شاخص هاي برازش مدل معادلات ساختاري
به طور کلی شاخص های برازش مدل در سه دسته اصلی برازش مدل، تطبیق مدل و اقتصاد مدل قرار می گیرند. در این نوشتار به معرفی اين شاخص ها می پردازیم.
1- تعیین برازش مدل (پارامترها)
گاه حتی اگر معیار برازش کلی مدل بیانگر ساختاری قابل قبول باشد، برآورد پارامترهای منفرد در یک مدل می تواند فاقد معنا و مغهوم باشد. بنابراین تفسیر پارامترها در تحلیل هر مدل موضوعی با اهمیت است. در این باره گام های چهارگانه زیر پیشنهاد می شود :
1- بررسی کنید که آیا برآورد پارامترها دارای علامت مورد انتظار هستند یا خیر ؟
2- بررسی کنید که آیا برآورد پارامترها در دامنه تغییرات مورد نظر واقع می شوند یا خیر ؟
3- براورد پارامترها را برای تعیین معناداری آماری آن ها بررسی کنید.
4- عدم تفاوت سنجش بین گروهی را بوسیله برابر قرار دادن پارامترها (قیدها) در گروه های مختلف آزمون کنید و سپس مقایسه های نسبی را بین برآورد پارامترها انجام دهید.
بررسی برآورد پارامترهای اولیه نیز می تواند به تعیین نقص در مدل یا مدل بد تدوین شده کمک کند. در این مورد برآورد اولیه پارامترها به عنوان مقادیر اولیه مورد استفاده قرار می گیرند. به عنوان مثال در LISREL برآورد های اولیه حداقل مربعات دو مرحله با مقادیر آغازین تعریف شده توسط محقق جایگزین می شوند.
در مسیر برآورد پارامترها با مشکلات بسیاری ممکن است روبه رو شویم. گاه برآورد پارامترها مقادیر غیرممکنی را می گیرند، به عنوان مثال در مواردی که همبستگی بین متغیرها از عدد یک فراتر می رود چنین مشکلی پیش می آید. گاهی نیز مقادیر واریانس منفی بدست می آید.
علاوه براین ها داده های دورافتاده نیز می توانند برآورد پارامترها را تحت تأثیر قرار دهند. استفاده از حجم نمونه به اندازه کافی بزرگ و معرف های چندگانه برای هر متغیر پنهان، به عنوان راهکارهایی برای رسیدن به برآوردهای پایدار پارامترها پیشنهاد شده اند.
پس از آنکه این موضوعات مورد توجه قرار گرفتند تفسیر شاخص های اصلاح (آزمون های لاگرانژ و والد) و تغییرات بعدی در شاخص های برازش مدل می تواند آغاز شود.
اعتبار مدل بر اساس دو نیمه کردن نمونه مورد مطالعه و یا بررسی یک نمونه مستقل دیگر هنگامی که به مدل قابل قبول دست می یابیم، همواره باید مورد توجه باشد تا از پایداری برآورد پارامترها و اعتبار مدل اطمینان یابیم. علاوه براین ها خودگردان سازی نیز یک روش باز نمونه گیری را با استفاده از یک نمونه منفرد به کار می گیرد تا کارآمدی و دقت برآوردهای نمونه ای را آزمون کند.
آزمون های معناداری پارامترهای برآورد شده
آزمون های معناداری پارامترهای برآورد شده برای مدل های آشیان شده، شامل آزمون های نسبت درستنمایی(LR)، مضرب لاگرانژ(LM) و والد می باشد. پیش از آشنایی با هریک از این آزمون ها بایستی مفهوم مدل های آشیان شده را بیان نماییم.
مدل های آشیان شده
در یک مدل آشیان شده، یک ماتریس واریانس-کواریانس نمونه ای برای مدل اولیه با یک مدل مقید که در آن برآورد یک پارامتر برابر صفر قرار داده شده است مقایسه می شود. این روش با آزمون مدل های کامل در رگرسیون چندگانه قابل قیاس است.
در مدل سازی معادله ساختاری هدف تعیین معناداری تغییرات آماره کای دو برای مدل کامل است. در روش های برآورد حداقل مربعات تعمیم یافته، حداکثر درستنمایی و حداقل مربعات وزنی، این موضوع شامل تعیین معناداری آماره کای دو با یک درجه آزادی برای برآورد یک پارامتر منفرد است. بنابراین باید مقدار کاهش آماره کای دو برابر یا بیش از مقدار شاخص اصلاح برای برآورد پارامتری باشد که برابر صفر قرار داده شده است.
