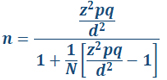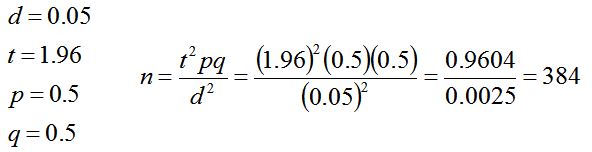راهنمای جامع آزمونهای مقایسهای در SPSS: انتخاب بهترین آزمون آماری : یاد بگیرید چگونه بین t-test، ANOVA، MANOVA و آزمونهای ناپارامتریک بهترین انتخاب را داشته باشید.
آیا در تحلیل دادههای پژوهشی خود با SPSS سردرگم هستید؟ انتخاب صحیح آزمون آماری برای مقایسه گروهها و متغیرها، یکی از حیاتیترین مراحل هر تحقیق کمی است. این راهنمای کامل، تمام آزمونهای مقایسهای موجود در نرمافزار SPSS را بهطور سیستماتیک دستهبندی و شرایط استفاده از هر یک را مشخص میکند.
در مقاله و ویدئوی زیر این مهم شرح داده شده است.
<div id="43044500080"><script type="text/JavaScript" src="https://www.aparat.com/embed/dkie810?data[rnddiv]=43044500080&data[responsive]=yes&muted=true&titleShow=true&recom=self"></script></div>مقدمه: چرا انتخاب آزمون مناسب اینقدر مهم است؟
انتخاب نادرست آزمون آماری میتواند منجر به نتایج اشتباه، رد فرضیههای درست و پذیرش فرضیههای نادرست شود. SPSS با دارا بودن دهها آزمون آماری مختلف، ابزار قدرتمندی است اما نیازمند دانش کافی برای استفاده صحیح است.
در این مقاله، نه تنها تمام آزمونهای مقایسهای را معرفی میکنیم، بلکه راهنمای عملی انتخاب بر اساس نوع داده، تعداد گروهها و پیشفرضهای آماری ارائه میدهیم.
📊 آزمونهای مقایسه میانگینها (پارامتریک)
آزمون t تکنمونهای (One-Sample T Test)
کاربرد: مقایسه میانگین یک نمونه با یک مقدار ثابت یا نظری
مثال کاربردی:
- آیا میانگین قد دانشجویان دانشگاه شما با میانگین کشوری (مثلاً ۱۷۲ سانتیمتر) تفاوت دارد؟
- آیا رضایت مشتریان از محصول جدید (بر اساس مقیاس ۱-۱۰) به طور معنیداری بالاتر از ۷ است؟
پیشفرضهای کلیدی:
- توزیع نرمال دادهها
- دادهها در سطح فاصلهای یا نسبی باشند
آزمون t مستقل (Independent Samples T Test)
کاربرد: مقایسه میانگین دو گروه کاملاً مستقل از هم
موارد استفاده رایج:
- مقایسه عملکرد دو روش تدریس مختلف
- بررسی تفاوت درآمد زنان و مردان
- مقایسه سطح اضطراب بیماران تحت دو درمان متفاوت
نکته حیاتی: قبل از این آزمون حتماً همگنی واریانسها با آزمون لون بررسی شود.
آزمون t جفتی (Paired Samples T Test)
کاربرد: مقایسه دو اندازهگیری از یک گروه در دو زمان مختلف
کاربردهای پژوهشی:
- مقایسه نمرات دانشآموزان قبل و بعد از یک دوره آموزشی
- اندازهگیری اثر یک دارو بر فشار خون (قبل و بعد از مصرف)
- سنجش رضایت کارکنان قبل و بعد از اجرای یک طرح انگیزشی
تحلیل واریانس یکطرفه (One-Way ANOVA)
کاربرد: مقایسه میانگین سه یا چند گروه مستقل
مثال: مقایسه بازده محصول در چهار نوع خاک مختلف
آزمونهای تعقیبی ضروری:
- آزمون توکی (Tukey) برای حجم نمونه برابر
- آزمون شفه (Scheffe) برای حجم نمونه نابرابر
- آزمون بونفرونی (Bonferroni) برای مقایسههای از پیش برنامهریزی شده
تحلیل واریانس دوطرفه (Two-Way ANOVA)
کاربرد: بررسی همزمان اثر دو عامل مستقل و اثر تعاملی آنها
مثال: بررسی اثر جنسیت و سطح تحصیلات بر درآمد
خروجی مهم:
- اثر اصلی عامل اول
- اثر اصلی عامل دوم
- اثر تعاملی دو عامل
تحلیل واریانس با اندازهگیری مکرر (Repeated Measures ANOVA)
کاربرد: مقایسه میانگین یک گروه در سه یا چند زمان مختلف
مثال: اندازهگیری سطح استرس افراد در چهار مرحله:
۱. قبل از امتحان
۲. هنگام امتحان
۳. بلافاصله بعد از امتحان
۴. یک هفته بعد
📈 آزمونهای ناپارامتریک (مقایسه میانهها)
آزمون علامت (Sign Test) و ویلکاکسون (Wilcoxon)
جایگزین ناپارامتریک آزمون t جفتی
زمان استفاده:
- دادهها نرمال نیستند
- حجم نمونه کوچک است (کمتر از ۳۰)
- دادهها رتبهای هستند
آزمون من-ویتنی (Mann-Whitney U)
جایگزین ناپارامتریک آزمون t مستقل
کاربرد: مقایسه توزیع دو گروه مستقل وقتی:
- فرض نرمال بودن نقض شده
- دادهها رتبهای هستند
- نمونهها کوچک هستند
آزمون کروسکال-والیس (Kruskal-Wallis)
جایگزین ناپارامتریک ANOVA یکطرفه
نکته: اگر نتیجه معنیدار شود، از آزمون تعقیبی من-ویتنی برای مقایسههای دو به دو استفاده میشود.
