابط علّى بین گروهی از متغیرهاست. ساختن یک مدل علّی الزاما به معنای وجود روابط علّی در بین متغیرهای مدل نیست بلکه این روابط علی بر اساس فرضیه های همبستگی و نظریه و پیشینه تحقیق استوار است. تحلیل مسیر به ما می گوید که کدام مسیر مهمتر و یا معنادارتر است.
ضرایب مسیر براساس ضریب استاندارد شده رگرسیون تحلیل مى شود. یک متغیر به صورت مجموعه ای از دیگر متغیرها در نظر گرفته مى شود و مدل رگرسیونى آن طرح مى شود. برای بدستآوردن تخمین های ضرائب اصلی مسیر کافی است هر متغیر وابسته (درونزا) به متغیرهائی که مستقیماً تحت تأثیر آن است برگردانده می شود.
به بیان دیگر برای تخمین های هر یک از مسیرهای مشخص شده، ضرائب استانداردشده رگرسیون (یا ضرائب مسیر) مورد محاسبه قرار می گیرد. این ضرائب از طریق ایجاد معادلههای ساختاری یعنی معادلههائی که ساختار روابط در نظر گرفته شده در یک مدل را معین میسازد به دست میآیند. تحلیل مسیر صرفًا بر روی متغیرهای دیده شده قابل انجام است.
مشروط کردن مدل نظری
برای ساختن یک مدل از طریق تحلیل مسیر، ده شرط بیان شده است که به کمک آنها، امکان تجزیه و تحلیل علّی فراهم میشود. درده شرط بحث، شده هفت شرط اول مدل نظری مناسبی را برای تجزیه و تحلیل و نتیجه گیری علّی ایجاد می کند
. بیان رسمی نظری در قالب مدل ساختاری ۲. وجود منطق نظری برای فرضیههای علّی ۳. مشخص نمودن نظم علّی ۴. مشخصنمودن مسیر روابط علّی ۵. نوشتن معادلات توابع ۶. معین نمودن مرزهای مدل ۷. ثابت بودن مدل ساختاری ۸. کاربردیکردن متغیرها ۹. تأیید تجربی معادلات کاربردی ۱۰. نتیجه گیری مدل ساختاری از طریق دادههای تجربی
اصول طرح نمودار مسیر
نبود حلقه ۲. نبود مسیر رفت و برگشت بین متغیرها ۳. حداکثر تعداد رابطه های اجازه داده شده بین متغیرهای درونی برابر با تعداد مسیرها در تحلیل مسیر یک متغیر ممکن است همزمان هم نقش متغیر مستقل و یا وابسته را داشته باشد . به عبارت دیگر یک متغیر در مدل علّی ممکن است نسبت به بعضی متغیرها مستقل و نسبت به بعضی دیگر وابسته باشد. برای جلوگیری از ابهام و سردرگمی به جای مستقل و وابسته از دو عنوان دیگر برای مشخص کردن نوع متغیرها در روش تحلیل مسیر استفاده می شود.
متغیر های درونی و بیرونی
کلیه متغیرهای موجود در یک مدل و الگوی علی دارای دو نوع اصلی است. نوع اول متغیر برونی است و نوع دوم متغیر درونی نام دارد. متغیر بیرونی متغیری است که هیچ تاثیری از سایر متغیرهای الگو و مدل طراحی شده قبول نمی کند. در حقیقت مقدار متغیر ببیرونی توسط بقیه متغیرهای درونی مدل مشخص نمی شود بلکه مقدار آن دربیرون از مدل مشخص می شود. متغیر درونی (وابسته) متغیری است که از حداقل یک متغیر دیگر در مدل و الگوی طراحی شده تاثیر می گیرد. مقدار متغیر وابسته توسط سایر متغیرهای درونی مدل مشخص می شود. بنابراین بر اساس تعریف یک متغیر نمی تواند همزمان هم وابسته و هم مستقل باشد. از نظر نموداری متغیر مستقل متغیری است که با هیچ فلشی نشان داده نمی شود در حالیکه متغیر وابسته متغیری است که حداقل یک فلش به سمت آن می رود و توسط یک فلش نشان داده می شود.
مسیر
مسیر در مدل علّی نشان دهنده تاثیر یک متغیر بر متغیر دیگر است. در تحلیل مسیر معمولا مسیر را با یک فلش جهت دار یک جهته که ازمتغیر مستقل به متغیر مربوطه وابسته رسم شده است نشان می دهند. نمایش تحلیل مسیر دارای یک نمایش ریاضی است که به صورت عمومی داده می شود. حرف i نشان دهنده متغیر مستقل حرف jنشان گر متغیر وابسته است و همواره اصل j>I برقرار است به عبارت دیگر I متغیر ی است که تحت تاثیر قرار می گیرد و j متغیری است که تاثیر می گذارد بر روی آن . پس مسیر فرضی ۴۱ pیعنی یک متغیر بر چهار متغیر دیگر موثر است یا این که متغیر یک متغیر مستقل و متغیرچهار متغیر وابسته است
جملات اشتباه
جمله اشتباه نشان دهنده میزانی از واریانس متغیر وابسته است که از سوی متغیرهای موثر بر آن تحلیل می شود بنابراین در یک مدل علّی به تعداد متغیرهای وابسته، جمله اشتباه وجود دارد. جمله اشتباه را معمولا با حرف e یا d نشان می دهند.
طراحی مدل مسیر
محقق بر اساس تحقیقات قبلی مشابه و دارای ارتباط شروع به انتخاب متغیرها و تعیین روابط علّی بین آنها بر اساس منطق تحلیلی و نظری می نماید. نتایج این مرحله ممکن است گروهی از فرضیه های مرتبط و منسجم باشد که معمولا از طریق طرح و یا مدل ریاضی بیان می شود. در تحقیقات علوم اجتماعی مدلهای مفهومی معمولا به شکل رسم کردن مدل و رسم نمودار بیان می شوند.
انواع مدلهای تحلیل مسیر
مدل متغیرهای مستقل : همان رگرسیون چندگانه است اما بین متغیرهای مستقل ۲. همبستگی برقرار نمی شود. ۳. مدل وابسته : مدل وابسته همانند مدل مستقل است با این تفاوت که بین برخی متغیرهای مدل رابطه وجود دارد. ۴. مدلهای دارای متغیر تعدیل کننده : حداقل یک متغیر تعدیل کننده بین دو متغیر دیگر قرارمی گیرد. ۵. مدلهای دارای متغیر میانجی : یک متغیر بر ارتباط بین دو متغیر دیگر اثر تعدیل کننده دارد. ۶. مدلهای یک طرفه :جهت فلشها به یک طرف بوده و برگشت به عقب ندارد یعنی همه مسیرها به یک سمت هستند. ۷. مدلهای دوطرفه : جهت فلشها و مسیرها دارای حرکت به طرف عقب بوده و یک حلقه درست می کند. این نوع مدلها در مطالعات علوم اجتماعی و جامعه شناسی زیاد استفاده نمی شود .
آزمون مدل نظری
برای تحلیل مدل نظری می توان از رگرسیون در نرم افزار اس پی اس اس و معادلات ساختاری در نرم افزارهایی مانند .. آموس و لیزرل استفاده نمود. در نرم افزار اس پی اس اس به تعداد متغیرهای وابسته باید از گزینه رگرسیون خطی چندگانه و یا ساده استفاده نمود. لیکن در نرم افزار آموس مدل نظری تحقیق به صورت یکجا تحلیل می شود
انواع رابطه بین متغیرها در نمودار تحلیل مسیر
دو روشی که یک متغیر مستقل ممکن است بر یک متغیر وابسته تأثیر بگذارد. ۱. اثر مستقیم: نشان دهنده یک اثر مستقیم متغیر x بر روی متغیر y است (x1 ® y ) 2. اثر غیر مستقیم: یک اثر غیرمستقیم متغیر x بر روی y از طریق یک متغیر مستقل دیگر.رابطه بین X و Y وقتى غیر مستقیم است که X علت Z است و Z نیز به نوبه خود در Y تاثیر می گذارد . بسیاری از پژوهشگران تمایل دارند اثر کلی یک متغیر را بر متغیر دیگر حساب کنند کنند این کار با استفاده از روش جمع اثر مستقیم با مجموع آثار غیرمستقیم آن به دست میآید. آثار غیرمستقیم از طریق حاصلضرب ضرائب هر مسیر بدست می آید : ۳. اثر نامشخص: رابطه بین X و Y وقتى نامشخص است که Z علت هر دو متغیر X و Y باشد. ۴. اثرات تبیین نشده: رابطه بین دو متغیر وقتى تبیین نشده است که هر دوى آنها مستقل بوده و بنابراین تبیین تغییر پذیرى بین آنها توسط مدل ما ممکن نباشد
بوجود آورندگان آزمون تحلیل مسیر
تحلیل مسیر در سال ۱۹۱۸ توسط سیول رایت طرح شد که تا سال ۱۹۲۰ مطالب بسیاری را در مورد آن نوشته است. و از آن زمان برای مدل سازی های پیچیده در زمینه روان شناسی، اقتصاد و جامعه شناسی به کار رفت
نوع آزمون تحلیل مسیر (توضیح علت پارامتریک ؛ ناپارمتریک و …)
آزمون تحلیل مسیر جزء آزمون های نرمال بحساب می آید دلایل آن به شرح زیر می باشد: ۱. هر یک از موارد مشاهده شده مستقل است، یعنی اینکه انتخاب یک مورد به انتخاب مورد دیگری وابسته نیست. ۲. واریانس متغیرها مساوی یا تقریبا مساوی است. ۳. توصیف متغیرها براساس مقیاس فاصله ای یا نسبی انجام می گیرد. ۴. توزیع نمره ها در جامعه نرمال یا نزدیک به توزیع نرمال است
شرایط استفاده از آزمون تحلیل مسیر (در مقیاس اسمی، ترتیبی و ..)
برخی از فرضیه های به کار گیری تحلیل مسیر به شرح زیر می باشد: ۱. کالین سفارش می کند که به ازای هر شاخص ( نه متغیر) در مدل حداقل ۱۰ مورد به محدوده نمونه اضافه باید کرد . در نظر گرفتن نسبت ۲۰ نمونه برای هر شاخص بسیار خوب است . ۲. مقیاس فاصله ای و نسبتی بودن برای متعیرهای مدل. اگر چه در مطالعات علوم اجتماعی از طیف لیکرت به مقدار زیادی استفاده می شود و این مقیاس رتبه ای است لیکن بسیاری از محققان مقیاس لیکرت را بصورت ، مقیاس فاصله ای در نظر می گیرند. ۳. وجود رابطه خطی بین متغیرهای مستقل با متغیر وابسته ۴. غیر همبسته بودن جملات اشتباه متغیرها . ۵. نرمال بودن داده ها و مشخص کردن آن با آزمون ۶. عدم وجود وابستگی چندگانه : وابستگی چندگانه زمانی ایجاد می شود که بین حداقل دو متغیر مستقل همبستگی زیادی وجود داشته باشد. ۷. تک بودن متغیرها : یک متغیر از ترکیب دو متغیر غیر اصلی بوجود آمده باشد و متغیرهای فرعی دارای رابطه دارای علامت مشابه با سایر متغیرها باشد. ۸. تجزیه همبستگی : همبستگی = اثرات مستقیم + اثرات غیرمستقیم
به کار گیری آزمون تحلیل مسیر
آزمون تحلیل مسیر امکان آزمون روابط علی بین دو یا چند متغیر رابوجود می آورد ، که ممکن است به صورت مستقل، وابسته، گسسته یا پیوسته، پنهان یا آشکار و یا هر دو در یک معادله دارای رابطه همبستگی به کار روند)
حل مثال با نرم افزار اس پی اس اس spss
به منظور بررسی رابطه بین سرمایه روانشناختی و مشغولیت تحصیلی با میانجی انگیزه پیشرفت در دانش آموزان دختر پایه اول متوسطه پژوهشی انجام گرفت که تعداد ۱۰۰ دانش آموز پسر پایه اول متوسطه به عنوان نمونه برای تحقیق انتخاب شدند و فرضیه های زیر مورد تحلیل قرار گرفت: فرضیه ۱. سرمایه روانشناختی بر انگیزه پیشرفت تاثیر مثبت دارد. فرضیه ۲. سرمایه روانشناختی بر مشغولیت تحصیلی تاثیر مثبت دارد. فرضیه ۳. انگیزه پیشرفت بر مشغولیت تحصیلی تاثیر مثبت دارد. فرضیه ۴. سرمایه روانشناختی از طریق انگیزه پیشرفت بر مشغولیت تحصیلی اتاثیر مثبت دارد. این روابط در الگوی پیشنهادی حاضر در نمودار ۱ نشان داده شده اند.