آزمون نسبت درستنمایی بین مدل های جایگزین برای بررسی تفاوت در مقادیر آماره کای دو بین مدل اولیه (کامل) و مدل مقید (اصلاح شده) در جایی که برآورد پارامتر برابر صفر قرار داده شده است امکان پذیر است. آمون نسبت درستنمایی براساس رابطه زیر محاسبه می شود :
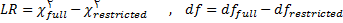
آزمون مضرب لاگرانژ برازش یک مدل مقید را با مدلی با قید کمتر مقایسه کرده و در این مقایسه از ماتریسی مشابه ماتریس واریانس-کواریانس نمونه ای استفاده می کند. این آزمون پارامترهایی را نشان می دهد که لازم است به مدل افزوده شده یا در مدل به حساب آیند. محقق در این آزمون متغیری را برمی گزیند که بیشترین کاهش را در آماره کای دو را به دنبال دارد. مضرب لاگرانژ دارای توزیع کای دو با درجه آزادی برابر با تفاوت درجات آزادی مدل های مقیدی است که با یکدیگر مقایسه می شوند.
در آزمون والد یک بردار 1*r از قیدها با نام (r(θ در نظر می گیرد (برداری از پارامترهای انتخاب شده توسط محقق که برابر صفر قرار داده می شوند). اگر این بردار مقادیر بزرگتر از صفر را نشان دهد آنگاه مدل مقید یک مدل معتبر نیست. آماره والد نیز دارای توزیع کای دو با درجه آزادی برابر با تعداد قیدها در (r(θ است. برخلاف آزمون نسبت درستنمایی هیچ یک از آماره های مضرب لاگرانژ و والد نیاز به برآوردهای جداگانه از قیدهای مدل های اولیه (کامل) و اصلاح شده (مقید) ندارند.
2- تطبيق مدل
با در نظر گرفتن نقشی که آماره کی دو در برازش مدل هایی با متغیرهای پنهان ایفا می کند، سه شاخص دیگر به عنوان روش هایی برای مقایسه مدل های جایگزین طرح می شوند : شاخص توکرلوییس (TLI)، شاخص برازش هنجارنشده (NNFI) یا هنجار شده (NFI) بنتلر بونت(1987) و شاخص برازش تطبیقی (CFI ).
این شاخص ها نوعا یک مدل پیشنهاد شده را با یک مدل صفر (مدل مستقل) مقایسه می کنند. توجه داشته باشید هر مدلی که پژوهشگر انتظار تفاوت مدل های جایگزین با آن را به عنوان یک مدل مبنایی داشته باشد، یک مدل صفر می باشد.
شاخص توکر-لوییس
این شاخص در ابتدا توسط توکر و لوییس(1973) برای تحلیل عاملی مطرح شد. اما سپس آن را برای مبحث مدل سازی معادله ساختاری توسعه دادند. این شاخص می تواند برای مقایسه مدل های جایگزین یا یک مدل پیشنهاد شده در مقابل مدل صفر به کار رود. مقدار این شاخص به کمک آماره کای دو به صورت زیر محاسبه می شود :
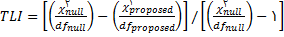
مقدار این شاخص بین 0 و 1 تغییر می کند. مقدار 0 نشان دهنده فقدان برازش و 1 بیانگر برازش کامل است.
شاخص برازش هنجار شده
شاخص برازش هنجار شده براساس تبدیل مقیاس کای دو ساخته شده و مقدار آن بین 0 و1 تغییر می کند. این شاخص برای مقایسه یک مدل مقید با مدل کامل بکار می رود وآماره معرفی شده برای آن به صورت زیر است :
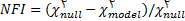
شاخص برازش مقایسه ای
این شاخص که به عنوان شاخص برازش مقایسه ای بنتلر نیز نامیده می شود، برازش مدل موجود را با مدل صفری مقایسه می کند که در ان فرض شده است متغیرهای پنهان با یکدیگر ناهمبسته اند (مدل مستقل). در این روش با مقایسه ماتریس کواریانس پیش بینی شده براساس مدل و ماتریس کواریانس مشاهده شده در صد فقدان برازشی را که براساس حرکت از مدل صفر به مدل تعریف شده بوسیله محقق به حساب آمده است، تخمین می زند. به لحاظ معنا CFI مشابه NFI است که برای حجم نمونه اصلاح شده محاسبه شود. مقدارCFI نزدیک به 1 برازش بسیار خوب را نشان می دهد.
