...........................................................................................................................................................................................................................................................................................................................................................................
خوش آمدید این سایت دارای مجوز می باشد برای مشاهده مجوز ها پایین صفحه را مشاهده فرمائید.
آیا آزمون اوم نی بوس تنها روش ارزیابی مدل رگرسیون لجستیک است؟ خیر، آزمون اوم نی بوس (Omnibus test) تنها یکی از روشهای ارزیابی مدل رگرسیون لجستیک نیست. در واقع، برای ارزیابی یک مدل رگرسیون لجستیک، از چندین روش و آزمون آماری میتوان استفاده کرد. تعدادی از این روشها و آزمونها عبارتند از:
آزمون اوم نی بوس (Omnibus test): همان آزمونی است که قبلاً در مورد آن صحبت کردیم. این آزمون بررسی میکند که آیا متغیرهای مستقل در مدل رگرسیون لجستیک تأثیر معناداری بر متغیر پاسخ دارند یا خیر. آزمون والدشه (Wald test): این آزمون بررسی میکند که آیا هر یک از ضرایب تخمین داده شده مربوط به متغیرهای مستقل در مدل رگرسیون لجستیک تفاوت معناداری با صفر دارند یا خیر. این آزمون بر پایه ارزش p محاسبه شده برای هر ضریب انجام میشود. آزمون احتمال نسبی (Likelihood Ratio test): این آزمون بررسی میکند که آیا یک مدل رگرسیون لجستیک کامل (با همه متغیرهای مستقل) نسبت به یک مدل محدودتر (با برخی از متغیرهای مستقل حذف شده) بهبود معناداری دارد یا خیر. این آزمون بر پایه تغییر در تابع لایکلیهود است که به صورت مقایسهای انجام میشود. آزمون کیدرمن-کوینت (Kolmogorov-Smirnov test): این آزمون بررسی میکند که آیا مدل رگرسیون لجستیک به طور کلی با دادهها سازگار است یا خیر. این آزمون بر پایه تفاوت بین توزیع پیشبینی شده و توزیع واقعی متغیر پاسخ انجام میشود. این فقط چند مثال از آزمونها و روشهای ارزیابی مدل رگرسیون لجستیک هستند و هنوز روشهای دیگری نیز وجود دارند. انتخاب روشهای ارزیابی مناسب بستگی به مسئله پژوهشی و خصوصیات دادهها دارد. معمولاً از ترکیب چندین آزمون و روش برای ارزیابی جامعتر مدل استفاده میشود.
آزمون احتمال دقیق فیشر یک آزمون آماری از آزمونهای خانواده کای دو است که برای بررسی رابطه یا مستقل بودن بین دو متغیر دستهای در یک جدول تابعیت (contingency table) استفاده میشود. این آزمون توسط آماردان رونالد آی. فيشر در سال ۱۹۲۲ توسعه داده شد و برخلاف آزمون کای-دو (Chi-square test)، به صورت دقیق از رویکرد ترکیبیاتی استفاده میکند.
آزمون دقیق فیشر، که به عنوان آزمون فیشر نیز شناخته میشود.. این آزمون زمانی به کار میرود که تعداد مشاهدات در هر گروه کوچک باشد و شرایط برای استفاده از آزمون کای دو برقرار نباشد. در این موارد، آزمون احتمال دقیق فیشر به جای آزمون کای-دو استفاده میشود. زمانی که فراوانیهای مورد انتظار خانههای جدول کوچک باشند (کمتر از ۵) برای انجام آزمون استقلال، نمیتوان از آزمون کای دو یا خی دو استفاده نمود بنابراین باید از آزمونهای معادل یا آزمون دقیق فیشر استفاده کرد، مخصوصا هنگامی که جدول ۲×۲ است.
آزمون احتمال دقیق فیشر از جدول تابعیت استفاده میکند که دو متغیر دستهای را در دو ستون و دو ردیف نشان میدهد. مثلاً در مطالعهای در مورد علاقهمندی به دو نوع محصول (متغیر اول) بین دو گروه مشتری (متغیر دوم)، جدول تابعیت میتواند به صورت زیر باشد:
گروه A
گروه B
محصول 1
a
b
محصول 2
c
d
در این جدول، a، b، c و d تعداد افراد موجود در هر سلول مشخص میکنند. آزمون احتمال دقیق فیشر بر اساس توزیع هندسی است و احتمال دیده شدن هر سلول را با توجه به مجموعهای از فرضیات محاسبه میکند.