آموزش روش تحلیل مسیر در اس پی اس اس
همانگونه که نتایج جدول ۱ نشان می دهد، میانگین و انحراف معیار آزمودنی های کل نمونه (۱۰۰) به ترتیب در سرمایه روانشناختی (۱۴۵) و (۲۳.۳۴)، انگیزه پیشرفت (۴۵/۷۵) و (۶۳/۷) و مشغولیت تحصیلی (۷۳/۶۸) و (۲۹/۴۲) است.
میانگین و انحراف معیار هر یک از خرده شاخص های پنهان به طور مفصل در جدول ۱ ارائه شده است.
آموزش روش تحلیل مسیر در اس پی اس اس spss
رابطه همبستگی متغیرهای پژوهش در جدول ۲ نشان داده شده است.
آموزش روش تحلیل مسیر در اس پی اس اس spss
همانطور که نتایج جدول ۲ نشان می دهد، همه رابطه های همبستگی بین متغیرها در سطح ۰۱/۰ معنی دار هستند. این تحلیل های همبستگی نظریه ای در خصوص روابط دومتغیری بین متغیرهای پژوهش را ایجاد میکنند.
جهت آزمودن همزمان روابط درنظر گرفته شده در پژوهش حاضر، روش الگویابی معادلات ساختاری اجرا شده است. نمودار ۲ الگوی پایانی پژوهش حاضر و ضریب های مسیر در میان متغیرها را نشان می دهد.
آموزش روش تحلیل مسیر در اس پی اس اس spss
جدول ۳ الگوی ساختاری، مسیرها و ضریب های استاندارد آن ها در الگوی نهایی این پژوهش را نشان می دهد. جدول ۳ نشان می دهد که همه ضریب های مسیرهای مستقیم در الگوی نهایی معنی دار هستند.
آموزش روش تحلیل مسیر در اس پی اس اس spss
یافته های مربوط به فرضیه های الگوی پیشنهادی
در این بخش ابتدا مسیرهای مستقیم الگو و سپس یافته های مربوط به مسیرهای غیرمستقیم (به طور واسطه ای ) گزارش می شوند.
مسیرهای مستقیم الگوی مطرح شده
یافته های مربوط به فرضیه های مستقیم الگوی مطرح شده با توجه به نتایج جدول ۳ مورد بررسی قرار می گیرند:
فرضیه ۱. سرمایه روانشناختی بر انگیزه پیشرفت تاثیر مثبت دارد. سرمایه روانشناختی + انگیزه پیشرفت با توجه به جدول شماره ۳ ضریب مسیر سرمایه روانشناختی با انگیزه پیشرفت معنیدار می باشد (۲۵۵/۰ =β، ۰۰۳/۰ =Ƥ(. این نتیجه ، فرضیه ۱ را تأیید می کند.
فرضیه ۲. سرمایه روانشناختی بر مشغولیت تحصیلی تاثیر مثبت دارد. سرمایه روانشناختی + مشغولیت تحصیلی با توجه به جدول شماره ۳ ضریب مسیر سرمایه روانشناختی به مشغولیت تحصیلی معنی دار میباشد (۷۹۹/۰ =β، ۰۰۰۱/۰ =Ƥ(. این نتیجه ، فرضیه ۲ را تأیید می کند.
فرضیه ۳. انگیزه پیشرفت بر مشغولیت تحصیلی تاثیر مثبت دارد. انگیزه پیشرفت + مشغولیت تحصیلی با توجه به جدول شماره ۳ ضریب مسیر انگیزه پیشرفت به مشغولیت تحصیلی معنی دار می باشد (۲۱۲/۰ =β، ۰۰۴/۰ =Ƥ(. این نتیجه ، فرضیه ۳ را تأیید می کند.
مسیرهای غیرمستقیم الگوی مطرح شده
با توجه به مسیرهای غیرمستقیم مطرح شده به بررسی روابط تعدیل کننده متغیرهای مدل مطرح شده در پژوهش حاضر می پردازیم .
یافته های مربوط به روابط واسطه ای متغیرهای مطرح شده
در این بخش نتایج حاصل از آزمون فرضیه های مربوط به مسیرهای غیرمستقیم و تاثیرهای واسطه-ای بیان خواهند شد. در این پژوهش، ۱ فرضیه بر اساس وجود روابط غیرمستقیم است.
فرضیه ۴. سرمایه روانشناختی از طریق انگیزه پیشرفت بر مشغولیت تحصیلی تاثیر مثبت غیرمستقیم دارد.
برای تعیین معنی داری روابط واسطه ای، از بوت استراپ استفاده شده است. جدول ۴ نتایج حاصل از بوت استراپ در برنامه ماکرو، پریچر و هیز (۲۰۰۸) را در رابطه سرمایه روانشناختی و مشغولیت تحصیلی با میانجی گری انگیزه پیشرفت نشان می دهد.
آموزش روش تحلیل مسیر در اس پس اس اس spss
مطابق با جدول ۴ محدوده پایین محدوده اطمینان برای انگیزه پیشرفت به عنوان متغیر تعدیل کننده بین سرمایه روانشناختی و مشغولیت تحصیلی (۰۲۳۶/۰) و حد بالای آن (۱۳۶۶/۰) است.
محدوده اطمینان برای این محدوده اطمینان ۹۵ و تعداد نمونه گیری مجدد بوت استراپ ۲۰۰ است. با توجه به اینکه صفر بیرون از این محدوده اطمینان قرار می گیرد، این رابطه با واسطه معنی دار بوده و فرضیه ما مورد تأیید قرار می گیرد.
تحلیل آماری با کم ترین هزینه و بالاترین کیفیت انجام می گیرید. تحلیل داده های آماری با نرم افزارهای کمی و کیفی نرم افزار های کمی SPSS و PLS و Amos نرم افزار های کیفی: Maxquda و Nvivo تعیین حجم نمونه با:Spss samplepower کافی است قیمت ها را با جاهای دیگر مقایسه کنید. کیفیت بالا، قیمت مناسب و خدماتی که به نیازهای شما پاسخ می دهند! با ما همراه باشید و پژوهش خود را به یک تجربه ی موفق تبدیل کنید.
انجام پژوهش کیفی.jpg
خدمات تخصصی پژوهش و تحلیل داده های آماری با مناسبترین قیمت و کیفیت برتر!
SPSS (نام کامل: Statistical Package for the Social Sciences) یکی از متداولترین و قدرتمندترین ابزارها برای تحلیل دادههای آماری در زمینههای مختلف از جمله علوم اجتماعی، علوم رفتاری، بهداشت، اقتصاد و … است.
در اینجا به توضیحات مختصری درباره چگونگی تحلیل آماری با استفاده از SPSS میپردازیم:
1. ورودی دادهها به SPSS:
ابتدا، دادههای خود را به فرمت متنی یا اکسل آماده کنید و سپس آنها را به نرمافزار SPSS وارد کنید. معمولاً دادهها به صورت جدول وارد میشوند که هر ستون مربوط به یک متغیر و هر سطر مربوط به یک مشاهده (نمونه) است.
2. توصیف آماری:
متغیرها: بررسی و توصیف متغیرها شامل میانگین، واریانس، مد، میانه و… است. این اطلاعات به توصیف متغیرها کمک میکند.
جمعیت و نمونه: اطلاعات مربوط به تعداد مشاهدات (نمونه) و اطلاعات مختصر درباره ویژگیهای جمعیتی.
3. آزمونهای آماری:
SPSS به شما امکان ترکیبی از آزمونهای آماری کلاسیک و پیشرفته را فراهم میکند:
آزمون t (تی-آزمون): برای مقایسه میانگین دو گروه.
آنالیز واریانس (ANOVA): برای مقایسه میانگین بیش از دو گروه.
رگرسیون و کوواریانس: برای بررسی ارتباط بین متغیرها.
آزمونهای همبستگی: بررسی رابطه بین متغیرها.
4. گزارشگیری:
نتایج تحلیلهای آماری به صورت گزارشهای استانداردی ارائه میشوند که شامل نمودارها، جداول و تفسیر نتایج آماری است. این گزارشها میتوانند به عنوان اسناد معتبر برای ارائه نتایج به دیگران (مثلاً همکاران یا استادان) استفاده شوند.
برای یادگیری بیشتر و استفاده بهینه از SPSS، میتوانید از منابع آموزشی آنلاین، کتابها، دورههای آموزشی محلی یا دورههای آموزشی آنلاین استفاده کنید. همچنین، وبسایت رسمی SPSS منابع و آموزشهای آنلاین بسیار مفیدی را برای یادگیری این نرمافزار ارائه میکند.
یکی از مهمترین عوامل برای شرکتهای بزرگ در خارج از کشور یا موسسات داخلی و درآمد آنها، استفاده از علم تحلیل آمار است؛
زیرا با کمک این علم نوین میتوانند به پیشبینیهای بسیار جامع و کاملی از روند برخی موارد دست پیدا کنند
و به علاوه، گزارش دقیقی از وضعیت حال را در اختیار بگیرند. همچنین، ممکن است بارها با مسئله ارائه پایان نامه توسط spss رو به رو شده باشید.
این نرم افزار توسط شرکت آی بی ام طراحی و توسعه داده شده است.
برای تحلیل آماری نرمافزارهای زیادی طراحی شدهاند که معروفترین آنها، نرمافزار spss یا نرمافزار بسته آماری برای علوم اجتماعی است.
به دلیل اهمیت این نرمافزار در جامعه آماری، مقالهای جامع درباره این نرمافزار تهیه شده است.
اگر میخواهید ببینید spss چیست و به دنبال آموزش این نرمافزار هستید، ادامه مقاله را از دست ندهید.
آشنایی کلی با نرم افزار spss
نرمافزار SPSS یا Statistical Package for the Social به عنوان یک نرمافزار تحلیلی و آنالیز اطلاعات، از پرسشنامهها و فرمهای مختلف دریافت میکند
و سپس آنها را در قالب جداول و نمودارها به کاربر ارائه میدهد تا تجزیه و تحلیل آنها به صورت دقیقتر صورت پذیرد.
این نرمافزار در زمینه بازار و داد و ستد، سلامتی، نقشهبرداری دولتی و آموزشی توسط پژوهشگران به کار گرفته میشود.
کاربردهای نرم افزار spss چیست؟
بعد از اینکه با زبان ساده به پاسخ spss چیست رسیدید، نوبت به این میرسد که کاربردهای این نرم افزار آماری را مورد بررسی قرار دهید.