🔬 آزمونهای پیشرفته و چندمتغیره
تحلیل واریانس چندمتغیره (MANOVA)
کاربرد: مقایسه همزمان چند متغیر وابسته بین گروهها
مثال پژوهشی:
مقایسه دو روش درمانی بر اساس:
- سطح اضطراب
- نمره افسردگی
- کیفیت خواب
مزیت: کاهش خطای نوع اول در مقایسه با انجام چندین ANOVA جداگانه
تحلیل کوواریانس (ANCOVA)
کاربرد: مقایسه میانگین گروهها پس از کنترل اثر یک یا چند متغیر کمکی
مثال: مقایسه تأثیر سه روش آموزش ریاضی بر پیشرفت تحصیلی، با کنترل اثر هوش به عنوان کوواریانس
🎯 راهنمای گامبهگام انتخاب آزمون مناسب
گام ۱: تعیین نوع سؤال پژوهشی
- سؤال نوع اول: آیا تفاوتی وجود دارد؟
- سؤال نوع دوم: رابطه چگونه است؟
- سؤال نوع سوم: میزان پیشبینی چقدر است؟
گام ۲: شناسایی متغیرها
- متغیر مستقل (عامل) چیست؟
- متغیر وابسته (پاسخ) چیست؟
- متغیرهای کنترل یا کوواریانس کدامند؟
گام ۳: بررسی پیشفرضها
چکلیست بررسی پیشفرضها:
✅ نرمال بودن: با آزمون کولموگروف-اسمیرنوف یا شاپیرو-ویلک
✅ همگنی واریانس: با آزمون لون
✅ استقلال خطاها: با آزمون دوربین-واتسون
✅ خطی بودن رابطه (در صورت لزوم)
✅ همگنی ماتریس کوواریانس (برای MANOVA)
گام ۴: انتخاب نهایی آزمون
درخت تصمیمگیری سریع:
textCopyDownload
آیا دادهها نرمال هستند؟
├── بله → آزمونهای پارامتریک
│ ├── دو گروه مستقل → t مستقل
│ ├── دو گروه وابسته → t جفتی
│ ├── چند گروه مستقل → ANOVA
│ └── چند گروه وابسته → Repeated ANOVA
└── خیر → آزمونهای ناپارامتریک
├── دو گروه مستقل → من-ویتنی
├── دو گروه وابسته → ویلکاکسون
├── چند گروه مستقل → کروسکال-والیس
└── چند گروه وابسته → فریدمن
💻 اجرای آزمونها در SPSS: مسیرهای کلیدی
منوی اصلی Compare Means:
- One-Sample T Test
- Independent Samples T Test
- Paired Samples T Test
- One-Way ANOVA
منوی General Linear Model:
- Univariate (برای ANOVA, ANCOVA)
- Repeated Measures
- Multivariate (برای MANOVA)
منوی Nonparametric Tests:
- Independent Samples (من-ویتنی، کروسکال-والیس)
- Related Samples (ویلکاکسون، فریدمن)
📝 جدول خلاصه آزمونها
| نوع مقایسه | آزمون پارامتریک | آزمون ناپارامتریک | پیشفرضها |
|---|---|---|---|
| یک گروه با مقدار ثابت | t تکنمونهای | آزمون علامت | نرمال بودن |
| دو گروه مستقل | t مستقل | من-ویتنی | نرمال بودن، همگنی واریانس |
| دو گروه وابسته | t جفتی | ویلکاکسون | نرمال بودن تفاضل جفتها |
| چند گروه مستقل | ANOVA یکطرفه | کروسکال-والیس | نرمال بودن، همگنی واریانس |
| چند گروه وابسته | Repeated ANOVA | فریدمن | نرمال بودن، همسانی کوواریانس |
| چند متغیر وابسته | MANOVA | – | نرمال بودن چندمتغیره |
⚠️ خطاهای رایج در انتخاب آزمونهای مقایسهای
خطای شماره ۱: استفاده از آزمونهای پارامتریک بدون بررسی نرمال بودن
راه حل: همیشه ابتدا نرمال بودن دادهها را بررسی کنید.