کاربرد آزمون احتمال دقیق فیشر در بررسی رابطه بین دو متغیر دستهای در مواردی است که حجم نمونه کم باشد..
بعضی از کاربردهای آزمون احتمال دقیق فیشر عبارتند از:
بررسی ارتباط بین عوامل خطر و بروز بیماریها در مطالعات پزشکی.
تحلیل دادههای ژنتیکی و بررسی رابطه بین آللهای ژنتیکی و بیماریها.
بررسی ارتباط بین عوامل محیطی و بروز پدیدههای بیولوژیکی.
آزمون دقیق فیشر احتمال مشاهده یک جدول داده خاص یا جدولی که از نظر آماری مشابه آن باشد را، با فرض اینکه فرضیه صفر درست باشد، محاسبه میکند. فرضیه صفر در این آزمون بیان میکند که بین دو گروهی که مورد مقایسه قرار میگیرند، هیچ ارتباطی وجود ندارد.
اگر مقدار p حاصل از آزمون دقیق فیشر کمتر از سطح معنیداری (معمولاً 05/0 ) باشد، فرضیه صفر رد میشود و این نتیجهگیری میشود که بین دو گروه ارتباط آماری معنیداری وجود دارد.
آزمون اپسیلون هوین – فلت (Huynh-Feldt Epsilon test) که به عنوان آزمون اپسیلون هوبز (Hobbs Epsilon test) نیز شناخته می شود، یک آزمون آماری است که در تحلیل واریانس با اندازه گیری های مکرر (ANOVA) برای بررسی فرض کرویت (sphericity) به کار می رود. فرض کرویت بیان می کند که واریانس خطاها در بین سطوح مختلف عامل درون آزمودنی همگن است.
اگر این فرض نقض شود، آزمون های F سنتی ممکن است بیش از حد آزاد (liberal) باشند، به این معنی که احتمال رد فرضیه صفر (H0) زمانی که درست است، بیشتر از حد مجاز است.
آزمون اپسیلون هوین – فلت یک جایگزین محافظه کارانه تر برای آزمون های F سنتی است که درجات آزادی (degrees of freedom) را برای جبران نقض کرویت تعدیل می کند. این آزمون از اپسیلون گرین هاوس – گیسر (Greenhouse-Geisser Epsilon) محافظه کارتر است، با این حال مقدار آن ممکن است از 1 بیشتر باشد. این مقدار برای محاسبه درجات آزادی جدید و همچنین سطح معناداری جدید استفاده می شود.
کاربرد آزمون اپسیلون هوین – فلت
آزمون اپسیلون هوین – فلت زمانی که تعداد گروه های نمونه کوچک باشد، یا زمانی که شواهدی از نقض کرویت وجود داشته باشد، به ویژه زمانی که اپسیلون گرین هاوس – گیسر (Greenhouse-Geisser Epsilon) کمتر از 0.75 باشد، مفید است.
آزمون اثر پیلایی بارتلت یا Pillai – Bartelet trace test چیست؟
در طرحهای تحقیقی چندمتغیره، همزمان بر روی چندین متغیر وابسته اندازهگیری میشود و مطالعه تأثیر یک یا چند متغیر مستقل بر روی این متغیرهای وابسته انجام میشود. برای بررسی تفاوتهای معنادار بین گروهها در متغیرهای وابسته، میتوان از MANOVA استفاده کرد. اما در MANOVA، به جای بررسی هر متغیر وابسته به صورت جداگانه، تمامی متغیرهای وابسته به صورت همزمان بررسی میشوند.
آزمون اثر پیلایی بارتلت (Pillai-Bartlett trace test) یک آزمون آماری است که در آمار تحلیل واریانس چندمتغیره (MANOVA) استفاده میشود. این آزمون برای بررسی فرضیه برابری میانگین بردارهای چند متغیره به کار می رود ( 1 و 2)
آزمون اثر پیلایی-بارتلت یکی از چندین آماره آزمون است که در MANOVA استفاده می شود [4 ، [6] . در مقایسه با سایر آماره های آزمون، آزمون اثر پیلایی-بارتلت نسبت به نقض برخی از فرضیه های اساسی MANOVA از جمله همگنی واریانس-کوواریانس قویتر است [2، [6] .