به این ترتیب است که اهمیت آشنایی با آن را بیشتر درک میکنید.
به طور کلی میتوان کاربردهای زیرا را برای این نرمافزار بیان کرد:
– این نرم افزار توسط پژوهشگران در شرکت های دولتی و نقشه برداری و سازمان های آموزشی و بازاریابی استفاده میشود. – انواع آمار توصیفی را با جداول همراه با ذکر بسامد ها و کاوشها به صورتی دقیق و نسبی ارائه میدهد. – برای به دست آوردن آمارهای دو یا چند متغیر کاربرد دارد. نمونه آن تحلیل پراکنش و همبستگی آزمونهای استخدامی است. – درآمدها را به صورت نسبی و دقیق پیش بینی و ارائه میکند. – انواع آمارها را به صورت تحلیل بندی و خوشه ها بررسی و توصیف خواهد کرد. – خلاصه آماری گراف ها، جداول و نمودارهای آماری و توزیع های گسسته و پیوسته را به دست میآورد. – رگرسیون را مورد پردازش قرار میدهد. علاوه بر این کاربردها میتوان استفاده از نرم افزار spss را در رشتههای مختلف مورد بررسی قرار داد.
– Spss و صنایع
بیشتر افراد با کاربرد گسترده این نرمافزار در حوزه های علمی و پژوهشی آشنا هستند. با این حال بهتر است مسئله spss چیست در رشته صنایع نیز مورد بحث قرار بگیرد.
حتی میتوان این ابزار را یکی از شیوه های پرکاربرد در رشته صنایع به حساب آورد. زیرا در این حوزه علاوه بر مباحث تحلیلی و آماری،
نرم افزار spss بستر خوبی برای داده کاوی و تحلیل اطلاعات حاصل از بخش های تولیدی، فروش، تدارکات و نیروی انسانی به شمار میرود.
– Spss و کشاورزی
استفاده از آزمون های آنالیز واریانس در پایان نامه ها متداول ترین شیوه استفاده اس.پی.اس.اس در کشاورزی است.
تحلیل های آماری در طرح های آزمایشی کشاورزی به ویژه در دنیای پیشرفته امروز برای توسعه خود به ایده های خلاقانه احتیاج دارند. بنابراین بهترین گزینه برای آنها spss است.
– Spss و روانشناسی
روانشناسی از جمله علوم های پژوهشی محور است که تنها با تحلیل دادههای آماری میتواند نتایجی را برای فرضیات در نظر بگیرد.
بنابراین کار با نرم افزار spss است که به آنها فرصت تحلیل دادههای به دست آمده را با توجه به پرسشنامه های متعدد در این حوزه میدهد.
سپس با بررسی و تحقیقات روی این دادها است که به بهترین نتیجه دست پیدا میکنند.
– Spss و پزشکی
نتیجه تحقیقات و آزمایشات پزشکی را میتوان در نرم افزار spss مورد تحلیل و بررسی قرار داد. آزمون های آماری طراحی شده در این برنامه اسن امکان را به خوبی فراهم کردهاند.
برای مثال میتوان به آزمون هایی چون آزمون t ، آزمون نسبت ، آزمون مقایسه و میانگین، آنالیز و بررسی واریانس، رگرسیون و آزمون های ناپارامتری اشاره کرد.
– Spss و اقتصاد
تحلیل گران اقتصادی نیز به پاسخ spss چیست، احتیاج پیدا میکنند.
زیرا با کمک این نرم افزار است که آنالیز فرآیند های اقتصادی را انجام داده و با توجه به نتیجهی آماری تاثیر هر عامل اقتصادی بر سایر عوامل را مورد تحلیل و بررسی قرار میدهند.
– پایان نامه با spss
در نوشتن پایان نامه دکترا و کارشناسی ارشد یکی از پرکاربردترین نرمافزارها، spss است.
تحلیل و بررسی داده های آماری در فصل 4 پایان نامه با کمک از برنامه اس.پی.اس.اس انجام میشود و آن دسته افرادی که با این نرمافزار آشنایی ندارد،
باید هزینه زیادی برای انجام این فصل از پایان نامه به افراد متخصص پرداخت کنند تا کار آن ها انجام دهند.
از جمله کاربردهای نرم افزار آماری SPSS میتوان به موارد زیر اشاره کرد:
تحلیل و آنالیز دادههای وارد شده
انجام تحقیقها و پایان نامههای آماری
ایجاد جدولهای فراوانی و نتیجه گیریهای آماری
تهیه جداول و نمودارهای آماری
بدست آوردن توزیعها و رفتار دادههای وارد شده
بدست آوردن دادههای تصادفی
پردازش انواع رگرسیون
محاسبه انواع آزمونهای آماری
انجام تحلیل واریانسهای یک طرفه، دو طرفه و چند طرفه
ایجاد طرحهای آماری
نرم افزار آماری SPSS برای افرادی که قصد ورود به حوزه علم داده را دارند هم مناسب است؛ چرا که ساخت مدلهای توصیفی، پیش بینانه، استقرار مدلهای مبتنی بر یادگیری ماشین و آمار جز وظایف یک متخصص علم داده است.
میتوان گفت SPSS علاوه بر کاربرد فراوان در حوزههای آماری، تحلیلی و علم داده و استفاده آسان و وجود طیف وسیعی از امکانات در منوی نرم افزار SPSS عاملی برای محبوبیت آن در بین سایر نرم افزارهای آماری شده است،
البته جامع بودن خروجیها، راحتی تبدیل خروجی به فرمتهای دیگر از دیگر مزیتهای این نرم افزار آماری است.
در حال حاضر نسخههای 22 و26 از نرم افزار SPSS قابل نصب در کامپیوتر با ویندوز 10 است؛
در ادامه با نحوه کار کردن با SPSS و پستی و بلندیهای آن و همچنین کاربرد آن در حوزههای مختلف بیشتر آشنا می شویم.
اجزای اصلی و مهم در SPS
هنگام ورود به صفحه اصلی SPSS با صفحه گسترده Data Editor مواجه میشوید که در بالا و پایین این دو نوار وجود دارد؛ نوار بالای صفحه ابزارهای مختلف برای انجام دستورهای مختلف بر طبق نیاز است
و نوار پایین با داشتن دو گزینه Variable View و Data View محل ویرایش و وارد کردن اطلاعات است پرسشنامه در SPSS است.
نوار ابزار که در بالای صفحه قرار دارد، دارای 10 منوی اصلی برای تحلیل پرسشنامه است؛
این منوها عبارتند از: منوی فایل، منوی ویرایش، منوی نمایش، منوی دادهها، منوی تبدیل و انتقال، منوی آنالیز، منوی نمودارها و گرافها، منوی امکانات، منوی ویندو و منوی کمک میباشد هر کدام از این منوها بر حسب نیاز کاربردهای مخصوص خودشان را دارند که در ادامه به آنها اشاره خواهیم کرد.
آشنایی با منو نرم افزار spss
هنگام شروع کار با نرمافزار spss با دو بار کلیک بر روی برنامه آن را باز کنید. در بالای صفحه یک نوار ابزار دیده میشود که به عنوان منوی این نرم افزار معرفی میشود. این منو شامل چند بخش است که در ادامه معرفی شدهاند:
– منوی File
این منو خود شامل چند گزینه میشود. گزینه اول مربوط به بخشی است که شما میتوانيد به پرونده های از قبل ساخته شده دسترسی داشته باشید.
این گزینه همان Open است. گزینه New نیز به شما در ایجاد یک فایل و پرونده جدید جهت آنالیز و تحلیل کمک میکند. گزینه های save و save as هم برای ذخیره فایلها به شما کمک میکنند.
با استفاده از گزینه save as میتوانید نوع خروجی خود را تعیین کنید. گزینه دیگر در این منو گزینه print است که با آن میتوانيد خروجی کار خود را چاپ کنید. علاوه بر اینها گزینه Exit نیز جهت خروج از نرم افزار قرار داده شده است.
– منوی Edit
در منوی Edit برای پاک کردن نوشتهها گزینه clear را انتخاب کنید. حذف پروندهها نیز با کمک گزینه Delete ممکن شده است.
در این منو گزینههای دیگری نیز قرار داده شدهاند که برای کپی کردن و الصاق سند در محلی دیگر به کار میروند. این گزینهها Copy، Cut و Paste در منوی Edit نرم افزار spss هستند.
– منوی View
در ادامه spss چیست، باید گزینههای مختلف این منو را بررسی کنید. از طریق گزینههای آن نمایش حالتهای پنجره های نرم افزار را انتخاب میکنید.
همچنین اگر بخواهید قسمتی از نرم افزار مانند tollbar برای شما نشان داده شود یا مخفی شود، کافی است تیک کنار هر گزینه را فعال کنید.
– منوی Data
در این منو میتوانید با کمک از گزینهها متغیرها را شخصی سازی کنید. برای مثال با استفاده از گزینه Define variable properties میتوان ویژگیهای متغیرها را تعریف کرد.
بهعلاوه با کمک گزینه Sort است که متغیر های تعریف شده، متناسب با الگوریتم های خود مرتب سازی میشوند. برای ترکیب فايل های متنوع ساخته شده در spss ، گزینه Merge Files را انتخاب کنید.
همچنین انتخاب گزینه Weigth cases باعث وزن دادن به مورد یا کیس ها میشود.
– منوی Transform
با کمک منوی Transform است که میتوان متغیر جدید تعریف شده را با استفاده از متغیر های قدیمی و توابع ریاضی محاسبه کرد.
در این منو برای محاسبه متغیر جدید با استفاده از توابع ریاضی باید گزینه Compute انتخاب شود. با استفاده از گزینه Recode کار کد گذاری دوباره داده را انجام دهید.
بهعلاوه برای جایگزین کردن مقادیر جدید به جای مقادیر داده هایی که گم شده اند از گزینه Replace Missing Values استفاده کنید.
– منوی Analyze
منوی Analyze دیگر مبحث spss چیست، میباشد. این منو در واقع قلب نرم افزار به حساب میآید که کار اصلی در این نرم افزار را برعهده دارد.
با کمک از آزمونهای آماری و ریاضی طراحی شده در این منو است که فرضیه های مطرح شده در حین بررسی رد و یا تثبیت میشوند.
– منوی Direct Marketing
کسانی که بخش بازاریابی و بیزینس فعالیت دارند به یادگیری این بخش از منو احتیاج پیدا میکنند. زیرا در پیشرفت به آنها کمک خواهد کرد.
– منوی Graphs
تحلیل هایی که به نمودار احتیاج دارند و یا زمانی که به ویرایش نمودارهای خود نیاز است، منوی Graphs به کمک شما میآید. در این قسمت با گزینه Compare Subgroups میتوان گروه های ساخته شده در این برنامه را با هم مقایسه و مورد بررسی قرار داد.
– منوی Utilities
هر آنچه را که مربوط به استخراج متغیرهاست و از آن ها برای پیشبرد کار استفاده میکنید، در این منو طراحی شدهاند.
چگونه اطلاعات پرسشنامهها را در SPSS وارد کنیم؟
برای وارد کردن اطلاعات پرسشنامهها در نرم افزار SPSS هر یک از پرسش نامهها به عنوان یک نمونه و اطلاعات داخل آن متغیرهایی هستند که هر کدام دارای ماهیتهای متفاوتی است، بعد از باز کردن نرم افزار SPSS با صفحه گستردهای رو به رو میشویم که برای وارد کردن اطلاعات پرسشنامه باید از نوار پایین صفحه قسمت Variable View را انتخاب کرده و شروع به وارد کردن متغیرها شده و با توجه به هدف خواسته شده ماهیت متغیرها را تعیین کنیم.