3- شاخص های اقتصاد مدل
اقتصاد مدل
اقتصاد مدل به تعداد پارامترهای برآورد شده ای اشاره دارد که برای دستیابی به سطح خاصی از برازش مورد نیاز هستند. در این روش یک مدل فرامشخص با یک مدل مقید مقایسه می شود. شاخص هایی که در این زمینه مورد استفاده قرار می گیرند شامل کای اسکوئر هنجار شده (NC)، شاخص برازش مقتصد(PNFI,PCFI ) و معیار اطلاع آکائیک می باشند. این شاخص ها در واقع تعداد پارامترهایی را به حساب می آورد که برای رسیدن به مقدار خاصی از کای اسکوئر مورد نیاز است.
کای اسکوئر هنجار شده NC
پیش از معرفی این شاخص بایستی شاخص کای اسکوئر را معرفی نماییم.
کای اسکوئر
یک مقدار کای اسکوئر با درجه آزادی مشخص که به لجاظ آماری معنادار است، نشان می دهد که ماتریس های واریانس-کواریانس مشاهده شده و برآورد شده متفاوتند. به بیان دیگر محقق مایل به دستیابی به مقادیری از آماره کای دو است که کوچکتر از مقدار جدول کی دو باشد یعنی از نظر آماری معنادار نباشد.
سه روش برآورد برای محاسبه این آماره بکار برده می شود. روش حداکثر درستنمایی(ML)، حداقل مربعات تعمیم یافته(GLS) و حداقل مربعات غیر وزنی(ULS). هریک از این روش ها شرایط و همچنین مزایای خاص خود را دارا هستند. آماره کای دو از رابطه مقابل محاسبه می شود :

در این روابط t تعداد کل پارامترهای مستقل برآورد شده، n تعداد مشاهدات، p تعداد متغیرهای مشاهده شده و تحلیل شده و tr اثر ماتریس را نشان می دهند.
و اما در مورد شاخص کای دو هنجار شده، یورسکوگ (1969) پیشنهاد کرد که آماره کی دو به کمک درجه آزادی آن به منظور ارزیابی برازش مدل اصلاح شود. به این ترتیب می توان دو نوع از مدل های نامناسب را تعیین کرد : الف) مدلی که فرامشخص است. ب) مدلی که با داده های مشاهده شده برازش نداشته و نیاز به بهبود دارد. شاخص کای دو هنجار شده از تقسیم آماره کی دو بر درجه آزادی آن محاسبه می شود.
شاخص برازش مقتصد PFI
شاخص برازش مقتصد به عنوان یکی از شاخص های برازش، اصلاح شده ی شاخص برازش هنجار شده می باشد. این شاخص تعداد درجات آزادی را به حساب می آورد که برای حصول سطح خاصی از برازش بکار می رود.شاخص های برازش مقتصد برای مقایسه مدل ها با درجات آزادی متفاوت مورد استفاده قرار گرفته و براساس رابطه زیر محاسبه می شود :
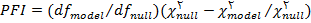
مقادیر مربوط به مدل تحت فرض صفر با عبارت null و مدل تحت فرض مقابل با model مشخص شده اند.
معیار اطلاع آکائیک
معیار اطلاع آکائیک برای مقایسه مدل هایی با تعداد متفاوتی از متغیرهای پنهان بکار می رود.

منبع
مقدمه ای بر مدل سازی معادله ساختاری ، نوشته رندال. ای. شوماخر و ریچارد.جی.لومکس/ ترجمه شده توسط دکتر وحید قاسمی/ انتشارات جامعه شناسان
برگرفته از سایت اطمینان شرق
- برای مشاهده لیست همه ی پرسشنامه های استاندارد لطفا همین جا روی پرسشنامه استاندارد کلیک فرمایید.
- تحلیل داده های آماری برای پایان نامه و مقاله نویسی ،تحلیل داده های آماری شما با نرم افزارهای کمی و کیفی ،مناسب ترین قیمت و کیفیت عالی انجام می گیرد.نرم افزار های کمی: SPSS- PLS – Amosنرم افزار کیفی: Maxqudaتعیین حجم نمونه با:Spss samplepower
- روش های تماس:Mobile : 09143444846 واتساپ – تلگرام کانال
- تلگرام سایت: برای عضویت در کانال تلگرام سایت اینجا کلیک کنید(البته قبلش فیلتر شکن روشن شود!!) مطالب جالب علمی و آموزشی در این کانال درج می گردد.