در اینجا، آزمون اثر پیلایی بارتلت (Pillai-Bartlett trace test) برای بررسی تفاوتهای معنادار بین گروهها در MANOVA استفاده میشود.
این آزمون از مقدار “اثر پیلایی بارتلت” که یک پارامتر است، برای ارزیابی تفاوتهای معنادار بین گروهها استفاده میکند. مقدار اثر پیلایی بارتلت بین 0 و 1 قرار میگیرد.
مقدار نزدیک به 1 نشان دهنده وجود تفاوتهای معنادار بین گروهها است، در حالی که مقدار نزدیک به 0 نشان دهنده عدم وجود تفاوت معنادار است.
آزمون اثر پیلایی بارتلت عموماً در طرحهای تحقیقی چندمتغیره با دو یا بیشتر متغیر وابسته استفاده میشود و میتواند در بسیاری از زمینههای پژوهشی و کاربردی از جمله علوم اجتماعی، روانشناسی، آموزش، علوم پزشکی و زیستشناسی مورد استفاده قرار گیرد.
منابع:
Statology – What is Pillai’s Trace? (Definition & Example)
معمولا آزمون ANOVA با اندازه گیری های مکرر (فاکتورهای درون سوژه ای (within-subject factors)) در معرض نقض فرض کروی بودن هستند.
کرویت یا کروی بودن (Sphericity) شرایطی است که در آن واریانس تفاوت بین تمام ترکیبات گروه های مرتبط برابر است. نقض کرویت زمانی است که واریانس تفاوت بین تمام ترکیبات گروه های مرتبط برابر نباشد.
کرویت را می توان به همگنی واریانس ها در ANOVA بین سوژه ها تشبیه کرد.
نقض کرویت برای ANOVA اندازه گیری های مکرر جدی است.
این نقض باعث آزاد شدن بیش از حد آزمون (یعنی افزایش میزان خطای نوع I) میشود.
بنابراین، تعیین اینکه آیا کرویت نقض شده است یا نه، بسیار مهم است.
خوشبختانه، اگر نقض کرویت رخ دهد، اصلاحاتی برای تولید یک مقدار F بحرانی معتبرتر (یعنی کاهش در افزایش میزان خطای نوع I) وجود دارد.
این با تخمین درجه نقض کرویت و اعمال یک ضریب تصحیح برای درجات آزادی توزیع-F (F-distribution) به دست می آید.
بعداً در این آموزش در این مورد با جزئیات بیشتری صحبت خواهیم کرد. در ابتدا، ما کروی بودن را با یک مثال نشان خواهیم داد.
نمونه ای از کرویت
برای نشان دادن مفهوم کروی به عنوان برابری واریانس تفاوتهای بین هر جفت مقادیر، دادههای ساختگی را در جدول 1 زیر تجزیه و تحلیل میکنیم. این داده ها از یک مطالعه ساختگی است که ظرفیت هوازی (واحد: ml/min/kg) را در سه نقطه زمانی (Time1، Time2، Time3) برای شش سوژه اندازه گیری کرد.
اولاً، از آنجایی که ما به تفاوت بین گروه های مرتبط (نقاط زمانی) علاقه مندیم، باید تفاوت بین هر ترکیب گروه مرتبط (نقطه زمانی) را محاسبه کنیم (سه ستون آخر در جدول بالا). هر چه نقاط زمانی (یا شرایط) بیشتر باشد، تعداد ترکیبهای ممکن بیشتر میشود. برای سه نقطه زمانی، ما سه ترکیب مختلف داریم. سپس باید واریانس هر گروه را محاسبه کنیم، که دوباره در جدول بالا ارائه شده است.
با نگاهی به نتایج ما، در نگاه اول، به نظر می رسد که واریانس بین تفاوت های دو نقطه زمانی برابر نیست (13.9 در مقابل 17.4 در مقابل 3.1). واریانس تفاوت بین زمان 2 و زمان 3 (Time3-Time2) بسیار کمتر از دو ترکیب دیگر است.
این ممکن است ما را به این نتیجه برساند که داده های ما فرض کروی بودن را نقض می کند.
با این حال، ما میتوانیم دادههای خود را برای کرویت با استفاده از یک آزمون رسمی به نام آزمون کرویت موچلی (Mauchly’s Test of Sphericity) آزمایش کنیم.