بعد از وارد کردن متغیرها و اطلاعاتشان، از نوار پایین صفحه گزینه Data View را انتخاب میکنیم، در این صفحه تمام متغیرهای وارد شده در نرم افزار SPSS نشان داده میشود به این صورت که هر ستون از آن مربوط به یک متغیر بوده و هر سطر بیانگر پاسخ شرکت کنندگان در پرسشنامه است؛ باید متذکر شویم که هرگونه اشتباه در وارد کردن اطلاعات در صفحه Variable View باعث میشود در ادامه فرآیند در صفحه Data View هم با مشکل مواجه شوید.
چگونه فایلها را در نرم افزار SPSS مرتب کنیم؟
یک فایل را که حاوی داده است میتوان برحسب نوع متغیرهای آن مرتب کرد؛ برای این کار باید از منو Data گزینه Sort انتخاب شود، پس از انتخاب این دستور در پنجره باز شده از فهرست متغیرهای موجود که در سمت چپ جعبه قرار دارد میتوان متغیر یا متغیرهایی را برای مرتب کردن انتخاب کرد؛ در این حالت متغیرهای موجود در فایل بر اساس متغیر یا متغیرهای انتخاب شده مرتب میشوند. این مرتب کردن میتواند به صورت افزایشی (Ascending) یا کاهشی (Descending) باشد.
متغیرها در نرم افزار آماری SPSS چگونه باید نامگذاری شوند؟
نکاتی باید در نامگذاری متغیرها در نرم افزار SPSS مورد توجه قرار بگیرد، بطور مثال: حتما نام متغیرها باید با حروف شروع شود چون در غیر این صورت برای نرم افزار شناخته شده نخواهد بود، حداکثر نام انتخابی برای هر متغیر باید 64 کاراکتر باشد، هرگز از فاصله در نوشتن نام استفاده نکنید.
میتوانید برای نامگذاری از ترکیب حروف و عدد هم استفاده کنید، در انتهای نامگذاری استفاده از (.) و (_) غیر مجاز است در صورتی که در برچسب میتوانید استفاده کنید، اسامی غیر مجاز مانند All, And, Bye را در نامگذاری به کار نبرید همچنین به یاد داشته باشید که در نامگذاری متغیر حتما از لاتین و در برچسب گذاری از فارسی استفاده کنید.
ادغام متغیرها در SPSS
Add Variable یا ادغام متغیرها در نرم افزار آماری SPSS برای یکی کردن دو فایل در کنار یا زیر یکدیگر انجام میشود که این کار اغلب برای مقایسه کردن دو فایل استفاده میشود؛ نکته ی مهم این جا است که برای ادغام کردن متغیرها باید ماهیت آن ها از یک نوع باشد همچنین نام متغیرها هم نباید یکی باشد، برای این کار باید از نوار بالای صفحه نرم افزار SPSS گزینهی Data را انتخاب کنید سپس از پنجره باز شده بخش Merge File را کلیک کنید.
توجه داشته باشد در ادامه دو گزینه پیش رو دارید که یکی برای ادغام کردن فایلها یا به نوعی نمونه است و دیگری برای ادغام کردن متغیرها استفاده میشود. برای ادامه ی این روند میبایست فایل یا متغیر مورد نظر خود از محل ذخیرهسازی آن انتخاب کنید. فرایند ادغام متغیرها معمولا در مواقعی که محقق با حجم بالایی از داده رو به رو است و تعداد محققین در روند کار زیاد است از دستهبندی و ادغام متغیرها برای تجزیه و تحلیل بهتر استفاده میکنند.
برای انجام تحلیلهای آماری با استفاده از نرم افزار آماری SPSS می توان به جدولهای فراوانی، نمودارهای آماری و مقایسهای و مقایسه شاخصها دست پیدا کرد؛ بدست آوردن قابلیت اطمینان پرسشنامهها، آزمونهای پارامتری مرتبط به میانگین جامعه، سنجش همبستگی بین متغیرها رگرسیون، اکتشاف و خوشه بندی از جمله فرآیندیهایی است که در تحلیل آماری پایان نامه با استفاده از نرم افزار SPSS انجام میشود.
برای انجام هرکدام از آنها با وارد کردن دادههای مورد نظر و انتخاب گزینههای صحیح صورت میگیرد؛ بطور مثال برای تحلیل عاملی اکتشاف با انتخاب Analyze از نوار بالای صفحه نرم افزار در پنجره باز شده گزینهی Descriptive Statistics و سپس Explore را انتخاب میکنیم، این فرآیند برای دادههای کمی که از طرحهای مستقل جمع آوری شدهاند کاربرد دارد.
همچنین این دستور امکان توصیف دادهها به تفکیک گروههای مختلف را فراهم میکند. خلاصه این تحلیلها با استفاده از ابزاری مانند Plot ها و میانگین و فاصلههای تعیین شده بدست میآیند که در نهایت خروجی تحلیل آماری از پرسشنامه را در قالب جدول فراوانی و Plot نمایش میدهد.
چگونه در SPSS خروجی بگیریم؟
بعد از اینکه دستور مورد نظر در SPSS انجام شد، نتایج حاصل در پنجره ای به نام Output view نشان داده میشود؛ این نمایش شامل نتایج و تحلیل تمام دستورات خواسته شده از SPSS است که به صورت جدولهای فراوانی و انواع نمودارها مشخص میشود، در صورت نیاز میتوان از طریق منوی File گزینه Print را برای چاپ فیزیکی نتایج استفاده کرد.
گاهی اوقات برای استفاده از نتایج تحلیلها در نرم افزار آماری SPSS می توان برای تفسیر این خروجیها آنها را نرم افزارهای دیگر مثل Word یا Excel انتقال داد؛ یکی از ساده ترین روشها برای انتقال خروجی در SPSS به Word و Excel استفاده از دستور کپی وPaste است به این صورت که با انتخاب خروجی مورد نظر در پنجره Output و استفاده از کلیک راست یا دکمه Edit دستور Copy Special را انتخاب میکنید.
سپس در برنامه Word یا Excel عملیات Paste را انجام داده یا با استفاده از کلیدهای ترکیبی ctrl+v خروجی در SPSS در محل مورد نظر پیاده میکنید. میتوانید از اطلاعات بدست آمده در خروجی SPSS فایلهای اطلاعاتی بدست آورید که این قابلیت میتواند ورودی برای تحلیلهای بعدی مورد استفاده قرار بگیرد؛ در آینده بیشتر به این موضوع میپردازیم.
می توان گفت امروزه تمام پروژه ها، پایان نامهها و تحقیقها با آمار و ارقام سر و کار دارند به همین دلیل نرم افزار SPSS هم یکی از انتخابهای کارشناسان برای انجام پروژههای آماری خود در حوزههای مختلف است؛ بسیاری از سایتها و افراد هستند که انجام پروژههای آماری در نرم افزار SPSS را برعهده میگیرند اما در این بین باید دقت کرد که چه کسی را برای این کار در نظر میگیرید چرا که با توجه به رشته و گرایش و حوزه کاری استفاده از نرم افزار SPSS هم کاربرد متفاوتی را ارائه میدهد.
نرم افزار SPSS و R
در تجزیه و تحلیلهای آماری نرم افزار SPSS و R استفاده گسترده ای را در اختیار کاربران قرار میدهد؛ البته یادگیری نرم افزار SPSS آسانتر از نرم افزار R است اما خروجی گرفتن در هر دو نرم افزار براحتی انجام میشود، هر چند که هر کدام در حوزهی آماری کاربردهای زیادی دارند اما نرم افزار SPSS را بیشتر به یک نرم افزار آماری و R به عنوان نرم افزاری ایدهآل در حوزه علم داده و برنامه نویسی شهرت دارد.
بهترین نسخه نرم افزار spss کدام است؟
شرکت سازنده spss هر سال و یا هر دو سال یک بار نسخه جدیدی از این نرم افزار را انتشار میکند. نکته مشترک در بین تمام ورژن های این نرم افزار این است که نسخه ها قابلیت جدیدی پیدا کرده و سنگین تر میشوند. تمام نسخه های اصلی spss یک کار اصلی را انجام میدهند و با چند تفاوت جزئی به روز رسانی میشوند.
یادگیری نرم افزار آماری SPSS
اگر بدنبال آموزش و یادگیری نرم افزار SPSS هستید بسیاری از دورهها، ویدیوها و کتابهای آموزشی هستند که میتوانند شما را در فرآیند یادگیری نرم افزار SPSS کمک کنند، اگر به دنبال ویدیوهای آموزشی هستید، سایت مکتب خونه دورههای آموزشی را ارائه داده که میتوانید از آنها استفاده کنید؛ اما اگر بدنبال کتابهای آموزشی هستید کتاب آموزش SPSS نوشته منصور مومنی، مقدمهای بر آمار SPSS در روانشناسی نوشته Dennis Howitt و Duncan Cramer، آموزش جامع SPSS نوشته رضا بهرامی و چندین کتاب دیگر میتوانند کمک کننده شما در این مسیر باشند.
کلام پایانی
دنیای یادگیری نرم افزارها به علت پیشرفت روز به روز تکنولوژی، دنیای وسیع و بیانتهایی است، برای قدم گذاشتن در این دنیا قبل از هر چیزی به دانشی به روز نیاز دارید تا ادامه راه هموارتر شده و به پیشرفت برسید چرا که شروع هرکاری بدون دانش ابتدایی مثل درخت بی ریشه است.
مطالب گفته شده تنها بخشی از نرم افزار SPSS است تا صرفا شما را به یک دید جامع و کلی از این نرم افزار برساند و با کاربردها و جایگاه آن در دنیای نرم افزارها به خصوص نرم افزارهای آماری آشنا کند؛ نرم افزار SPSS رقبای زیادی در حوزه تحلیلهای آماری و داده کاوی دارد مثل:R،Minitab و SAS؛ اما بسته به اینکه هدف چه خواهد بود استفاده نیز متفاوت خواهد شد.
اما نرم افزار SPSS به علت یادگیری آسان و سهولت در کاربرد مورد توجه بسیاری از کاربران قرار می گیرد؛ همانطور که گفته شد این نرم افزار در روش تحقیق، پایان نامه ها و انواع پژوهشهای آماری در رشتههای علوم اجتماعی و روانشناسی، کشاورزی و صنایع مورد استقبال ویژهای قرار میگیرد.
در آخر باید گفت با توجه به وسیع بودن امکانات نرم افزارSPSS و یادگیری آسان آن میشود این نرم افزار را جایگزین دیگر نرم افزارها در امور تحلیل آماری کرد البته اگر فرصت کافی برای یادگیری را نداشته و میخواهید هر چه سریعتر دست به کار شوید.
spss چیست، کاربردهای آن کدامند وجدیدترین نسخه آن کدام است؟
اس پی اس اس یک نرم افزار تحلیلی است که برای انجام تحلیل داده ها به کار می رود.
کاربردهای آن شامل تجزیه و تحلیل آماری، پیش بینی، کاوش داده ه ها و …
spss
از جمله دیگر کاربردهای SPSS می توان به تجزیه و تحلیل آزمایش های طرح تصادفی، طراحی پژوهش،
تحلیل رویکردهای خاص در پژوهش های علمی و تحلیل داده های اقتصادی اشاره کرد.
این نرم افزار قابلیت تحلیل داده های گوناگون از جمله داده های کمی، داده های کیفی و داده های مختلط را داراست.
اس پی اس اس به صورت گسترده در صنایع مختلفی از جمله آموزش، بهداشت، بازاریابی، تحقیقات بازار، جمعیت شناسی و داده کاوی استفاده می شود.