خطای شماره ۲: انجام چندین آزمون t به جای ANOVA
نتیجه: افزایش خطای نوع اول
راه حل: برای مقایسه بیش از دو گروه از ANOVA استفاده کنید.
خطای شماره ۳: فراموش کردن آزمونهای تعقیبی پس از ANOVA
نتیجه: نمیدانید کدام گروهها با هم تفاوت دارند.
خطای شماره ۴: استفاده از آزمون برای دادههای ردهای
یادآوری: آزمونهای پارامتریک برای دادههای فاصلهای و نسبی طراحی شدهاند.
🏆 نکات طلایی برای تحلیل حرفهای در SPSS
نکته ۱: همیشه گزارش کامل ارائه دهید
- مقدار آماره آزمون
- درجه آزادی
- سطح معنیداری (p-value)
- اندازه اثر (Effect Size)
نکته ۲: از نمودارها استفاده کنید
- Boxplot برای مقایسه گروهها
- Histogram برای بررسی نرمال بودن
- Error bar chart برای نمایش میانگین و خطای استاندارد
نکته ۳: دادههای پرت را مدیریت کنید
- شناسایی با Boxplot
- تصمیم بگیرید: حذف، جایگزینی یا نگهداری
نکته ۴: تحلیل قدرت آزمون را فراموش نکنید
- قبل از جمعآوری داده: محاسبه حجم نمونه لازم
- بعد از تحلیل: گزارش قدرت آزمون انجام شده
سؤالات متداول (FAQ)
سؤال ۱: اگر برخی پیشفرضها رعایت نشوند چه کار کنم؟
پاسخ: سه راهکار دارید:
۱. تبدیل دادهها (مثلاً با لگاریتم گیری)
۲. استفاده از آزمون ناپارامتریک
۳. استفاده از روشهای مقاوم (Robust Methods)
سؤال ۲: تفاوت ANOVA و t-test چیست؟
پاسخ: t-test فقط دو گروه را مقایسه میکند، اما ANOVA برای سه گروه یا بیشتر استفاده میشود. از نظر ریاضی، ANOVA تعمیم یافته t-test است.
سؤال ۳: چه زمانی از ANCOVA استفاده کنیم؟
پاسخ: وقتی میخواهید اثر یک متغیر مزاحم را کنترل کنید تا مقایسه گروهها عادلانهتر باشد.
جمعبندی نهایی
انتخاب آزمون مناسب در SPSS نیازمند درک عمیق از:
۱. سؤال پژوهشی شما
۲. نوع دادههای جمعآوری شده
۳. پیشفرضهای هر آزمون
۴. هدف نهایی از تحلیل
به یاد داشته باشید که هیچ آزمونی “بهترین” نیست، فقط آزمون “مناسب” برای شرایط دادههای شما وجود دارد.
نظر شما چیست؟
کدام آزمون آماری بیشترین چالش را برای شما ایجاد کرده است؟
آیا تجربه خاصی در استفاده از آزمونهای مقایسهای در SPSS دارید؟
دیدگاهها و تجربیات خود را با ما و دیگر خوانندگان به اشتراک بگذارید!
ارتباط با ما
🌐 وب سایت: https://rava20.ir
📱 کانال تلگرام: https://t.me/RAVA2020
🎬 کانال آموزشی آپارات: https://www.aparat.com/amoozeh20
✍️ وبلاگ تخصصی: http://abazizi.parsiblog.com/
خواهشمند است، نظر خودتان را در پایان نوشته در سایت https://rava20.ir مرقوم نمایید. همین نظرات و پیشنهاد های شما باعث پیشرفت سایت می گردد. با تشکر
پیشنهاد می شود مطالب زیر را هم در سایت روا 20 مطالعه نمایید:
راهنمای کامل نرم افزار مکس کیو دی ای maxqda برای تحلیل دادههای کیفی در پژوهش فارسی
پرسشنامه ویژگی های معلم اثربخش درآموزش مجازی
آزمون اپسیلون گرین هاوس در مقایسه با سایر آزمونهای مشابه چه محدودیتهایی دارد؟
آیا QDA Miner قابلیت تحلیل کمی را برای دادههای خروجی در نرمافزارهای آماری دیگر فراهم میکند؟