آزمون کرویت موچلی
همانطور که قبلاً ذکر شد، آزمون کرویت موچلی روشی رسمی برای آزمایش فرض کرویت است.
اگرچه این آزمایش به شدت مورد انتقاد قرار گرفته است، اما اغلب در تشخیص انحراف از کرویت در نمونههای کوچک و تشخیص بیش از حد آنها در نمونههای بزرگ شکست خورده است، با این وجود این یک آزمون رایج است.
این احتمالاً به دلیل چاپ خودکار آن در SPSS برای ANOVA اندازه گیری های مکرر و فقدان یک آزمون در دسترس است. اما با وجود این کاستی ها به دلیل پرکاربرد بودن آن در این قسمت به توضیح آزمون و نحوه تفسیر آن می پردازیم.
آزمون کروی بودن Mauchly این فرضیه صفر را آزمایش می کند که واریانس تفاوت ها برابر است.
بنابراین، اگر آزمون کرویت موچلی از نظر آماری معنیدار باشد (p<0.05)، میتوانیم فرضیه صفر را رد کنیم و فرضیه جایگزین را بپذیریم که واریانسهای تفاوتها برابر نیستند (یعنی کرویت نقض شده است). نتایج حاصل از آزمون کرویت Mauchly در زیر برای دادههای مثال ما نشان داده شده است (بخش قرمز زیر را ببینید):
نتایج این آزمایش نشان می دهد که کرویت نقض نشده است (p = 0.188) (شما باید زیر ستون “Sig.” را نگاه کنید).
بنابراین میتوانیم نتیجه آزمایش کرویت موچلی را به صورت زیر گزارش کنیم:
آزمون کروی بودن Mauchly نشان داد که فرض کروی بودن نقض نشده است
ممکن است متوجه اختلاف بین نتیجه آزمون کرویت موچلی شده باشید، که نشان میدهد فرض کرویت نقض نمیشود و در حالی که تفاوتهای زیاد در واریانسهای محاسبهشده قبلی (13.9 در مقابل 17.4 در مقابل 3.1)، نشاندهنده نقض فرض کرویت بود.
متأسفانه این یکی از مشکلات آزمون Mauchly در برخورد با حجم نمونه کوچک است که قبلاً به آن اشاره شد.
اگر دادههای شما فرض کروی بودن را نقض نمیکند، نیازی به تغییر درجه آزادی خود ندارید. [اگر از SPSS استفاده میکنید، نتایج شما در ردیف(های) «کرویت فرضی» (sphericity assumed) ارائه میشود.] نقض نکردن این فرض به این معنی است که آماره F (F-statistic) که محاسبه کردهاید معتبر است و میتوان از آن برای تعیین معنیداری آماری استفاده کرد.
با این حال، اگر فرض کروی بودن نقض شود، آماره F دارای سوگیری مثبت است و آن را نامعتبر می کند و خطر خطای نوع I را افزایش می دهد.
برای غلبه بر این مشکل، اصلاحاتی باید در درجات آزادی (df) اعمال شود، به طوری که بتوان یک F-value بحرانی معتبر به دست آورد. لازم به ذکر است که مشاهده اینکه کرویت نقض شده است غیر معمول نیست.
اصلاحاتی که برای مبارزه با نقض فرض کروی بودن با آنها مواجه خواهید شد، تخمین کران پایین (lower-bound estimate)، تصحیح گرینهاوس-گیسر (Greenhouse–Geisser correction) و تصحیح هیون-فلدت (Huynh–Feldt correction) است. این اصلاحات به تخمین کرویت بستگی دارد.
تخمین کرویت (ε) و نحوه کار اصلاحات
درجه ای که کرویت وجود دارد یا نه، با آماره ای به نام اپسیلون (ε) نشان داده می شود.
اپسیلون 1 (یعنی ε=1) نشان می دهد که شرط کروی بودن دقیقاً برآورده شده است.
هرچه اپسیلون بیشتر به زیر 1 کاهش یابد (یعنی ε<1)، نقض کرویت بیشتر می شود.
بنابراین، میتوانید اپسیلون را بهعنوان آماری در نظر بگیرید که میزان نقض کرویت را توصیف میکند.