در آموزش، SPSS به عنوان یک ابزار قدرتمند برای تجزیه و تحلیل داده ها، مدیریت داده ها و نمایش داده ها استفاده می شود.
در صنایع بهداشتی، SPSS به عنوان یک ابزار مهم برای تحلیل داده های پزشکی، اپیدمیولوژی و سلامت عمومی استفاده می شود.
در بازاریابی، SPSS به عنوان یک ابزار برای تحلیل داده های بازار و تحلیل رفتار مشتریان استفاده می شود.
در تحقیقات بازار، SPSS به عنوان یک ابزار برای تحلیل داده های تحقیقات بازار و تحلیل رفتار مشتریان استفاده می شود.
در جمعیت شناسی، SPSS به عنوان یک ابزار برای تحلیل داده های جمعیت شناسی، تحلیل توزیع های فراگیر و تحلیل روابط اجتماعی استفاده می شود.
و …
پس یکی از محبوبترین نرمافزارهای آماری است که برای تحلیل دادههای پیچیده استفاده میشود.
ضرورتاً شما هم مانند من، از جملاتی مانند “انجام پایان نامه با SPSS”، “انجام مقاله”، “تهیه پرسشنامه” و “کار آماری”، در سرتاسر اینترنت بسیار شنیده اید.
در این پست، باهم بررسی می کنیم که SPSS در واقع چیست، چه کاربردهایی دارد و بهترین نسخههای آن (ورژن) را با یکدیگر مرور کنیم.
SPSS که مخفف عبارت Statistical Package for the Social Sciences است،
در ابتدا برای تحلیل دادههای اجتماعی توسعه داده شده بود اما امروزه در انواع زیادی از صنایع و حوزههای دیگر نیز مورد استفاده قرار میگیرد.
از جمله قابلیتهای SPSS میتوان به تحلیل رگرسیون، تحلیل عاملی، تحلیل عاملی تأییدی، تحلیل خوشهبندی، تحلیل مولفههای اصلی، تحلیل تجزیه و تحلیل خطی چندگانه اشاره کرد.
بطور خلاصه یک برنامه یا نرم افزار ویندوز است که اطلاعات مختلف (مثلا اطلاعات یک پرسشنامه) را دریافت می کند، تحلیل می کند و جدول و نمودار برای آنها تهیه می کند.
spss یه برنامهی ویندوزی هست که مثل یه دکتر مغز و اعصاب، اطلاعات پرسشنامهها رو تحلیل میکنه و به اونا تزریق میکنه
تا جدول و نمودار واسه اونها بسازه. بعد با این اطلاعات میتونید به راحتی زندگیتون رو بهبود ببخشید، چیزی که دکتر مغز و اعصاب نمیتونه بهتون بده. 😉
خستین نسخهٔ این نرمافزار در سال ۱۹۶۸ پس از تأسیس «نرمن نی» منتشر شد،
که سپس به یک کارشناس ارشد علوم سیاسی در در دانشگاه استانفورد، و اکنون استاد محقق در دانشکدهٔ علوم سیاسی دانشگاه استانفورد و استاد بازنشستهٔ علوم سیاسی در دانشگاه شیکاگو بوده است.
کمپانی سازنده ی این نرم افزار در ۲۸ جولای ۲۰۰۹ توسط شرکت IBM خریداری شد
و شرکت IBM نام جدید PASW را بر آن نهاد که مخفف Predictive Analytics SoftWare بود.
به شکلی عجیب اما دوباره در نسخه ۱۹ شرکت IBM تصمیم گرفت نام SPSS Statistics را برای ان انتخاب کند.
نخستین نسخهٔ این نرمافزار در سال ۱۹۶۸ پس از تأسیس «نرمن نی» منتشر شد،
که سپس به یک کارشناس ارشد علوم سیاسی در در دانشگاه استانفورد،
و اکنون استاد محقق در دانشکدهٔ علوم سیاسی دانشگاه استانفورد و استاد بازنشستهٔ علوم سیاسی در دانشگاه شیکاگو بوده است.
کمپانی سازنده ی این نرم افزار در ۲۸ جولای ۲۰۰۹ توسط شرکت IBM خریداری شد و شرکت IBM نام جدید PASW را بر آن نهاد که مخفف Predictive Analytics SoftWare بود.
به شکلی عجیب اما دوباره در نسخه ۱۹ شرکت IBM تصمیم گرفت نام SPSS Statistics را برای ان انتخاب کند.
معرفی آخرین ورژن ها و بهترین ورژن اس پی اس اس
شرکت آی بی ام تقریبا هر ساله یا هر دوسال یک بار اقدام به انتشار یک نسخه جدید از اس پی اس اس می کند.
نکته مشترک در اکثر نسخه ها این است که با جدیدتر شدن ورژن، نرم افزار قابلیت های جدیدی پیدا می کند اما سنگین تر می شود.
تمام ورژن های اس پی اس اس همان کار اصلی را انجام می دهند با تفاوت های جزئی و نه چندان ملموس که در هر نسخه جدید اضافه می شود.
تجربه چندین ساله بنده به همراه چند جستجوی ساده در وب سایت های خارجی به شما می گوید که در حال حاضر بهترین ورژن اس پی اس اس همان نسخه 26 است.
در حال حاضر جدیدترین ورژن اس پی اس اس همان نسخه 2023 یا spss 29 است
از جمله امکانات اضافه شده به آن، هوشمندتر شدن در زمینه ایمپورت یا وارد کردن اطلاعات اولیه به نرم افزار است.
از اینجا می توانید نسخه Spss29 را تهیه کنید و از آن لذت ببرید!
با ما همراه باشید
آموزش ها ادامه دارد
راستی این مقاله چصور بود؟ نظرتان را در زیر بنویسید و ما را دلگرم کنید!
نرم افزار لیزرل و انجام مدلسازی معادلات ساختاری با آن
1- مدل معادلات ساختاری چیست؟
مدل يابي معادلات ساختاري (Structural equation modeling: SEM) يک تکنيک تحليل چند متغيري بسيار کلي و نيرومند از خانواده رگرسيون چند متغيري و به بيان دقيقتر بسط “مدل خطي کلي” (General linear model) یا GLM است. SEM به پژوهشگر امکان ميدهد مجموعه اي از معادلات رگرسيون را به صورت هم زمان مورد آزمون قرار دهد.
مدل يابي معادله ساختاري يک رويکرد جامع براي آزمون فرضيههايي درباره روابط متغيرهاي مشاهده شده و مکنون است که گاه تحليل ساختاري کوواريانس، مدل يابي علّي و گاه نيز ليزرل (Lisrel) ناميده شده است اما اصطلاح غالب در اين روزها، مدل يابي معادله ساختاري يا به گونه خلاصه SEM است. (هومن 1384،11)
از نظر آذر (1381) نيز يکي از قويترين و مناسبترين روشهاي تجزيه و تحليل در تحقيقات علوم رفتاري و اجتماعي، تجزيه و تحليل چند متغيره است زيرا اين گونه موضوعات چند متغيره بوده و نمي توان آنها را با شيوه دو متغيري (که هر بار يک متغير مستقل با يک متغير وابسته در نظر گرفته ميشود) حل نمود.
«تجزيه و تحليل ساختارهاي کوواريانس» يا همان «مدل يابي معادلات ساختاري»، يکي از اصليترين روشهاي تجزيه و تحليل ساختار دادههاي پيچيده و يکي از روشهاي نو براي بررسي روابط علت و معلولي است و به معني تجزيه و تحليل متغيرهاي مختلفي است که در يک ساختار مبتني بر تئوري، تاثيرات همزمان متغيرها را به هم نشان ميدهد. از طريق اين روش ميتوان قابل قبول بودن مدلهاي نظري را در جامعههاي خاص با استفاده از دادههاي همبستگي، غير آزمايشي و آزمايشي آزمود.
2- انديشه اساسي و زيربنايی مدل يابي ساختاري
يکي از مفاهيم اساسي که در آمار کاربردي در سطح متوسط وجود دارد اثر انتقالهاي جمع پذير و ضرب پذير در فهرستي از اعداد است. يعني اگر هر يک از اعداد يک فهرست در مقدار ثابت K ضرب شود ميانگين اعداد در همان K ضرب ميشود و به اين ترتيب، انحراف معيار استاندارد در مقدار قدر مطلق K ضرب خواهد شد.
نکته اين است که اگر مجموعه اي از اعداد X با مجموعه ديگري از اعداد Y از طريق معادله Y=4X مرتبط باشند در اين صورت واريانس Y بايد 16 برابر واريانس X باشد و بنابراين از طريق مقايسه واريانسهاي X و Y ميتوانيد به گونه غير مستقيم اين فرضيه را که Y و X از طريق معادله Y=4X با هم مرتبط هستند را بيازماييد.
اين انديشه از طريق تعدادي معادلات خطي از راههاي مختلف به چندين متغير مرتبط با هم تعميم داده ميشود. هرچند قواعد آن پيچيدهتر و محاسبات دشوارتر ميشود، اما پيام کلي ثابت ميماند. يعني با بررسي واريانسها و کوواريانسهاي متغيرها ميتوانيد اين فرضيه را که “متغيرها از طريق مجموعه اي از روابط خطي با هم مرتبط اند” را بيازماييد.
توسعه مدلهاي علّي و همگرايي روشهاي اقتصادسنجي، روان سنجي و غیره
توسعه مدلهاي علّي متغيرهاي مکنون معرف همگرايي سنتهاي پژوهشي نسبتا مستقل در روان سنجي، اقتصادسنجي، زيست شناسي و بسياري از روشهاي قبلا آشناست که آنها را به شکل چهارچوبي وسيع در ميآورد. مفاهيم متغيرهاي مکنون (Latent variables) در مقابل متغيرهاي مشاهده شده (Observed variables) و خطا در متغيرها، تاريخي طولاني دارد.
در اقتصادسنجي آثار جهت دار هم زمان چند متغير بر متغيرهاي ديگر، تحت برچسب مدلهاي معادله همزمان بسيار مورد مطالعه قرار گرفته است. در روان سنجي به عنوان تحليل عاملي و تئوري اعتبار توسعه يافته و شالوده اساسي بسياري از پژوهشهاي اندازه گيري در روانسنجي ميباشد. در زيست شناسي، يک سنت مشابه همواره با مدلهاي معادلات همزمان (گاه با متغيرهاي مکنون) در زمينه نمايش و طرح برآورده در تحليل مسير سر و کار دارد.
3- موارد کاربرد روش ليزرل
روش ليزرل ضمن آنکه ضرايب مجهول مجموعه معادلات ساختاري خطي را برآورد ميکند براي برازش مدلهايي که شامل متغيرهاي مکنون، خطاهاي اندازه گيري در هر يک از متغيرهاي وابسته و مستقل، عليت دو سويه، هم زماني و وابستگي متقابل ميباشد طرح ريزي گرديده است.
اما اين روش را ميتوان به عنوان موارد خاصي براي روشهاي تحليل عاملي تاييدي، تحليل رگرسيون چند متغيري، تحليل مسير، مدلهاي اقتصادي خاص دادههاي وابسته به زمان، مدلهاي برگشت پذير و برگشت ناپذير براي دادههاي مقطعي/ طولي، مدلهاي ساختاري کوواريانس و تحليل چند نمونه اي (مانند آزمون فرضيههاي برابري ماتريس کوواريانس هاي، برابري ماتريس همبستگي ها، برابري معادلات و ساختارهاي عاملي و غيره) نيز به کار برد.
4- نرم افزار ليزرل چیست؟
ليزرل يک محصول نرم افزاري است که به منظور برآورد و آزمون مدلهاي معادلات ساختاري طراحي و از سوي “شرکت بين المللي نرم افزار علمي”
Scientific software international (www.ssicentral.com)
به بازار عرضه شده است. اين نرم افزار با استفاده از همبستگي و کوواريانس اندازه گيري شده، ميتواند مقادير بارهاي عاملي، واريانسها و خطاهاي متغيرهاي مکنون را برآورد يا استنباط کند و از آن ميتوان براي اجراي تحليل عاملي اکتشافي، تحليل عاملي مرتبه دوم، تحليل عاملي تاييدي و همچنين تحليل مسير (مدل يابي علت و معلولي با متغيرهاي مکنون) استفاده کرد.
تحلیل ساختاری کوواریانس که به آن روابط خطی ساختاری نیز می گویند، یکی از تکنیک های تحلیل مدل معادلات ساختاری است. جالب است بدانید که نام LISREL از عبارت
Linear Structural Relations
که به معنای روابط خطی ساختاری است، بدست آمده است.
5- تحليل عاملي اکتشافي (efa) و تحليل عاملي تاييدي (cfa)
تحليل عاملي ميتواند دو صورت اکتشافي و تاييدي داشته باشد. اينکه کدام يک از اين دو روش بايد در تحليل عاملي به کار رود مبتني بر هدف تحليل داده هاست.
تحليل عاملی اکتشافي
در تحليل عاملی اکتشافي(Exploratory factor analysis) پژوهشگر به دنبال بررسي دادههاي تجربي به منظور کشف و شناسايي شاخصها و نيز روابط بين آنهاست و اين کار را بدون تحميل هر گونه مدل معيني انجام ميدهد. به بيان ديگر تحليل عاملی اکتشافي علاوه بر آنکه ارزش تجسسي يا پيشنهادي دارد ميتواند ساختارساز، مدل ساز يا فرضيه ساز باشد.
تحليل اکتشافي وقتي به کار ميرود که پژوهشگر شواهد کافي قبلي و پيش تجربي براي تشکيل فرضيه درباره تعداد عاملهاي زيربنايي دادهها نداشته و به واقع مايل باشد درباره تعيين تعداد يا ماهيت عاملهايي که همپراشي بين متغيرها را توجيه ميکنند دادهها را بکاود. بنابر اين تحليل عاملی اکتشافي بيشتر به عنوان يک روش تدوين و توليد تئوري و نه يک روش آزمون تئوري در نظر گرفته ميشود.
تحليل عاملي اکتشافي روشي است که اغلب براي کشف و اندازه گيري منابع مکنون پراش و همپراش در اندازه گيريهاي مشاهده شده به کار ميرود. پژوهشگران به اين واقعيت پي برده اند که تحليل عاملي اکتشافي ميتواند در مراحل اوليه تجربه يا پرورش تستها کاملا مفيد باشد. توانشهاي ذهني نخستين ترستون، ساختار هوش گيلفورد نمونههاي خوبي براي اين مطلب ميباشد. اما هر چه دانش بيشتري درباره طبيعت اندازه گيريهاي رواني و اجتماعي به دست آيد ممکن است کمتر به عنوان يک ابزار مفيد به کار رود و حتي ممکن است بازدارنده نيز باشد.
از سوي ديگر بيشتر مطالعات ممکن است تا حدي هم اکتشافي و هم تاييدي باشند زيرا شامل متغير معلوم و تعدادي متغير مجهولاند. متغيرهاي معلوم را بايد با دقت زيادي انتخاب کرد تا حتي الامکان درباره متغيرهاي نامعلومي که استخراج ميشود اطلاعات بيشتري فراهمايد. مطلوب آن است که فرضيه اي که از طريق روشهاي تحليل اکتشافي تدوين ميشود از طريق قرار گرفتن در معرض روشهاي آماري دقيقتر تاييد يا رد شود. تحليل عاملی اکتشافي نيازمند نمونههايي با حجم بسيار زياد ميباشد.
تحليل عاملي تاييدي
در تحليل عاملي تاييدي (Confirmatory factor analysis) ، پژوهشگر به دنبال تهيه مدلي است که فرض ميشود دادههاي تجربي را بر پايه چند پارامتر نسبتا اندک، توصيف تبيين يا توجيه ميکند. اين مدل مبتني بر اطلاعات پيش تجربي درباره ساختار داده هاست که ميتواند به شکل:
1) يک تئوري يا فرضيه
2) يک طرح طبقه بندي کننده معين براي گويهها يا پاره تستها در انطباق با ويژگيهاي عيني شکل و محتوا
3)شرايط معلوم تجربي
و يا 4) دانش حاصل از مطالعات قبلي درباره دادههاي وسيع باشد.
تمايز مهم روشهاي تحليل اکتشافي و تاييدي در اين است که روش اکتشافي با صرفهترين روش تبيين واريانس مشترک زيربنايي يک ماتريس همبستگي را مشخص ميکند. در حالي که روشهاي تاييدي (آزمون فرضيه) تعيين ميکنند که دادهها با يک ساختار عاملي معين (که در فرضيه آمده) هماهنگ اند يا نه.
ضمنا خاطر نشان می شود برای دریافت ویدئوی آموزشی تحلیل عاملی تاییدی در نرم افزار لیزرل می توانید به این صفحه مراجعه نمایید:
6- آزمونهاي برازندگي مدل کلي
با آنکه انواع گوناگون آزمونها که به گونه کلي شاخصهاي برازندگي(Fitting indexes) ناميده ميشوند پيوسته در حال مقايسه، توسعه و تکامل ميباشند اما هنوز درباره حتي يک آزمون بهينه نيز توافق همگاني وجود ندارد. نتيجه آن است که مقالههاي مختلف، شاخصهاي مختلفي را ارائه کرده اند و حتي نگارشهاي مشهور برنامههاي SEM مانند نرم افزارهاي lisrel, Amos, EQS نيز تعداد زيادي از شاخصهاي برازندگي به دست ميدهند.(هومن1384 ،235)
اين شاخصها به شيوههاي مختلفي طبقه بندي شده اند که يکي از عمدهترين آنها طبقه بندي به صورت مطلق، نسبي و تعديل يافته ميباشد. برخي از اين شاخص ها عبارتند از:
1-6- شاخصهاي GFI و AGFI
شاخص GFI – Goodness of fit index مقدار نسبي واريانسها و کوواريانسها را به گونه مشترک از طريق مدل ارزيابي ميکند. دامنه تغييرات GFI بين صفر و يک ميباشد. مقدار GFI بايد برابر يا بزرگتر از 0.09 باشد.
شاخص برازندگي ديگر Adjusted Goodness of Fit Index – AGFI يا همان مقدار تعديل يافته شاخص GFI براي درجه آزادي ميباشد. اين مشخصه معادل با کاربرد ميانگين مجذورات به جاي مجموع مجذورات در صورت و مخرج (1- GFI) است. مقدار اين شاخص نيز بين صفر و يک ميباشد. شاخصهاي GFI و AGFI را که جارزکاگ و سوربوم (1989) پيشنهاد کرده اند بستگي به حجم نمونه ندارد.
2-6- شاخص RMSEA
اين شاخص , ريشه ميانگين مجذورات تقريب ميباشد.
شاخص Root Mean Square Error of Approximation – RMSEA براي مدلهاي خوب برابر 0.05 يا کمتر است. مدلهايي که RMSEA آنها 0.1 باشد برازش ضعيفي دارند.
3-6- مجذور کاي
آزمون مجذور كاي (خي دو) اين فرضيه را مدل مورد نظر هماهنگ با الگوي همپراشي بين متغيرهاي مشاهده شده است را ميآزمايد، کميت خي دو بسيار به حجم نمونه وابسته ميباشد و نمونه بزرگ کميت خي دو را بيش از آنچه که بتوان آن را به غلط بودن مدل نسبت داد, افزايش ميدهد. (هومن.1384. 422).
4-6- شاخص NFI و CFI
شاخصNFI (که شاخص بنتلر-بونت هم ناميده ميشود) براي مقادير بالاي 0.09 قابل قبول و نشانه برازندگي مدل است. شاخص CFI بزرگتر از 0.09 قابل قبول و نشانه برازندگي مدل است. اين شاخص از طريق مقايسه يک مدل به اصطلاح مستقل که در آن بين متغيرها هيچ رابطه اي نيست با مدل پيشنهادي مورد نظر، مقدار بهبود را نيز ميآزمايد. شاخص CFI از لحاظ معنا مانند NFI است با اين تفاوت که براي حجم گروه نمونه جريمه ميدهد.
شاخصهاي ديگري نيز در خروجي نرم افزار ليزرل ديده ميشوند که برخي مثل AIC, CAIC ECVA براي تعيين برازندهترين مدل از ميان چند مدل مورد توجه قرار ميگيرند.
براي مثال مدلي که داراي کوچکترين AIC ,CAIC ,ECVA باشد برازندهتر است.(هومن1384 ،244-235) برخي از شاخصها نيز به شدت وابسته به حجم نمونه اند و در حجم نمونههاي بالا ميتوانند معنا داشته باشند.
برگرفته از سایت اطمینان شرق
برای مشاهده لیست همه ی پرسشنامه های استاندارد لطفا همین جا روی پرسشنامه استاندارد کلیک فرمایید.
در این مقاله در خصوص الگوهای معادله ساختاری، تدوین مدل، تشخیص مدل، برآورد مدل، آزمون مدل و اصلاح مدل معادلات ساختاری گفتگو می کنیم.
الگوهای معادله ساختاری
الگوهای معادله ساختاری، مجموعه هایی از معادلات خطی هستند که برای تعیین یک پدیده برحسب متغیرهای علت و معلول از پیش فرض شده به کار می روند. کلی ترین شکل این الگوها امکان اندازه گیری متغیرهایی که نمی توانند مستقیماً اندازه گیری شوند را فراهم می کند. الگوهای معادله ساختاری به ویژه در علوم اجتماعی و رفتاری مفیدند و برای مطالعه رابطه بین وضعیت های اجتماعی و حصول آن ها، تصمیم های مربوط به قابلیت سوددهی شرکت ها، کارایی برنامه های رفتار اجتماعی و دیگر مکانیسم ها مورد استفاده قرار می گیرد.
تدوین مدل
قبل از هر نوع جمع آوری داده و تحلیل، پژوهشگر بایستی مدلی را تدوین نماید که به نظر می رسد مقادیر واریانس- کواریانس آن را تأیید نمایند. به بیان دیگر تدوین مدل تصمیم در این باره است که کدام متغیرها در مدل نظری قرار گیرند و این که این متغیرها چگونه با هم در ارتباط هستند.
یک مدل هنگامی به خوبی تدوین شده است که مدل واقعی جامعه با مدل نظری فرض شده سازگار باشد. به عبارت دیگر ماتریس کواریانس نمونه ای S به طور بسنده ای بوسیله مدل نظری تحت آزمون بازتولید شود. بنابراین هدف تحقق مدلی است که نزدیکترین برازش را با ساختار کواریانس مدل دارا باشد. مثال ساده ای را با دو متغیر X و Y در نظر بگیرید. ما براساس پژوهش قبلی می دانیم که این دو متغیر با یکدیگر ارتباط دارند. اما چرا؟ کدام ارتباط نظری بیانگر این رابطه است؟ آیا X بر Y اثر می گذارد یا عکس این حالت برقرار می باشد و یا متغیر سومی به نام Z بر هردوی آن ها اثر می گذارد. گاه ممکن است با در نظر مدل اولیه نامناسب باعث شویم یک پارامتر با اهمیت از مدل حذف شود (مثلا غفلت کردن از وجود رابطه X و Y) و یا این که یک متغیر مهم را از مدل حذف نماییم. علاوه بر این ممکن است یک پارامتر یا متغیر نامناسب در مدل وارد شوند که سبب ایجاد اریبی در برآورد پارامترها شده و نوعی خطا را در تدوین مدل بوجود می آورد.
تشخیص مدل
در مدل سازی معادلات ساختاری حل مسئله تشخیص مدل پیش از برآورد پارامترها بسیار با اهمیت است. در تشخیص مدل این سؤال مطرح می شود که : آیا براساس داده های نمونه ای موجود در ماتریس کواریانس نمونه ای S و مدل نظری تعریف شده بوسیله ماتریس کواریانس جامعه ∑ می توان مجموعه ی منحصر به فردی از برآورد پارامترها یافت؟
پیش از توضیح در مورد تشخیص مدل، توضیحاتی را در مورد پارامترهای مدل ارائه می دهیم .هر پارامتر در مدل باید به عنوان یک پارامتر آزاد، ثابت یا مقید مشخص شود. یک پارامتر آزاد پارامتری است که شناخته شده نیست و نیازمند برآورد است. پارامتر ثابت، پارامتری است که آزاد نیست اما برای آن یک مقدار مشخص(به طور معمول مقدار صفر یا 1) تعریف شده است. یک پارامتر مقید نیز پارامتری است که مشخص نیست اما برابر با یک یا تعداد بیشتری پارامتر است.
تشخیص مدل در واقع به طرح پارامترها به عنوان ثابت، آزاد یا مقید بستگی دارد. پس از آن که مدل و پارامترها تدوین شدند، این پارامترها برای برای شکل دادن به یک و تنها یک ∑ با یکدیگر ترکیب می شوند. اگر دو یا تعداد بیشتری از مجموعه پارامترها ماتریس ∑ یکسانی را تولید کنند، انگاه این مجموعه ها معادل یا همتا خوانده می شوند.
بر این اساس سه سطح برای تشخیص مدل وجود دارد:
1- یک مدل فرومشخص است اگر یک یا تعداد بیشتری از متغیرها نتوانند به طور یکتایی مشخص شوند زیرا اطلاعات کافی در ماتریس S وجود ندارد.
2- یک مدل کاملا مشخص است اگر همه پارامترها به دلیل وجود اطلاعات کافی در ماتریس S به طور منحصر به فردی تعیین شوند..
3- یک مدل فرامشخص است هنگامی که بیش از یک جواب برای یک یا چند پارامتر وجود دارد.
اگر مدل فرومشخص باشد برآورد پارامترها قابل اعتماد نبوده و در چنین حالتی درجات آزادی مدل صفر یا منفی است. این مدل ممکن است با افزودن قیدهایی مشخص شود. مدل های کاملا مشخص و فرامشخص برای برآورد پارامترها مناسب هستند.
برآورد مدل
گام بعدی بدست آوردن برآوردهایی برای هریک از پارامترهای تعیین شده در مدل است که ماتریس نظری ∑ را تولید می کنند. برآورد پارامترها باید به گونه ای باشد که نزدیک ترین ماتریس به ماتریس واریانس کواریانس نمونه ای بازتولید شود و خطا یعنی ∑-S حداقل شود.
برخی از روش های اولیه برای این منظور شامل حداقل مربعات غیروزنی، حداقل مربعات معمول، حداقل مربعات تعمیم یافته و روش حداکثر درستنمایی است. از میان این روش ها تنها روش حداقل مربعات غیروزنی وابسته به مقیاس است.
آزمون مدل
پس از آنکه برآورد پارامترها برای یک مدل تدوین شده و مشخص بدست آمدند، محقق باید تعیين کند که داده ها تا چه حد با مدل برازش دارند؟
دو شیوه برای برسی برازش مدل وجود دارد : ابتدا ملاحظه برخی آزمون های عمومیت یافته برای برازش کل مدل است و شیوه دوم بررسی برازش پارامترهای منفرد در هریک از اجزای مدل است. آزمو های کلی با عنوان معیارهای برازش مدل شناخته می شوند. بسیاری از این شاخص ها برمبنای مقایسه ماتریس کواریانس اقتباس شده از مدل ∑ با ماتریس کواریانس نمونه ای S ساخته شده اند.
برای بررسی برازش پارامترهای منفرد سه آزمون اصلی مورد استفاده قرار می گیرند:
اول آنکه آیا یک پارامتر آزاد به طور معناداری با صفر تفاوت دارد یا خیر؟
دوم آنکه آیا علامت پاارمتر با آنچه به لحاظ نظری مورد انتظار بوده هماهنگ است؟
و سوم اینکه برآورد پارامترها باید در دامنه مقادیر مورد انتظار قرارگیرند.
هریک از این سؤالات با کمک روش ها و آزمون های آماری مناسب پاسخ داده می شوند.
اصلاح مدل
اگر برازش یک مدل نظری به قوتی که انتظار داشتیم نبود آنگاه گام بعدی اصلاح مدل و ارزیابی مدل اصلاح شده می باشد. فرآیند نمایان سازی خطاهای تدوین مدل به نحوی که مدل های جایگزین تدوین شده به طور مناسب تری ارزیابی شوند ، «جستجوی تدوین» نامیده می شود. هدف از یک جستجوی تدوین تعویض مدل اصلی با مدلی است که در برخی جهات دارای برازش بهتری بوده و پارامترهایی را برآورد می کند که به لحاظ آماری معنادار و به لحاظ نظری دارای معنا و مفهوم باشند.
بررسی ماتریس باقیمانده ها، ملاحظه معناداری آماری پارامترهای مدل و همچنین استفاده از مضرب لاگرانژ و آماره والد از جمله روش های مورد استفاده برای این منظور هستند.
منبع : مقدمه ای بر مدل سازی معادله ساختاری ، نوشته رندال. ای. شوماخر و ریچارد ای لومکس / ترجمه شده توسط دکتر وحید قاسمی/ انتشارات جامعه شناسان.
برگرفته از سایت اطمینان شرق
برای مشاهده لیست همه ی پرسشنامه های استاندارد لطفا همین جا روی پرسشنامه استاندارد کلیک فرمایید.
در این مقاله به تشریح انواع مدل های معادله ساختاری و کاربرد آنها می پردازیم.
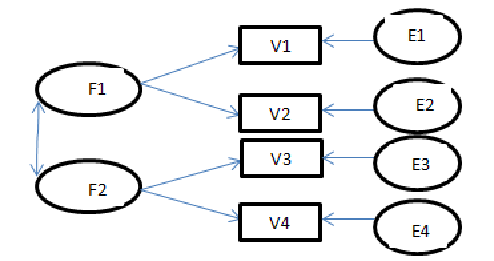
1- مدل های با معرف های چندگانه و علل چندگانه
معرف های چندگانه و علل چندگانه نوع خاصی از مدل های معادله ساختاری را معرفی می کند و به طور مخفف با
MIMIC (Multiple Indicator and Multiple Causes)
نشان داده می شود. مدل های MIMIC شامل کاربرد متغیرهای پنهانی است که بوسیله متغیرهای مشاهده شده پیش بینی می شوند. این موضوع را با مثالی از یورسکوگ و سوربوم (1996) بیان می کنیم که در آن یک متغیر پنهان (مشارکت اجتماعی) بوسیله رفتن به کلیسا، عضویت های گروهی و دیدار دوستان تعریف شده است. همچنین این متغیر بوسیله متغیرهای مشاهده شده درآمد، اشتغال و تحصیلات پیش بینی می شود.
متغیر پنهان مشارکت اجتماعی با پیکان هایی به سه معرف متصل شده است که هرکدام دارای مقداری خطای اندازه گیری هستند. همچنین سه پیکان از متغیرهای مشاده شده به سمت متغیر مشارکت اجتماعی نشانه رفته است. این متغیرهای مشاهده شده با یکدیگر همبستگی دارند. پس از بررسی معناداری متغیرها در صورت لزوم متغیرهای غیرضروری از مدل حذف می شوند.
2- مدل های گروه های چندگانه
تحلیل مدل های گروه های چندگانه با بررسی مدل های اندازه گیری و یکسانی اندازه گیری بین گروه ها آغاز می شود . چنین تحلیلی قبل از بررسی فرضیه های وجود تفاوت معنادار در ضرایب ساختاری بین گروه ها ضروری است. کاربرد این مدل شامل آزمون تفاوت بین برآورد پارامترها برای گروه های چندگانه می باشد.
به عنوان نمونه می توانیم به مثال ارائه شده توسط آربوکل و تکه (1999) اشاره کنیم. در این تحقیق تفاوت های ارزیابی از جذابیت و ارزیابی از توان آکادمیک بین دو گروه دختران و پسران مورد بررسی قرار گرفته است.
3- مدل های چند سطحی
مدل های چندسطحی در مدل سازی معادله ساختاری به علت ماهیت سلسله مراتبی داده ها در یک طرح تحقیقی آشیانه ای به این نام خوانده می شوند. به عنوان مثال پیشرفت تحصیلی یک دانشجو در کلاس ها پایه ریزی شده است، بنابراین دانشجویان در کلاس ها آشیان شده، معلمان درمدارس آشیان شده هستند و مدارس در مناطق آشیان شده اند. طرح پژوهشی آشیانه ای با یک طرح پژوهشی متقاطع متفاوت است.
علاقه ما در این نوع از طرح ها، با ملاحظه ماهیت خوشه ای شده داده ها، به اثرات در سطوح متفاوت است. EQS دارای سه روش اجرای مدل چند سطحی بر اساس یک متغیر خوشه ای است که عبارتند از :
الف) حداکثر درستنمایی با استفاده از الگوریتم انتظار/ ماکزیمم کردن.
ب) برآورد موتن مبتنی بر حداکثر درستنمایی
ج) مدل خطی سلسله مراتبی.
روش چندسطحی ML با استفاده از برآورد حداکثر درستنمایی، الگوریتم EM را در دو گام به منظور برآورد پارامترها و خطاهای معیار به کار می برد. الگوریتم اول گام انتظار است(E) که در آن ماتریس های کواریانس درون و بین سطحی با استفاده از تکرار برآورد می شوند. گام دوم به حداکثر رسانی (ماکزیمم سازی) است که در آن اگر معیار همگرایی برقرار باشد، برآوردهای حداکثر درستنمایی و خطاهای معیار تولید می شوند.
تحلیل چندسطحی با ML تنها برای مدل های دوسطحی طراحی شده است. تفسیر مدل های چندسطحی که بیشتر از دو سطح آشیان شده دارند مشکل است. اما با این حال مدل های خطی سلسله مراتبی در رگرسیون با سه سطح از متغیر مشاهده شده تحلیل شده اند.
مدل های خطی سلسله مراتبی در EQS برای تحلیل تا 5 سطح با استفاده از متغیرهای پنهان طراحی شده اند. در مدل های خطی سلسله مراتبی ابتدا معادله سطح اول معادله سطح اول برای هر خوشه اجرا شده و پارامترهای برآورد شده ذخیره می شوند و سپس برای استفاده در معادله سطح دو مورد استفاده قرار می گیرند. بنابراین معادله سطح دوم داده های خود و همچنین پارامترهای برآورد شده از سطح اول را مورد استفاده قرار می دهد.
مدل چند سطحی خطی سلسله مراتبی در EQS مشابه برنامه های چند سطحی حداکثر درستنمایی و برآورد موتن بر مبنای حداکثر درستنمایی است به جز اینکه مجموعه دومی از داده ها نیز در آن تعریف می شوند.
4- مدل های ترکیبی
مدل های ترکیبی در مدل سازی معادلات ساختاری شامل تحلیل متغیرهای مشاهده شده ای است که از دو نوع مقوله ای و پیوسته هستند. EQS امکانی را فراهم می آورد که دو نوع متغیرهای مقوله ای و پیوسته در مدل حضور داشته باشند.
5- مدل میانگین های ساختمند
کاربرد مهم دیگر مدل سازی معادله ساختاری، آزمون تفاوت میانگین های گروهی برای متغیرهای مشاهده شده یا پنهان است. این کاربرد در واقع حالت توسعه یافته تحلیل پایه رویکرد واریانس است جایی که تفاوت میانگین ها برای متغیرهای مشاهده شده آزمون می شوند. آزمون تفاوت میانگین ها بین متغیرهای مشاهده شده در مدل سازی معادله ساختاری مشابه با تحلیل واریانس و کواریانس است.
در مورد آزمون مربوط به متغیرهای پنهان به عنوان مثال آزمون تفاوت میانگین متغیر پنهان توان شفاهی بین پسران دانشگاهی و غیر دانشگاهی در پایه های پنجم و هفتم را می توان در نظر گرفت. در این مثال نمرات افراد در خواندن و نوشتن، متغیر پنهان را در پایه های پنجم و هفتم می سازد.
6- مدل های چند خصیصه ای-چند روشی
این مدل ها با هدف نشان دادن خصایص چندگانه ارزیابی شده به وسیله سنجه های چندگانه مورد استفاده قرار می گیرند. به عنوان مثال می توان از پیشرفت و انگیزه دانش آموزان (خصیصه ها) نام برد که به وسیله نمره دهی معلمان و نمره دهی خود دانش آموزان (روش ها) ارزشیابی شده اند. این مدل ها اطلاعاتی را برای تعیین اعتبار سازه تدارک می بینند.
ماتریس چندخصیصه ای-چند روشی ضرایب اعتبار همگرا، ضرایب اعتبار ممیز و ضرایب قابلیت اعتماد را در طول قطر منعکس می کند. ضرایب قابلیت اعتماد نشان دهنده سازگاری درونی نمرات بر روی ابزار است و بنابراین باید حدودا بین 0.85 تا 0.95 یا بالاتر قرار گیرد. ضرایب اعتبار ممیز، همبستگی های بین سنجه های خصایص مختلف (سازه ها) با استفاده از روش یکسان (ابزار) است و بنابراین انتظار می رود بسیار پایین تر از ضرایب اعتبار همگرا و یا ضرایب قابلیت اعتماد ابزار باشد.
7- مدل یگانگی همبسته
این مدل ها توسط مارش و گریسون (1995) و وتکه (1996) به عنوان جایگزینی برای مدل های سنتی چندخصیصه ای-چند روشی طرح شده اند. در مدل های یگانگی همبسته هر متغیر به عنوان یک عامل خصیصه و یک جمله خطا، اثر پذیرفته و عامل های روشی نیز وجود ندارند. اثرات روش به وسیله جملات خطای همبسته هر متغیر به حساب می آیند.جملات خطای همبسته تنها بین متغیرهای سنجش شده به وسیله روش مشابه وجود دارند.
انواع متفاوتی از مدل های یگانگی همبسته می توانند تحلیل شوند. به عنوان مثال می توان به از یک عامل عام با یگانگی همبسته، دو عامل همبسته با یگانگی غیرهمبسته و دو عامل غیرهمبسته با یگانگی همبسته نام برد. مارش و گریسون نشان می دهند که وجود کاهش معنادار در برازش بین یک مدل با خصایص همبسته اما جملات غیر همبسته و یک مدل با خصایص همبسته همراه با جملات خطای همبسته، نشانه وجود اثرات روشی است.
8- مدل های عاملی مرتبه دوم
این مدل ها هنگامی طرح می شوند که مدل های مرتبه اول به وسیله ساختار عاملی مرتبه بالاتر تبیین شوند. به عنوان مثال براساس داده های هولتزینگر و اسواینفورد نه متغیر روانشناختی، تعریف کننده سه عامل مشترک (بصری، شفاهی و سرعت) هستند. این سه عامل به نوبه خود عانل یگری به نام توان را تعریف می کنند. در برنامه Lisrel متغیر توان به عنوان یک متغیر پنهان معرفی می شود.
9- مدل های تعاملی
در مثال های قبلی فرض بر این بود که روابط موجود در مدل ها خطی هستند، به این معنا که همه روابط بین متغیرهای مشاهده شده و پنهان می توانند به وسیله معادلات خطی نشان داده شوند. هرچند که کاربرد اثرات تعاملی و غیرخطی در مدل های رگرسیونی عمومیت دارد، ارائه فرضیه های تعاملی در مدل های مسیر در حداقل است و مثال های بسیار کمی از مدل های عاملی غیرخطی تدارک دیده شده است. در واقع برای چندین دهه مدل سازی معادلات ساختاری برمبنای روابط ساختاری خطی قرار داشته است. اکنون مدل های معادله ساختاری با اثرات تعاملی امکان پذیر است.
در مدل سازی معادلات ساختاری اکنون می توانیم اثرات اصلی و اثرات تعاملی متغیرهای پنهان را آزمون کنیم. در هر حال چندین نوع از اثرات تعاملی وجود دارد. اثرات حاصلضرب متغیرهای مشاهده شده، غیرخطی، مقوله ای و حداقل مربعات دو مرحله ای.
رویکردهای متفاوتی را می توان برای بررسی اثرات تعاملی به کار برد، در ادامه این روش ها معرفی می شوند:
1-9- رویکرد متغیر پیوسته
کنی و جود (1984) روشی را برای آزمون تعامل میان متغیرهای پنهان براساس حاصلضرب های متغیرهای مشاهده شده طرح کرده اند. روش آن ها این امکان را فراهم می آورد که پژوهشگر هر دو نوع جملات درجه دوم و تعاملی را در میان متغیرهای پنهان وارد کند. به عنوان مثال اگر F1 بوسیله متغیرهای مشاهده شده X1 و X2 و F2 بوسیله متغیرهای مشاهده شده X3 و X4 تعریف شده اند، آنگاه تعامل متغیرهای پنهان به عنوان F3 می تواند بوسیله حاصلضرب های متغیرهای مشاهده شده مربوطه تعیین شود؛ یعنی X1X3 ، X1X4 ، X2X3 ، X2X4 . در این رویکرد متغیر پنهان تعاملی F3 می تواند در کنار متغیرهای پنهان اصلی F1 و F2 در معادله ساختاری وارد شود.
2-9- رویکرد متغیر مقوله ای
در این رویکرد نمونه های متفاوتی برحسب سطوح متفاوت متغیرهای تعاملی تعریف شده اند. منطق زیربنایی چنین است که چنانچه اثرات تعاملی وجود داشته باشند، هم اثرات اصلی و هم اثرات تعاملی می توانند با استفاده از نمونه ای متفاوت، به منظور آزمون تفاوت بین مقادیر عرض از مبدأ و ضریب زاویه تدوین شوند. دستیابی به چنین مدلی به وسیله اجرای دو مدل متفاوت امکان پذیر است. مدل اثرات اصلی برای تفاوت های گروهی در حالی که ضریب زاویه را ثابت نگه می داریم و مدل اثرات تعاملی برای تفاوت های گروهی در حالیکه مقادیر عرض از مبدأ و ضریب زاویه برآورد می شوند.
3-9- رویکرد حداقل مربعات دو مرحله ای
بولن (1996و1995) نشان داد که مدل های معادیه ساختاری غیرخطی می توانند به وسیله متغیرهای ابزاری در حداقل مربعات دو مرحله ای برآورد شوند. این روش از دو مرحله تشکیل شده است. در مرحله اول هریک از متغیرهای کمی برونزا در مدل رگرسیون می شوند و مقدار پیش بینی شده از این رگرسیون حاصل می شود.
در مرحله دوم رگرسیون هدف به طور معمول تخمین زده می شود و هر یک از متغیرهای برونزا با مقدار پیش بینی شده از مرحله اول جایگزین می شود. برآوردهای حداقل مربعات دو مرحله ای و خطاهای معیار آن ها بدون تکرار حاصل می شوند و بنابراین اطلاعاتی را بدست می دهد برای پاسخ به این سؤال که آیا مدل تدوین شده قابل دفاع هست یا خیر؟
4-9- مدل های انحنایی رشد پنهان
تحلیل واریانس سنجه های تکرار شده به طور گسترده ای با استفاده از متغیرهای مشاهده شده برای آزمون آماری تغییرات در طول زمان مورد استفاده قرار گرفته اند. مدل سازی معادله ساختاری تحلیل داده های طولی را توسعه داده تا رشد متغیر پنهان را در طول زمان در برگیرد، در حالیکه هم تغییرات منفرد و هم تغییرات طولی را با استفاده از ضریب زاویه و مقادیر عرض از مبدأ به مدل درمی آورد. تحلیل انحنایی رشد پنهان به لحاظ مفهومی مشتمل بر دو تحلیل متفاوت است.
تحلیل اولیه سنجه های تکرار شده در طول زمان، که به طور خطی یا غیرخطی به شکل فرضیه درآمده است.
تحلیل دوم شامل استفاده از پارامترهای منفرد(مقادیر ضریب زاویه و عرض از مبدأ) برای تعیین تفاوت رشد از یک خط مبنا است. مدل انحنایی رشد پنهان تفاوت ها را در طول زمان منعکس کرده و میانگین ها (عرض از مبدأ) و نرخ تغییرات(ضریب زاویه) را در دو سطح فردی و گروهی به حساب می آورد.
در هر حال این رویکرد نیازمند نمونه های بزرگ، داده های دارای توزیع نرمال چندمتغیره، فواصل زمانی مساوی برای همه آزمودنی ها و تغییراتی می باشد که در نتیجه یک پیوستار زمانی رخ می دهند.
5-9- مدل های عاملی پویا
نوعی از کاربردهای مدل سازی معادله ساختاری که شامل متغیرهای پنهان ثابت و غیرثابت در طول زمان، با خطای اندازه گیری تأخیری (همبسته) است به نام تحلیل عاملی پویا خوانده می شود. ویژگی این کاربرد از مدل سازی معادله ساختاری این است که ابزارهای اندازه گیری مشابهی برای آزمودنی های یکسانی در دو یا تعداد بیشتری از موقعیت های زمانی اجرا شده اند.
هدف این تحلیل ارزیابی تغییر در متغیر پنهان بین دو موقعیت مرتب شده، در ارتباط با برخی وقایع یا آزمایش ها است. هنگامی که ابزار اندازه گیری مشابهی در دو یا چند موقعیت زمانی به کار می روند، تمایلی برای وجود خطای اندازه گیری همبسته وجود دارد (خودهمبستگی)
برگرفته از سایت اطمینان شرق
برای مشاهده لیست همه ی پرسشنامه های استاندارد لطفا همین جا روی پرسشنامه استاندارد کلیک فرمایید.
ما در این سایت پرسشنامه های استاندارد (دارای روایی، پایایی، روش دقیق نمره گذاری ، منبع داخل و پایان متن ) ارائه می کنیم و همچنین تحلیل آماری کمی و کیفی رابا قیمت بسیار مناسب و کیفیت عالی و تجربه بیش از 17 سال انجام می دهیم. برای تماس به ما به شماره 09143444846 در شبکه های اجتماعی پیام بفرستید. ایمیلabazizi1392@gmail.com
تمامی حقوق مادی و معنوی این سایت متعلق به لنسرسرا و محفوظ است.
این سایت دارای مجوز می باشد