کمترین مقداری که اپسیلون (ε) می تواند بگیرد، تخمین کران پایین نامیده می شود. هر دو روش Greenhouse–Geisser و Huynh–Feldt تلاش می کنند اپسیلون (ε) را تخمین بزنند، البته به روش های مختلف (این یک تخمین است زیرا ما با نمونه ها سر و کار داریم، نه جمعیت). به همین دلیل، تخمین کرویت (ε) بسته به اینکه کدام روش استفاده می شود، همیشه متفاوت است.
از تخمین کرویت (ε) برای تصحیح درجات آزادی برای توزیع F استفاده میکنند. همانطور که در ادامه این آموزش خواهید دید، مقدار واقعی آماره F در نتیجه اعمال اصلاحات تغییر نمی کند.
پس اصلاحات بر درجات آزادی چه تأثیری دارد؟
پاسخ به این در نحوه محاسبه مقادیر بحرانی برای آماره F نهفته است. اصلاحات بر درجات آزادی توزیع F تأثیر می گذارد، به طوری که از مقادیر بحرانی بزرگتر استفاده می شود (به عنوان مثال، مقدار p افزایش می یابد). این برای مقابله با این واقعیت است که وقتی فرض کرویت نقض می شود، به دلیل کوچک بودن مقادیر بحرانی در جدول F، خطاهای نوع I افزایش می یابد.
به یاد داشته باید که درجات آزادی مورد استفاده در محاسبه آماره F در ANOVA اندازه گیری های مکرر عبارتند از:
که در آن k = تعداد اقدامات تکرار شده و n= تعداد سوژه ها است.
سه تصحیح تخمین lower-bound، تصحیح Greenhouse–Geisser و تصحیح Huynh–Feldt به صورت زیر همگی با ضرب این درجات آزادی در اپسیلون تخمینی آنها(ε) ، درجات آزادی را تغییر می دهند:
لطفاً توجه داشته باشید که اصلاحات مختلف از نمادهای ریاضی متفاوتی برای اپسیلون تخمینی (ε) استفاده میکنند که در ادامه نشان داده خواهد شد.
همچنین به یاد داشته باشید که آماره F به صورت زیر محاسبه می شود:
همانطور که قبلاً گفته شد، این اصلاحات منجر به یک آمار F متفاوت نمی شود. اما چگونه زمانی که درجات آزادی در حال تغییر است، آمار F بدون تغییر باقی میماند؟
این به این دلیل است که اپسیلون تخمین زده شده به عنوان ضریب درجات آزادی هم برای صورت و هم برای مخرج اضافه می شود و بنابراین آنها یکدیگر را خنثی می کنند، همانطور که در زیر نشان داده شده است:
برای مثال، ما سه تخمین اپسیلون (ε) را داریم که به صورت زیر محاسبه شده است (با استفاده از SPSS):
تخمین کران پایین (lower-bound estimate)
کمترین مقداری که اپسیلون (ε) می تواند بگیرد، تخمین کران پایین (یا تنظیم کران پایین) نامیده می شود و به صورت زیر محاسبه می شود:
که در آن k = تعداد اقدامات تکراری است. همانطور که از معادله بالا می بینید، هر چه تعداد اقدامات تکراری بیشتر باشد، احتمال نقض کرویت بیشتر است. بنابراین، برای مثال ما که دارای سه اندازه گیری مکرر است، کمترین مقدار اپسیلون (ε) می تواند باشد:
این نشان دهنده بزرگترین نقض ممکن کرویت است. بنابراین، استفاده از lower-bound estimate به این معنی است که شما درجات آزادی خود را برای “بدترین سناریو” تصحیح می کنید. این اصلاحی را ارائه می دهد که بسیار محافظه کارانه است (به اشتباه فرضیه صفر را رد می کند). این اصلاح با اصلاحات Greenhouse–Geisser و Huynh–Feldt جایگزین شده است. بنابراین تخمین کران پایین دیگر اصلاح توصیه شده نیست.
به منظور تصحیح درجات آزادی توزیع F همانطور که قبلاً ذکر شد، روش Greenhouse–Geisser اپسیلون را تخمین می زند (به عنوان اپسیلون تخمین Greenhouse–Geisser) و در زیر نشان داده شده است:
با استفاده از مثال قبلی، و اگر کرویت نقض شده بود، خواهیم داشت:
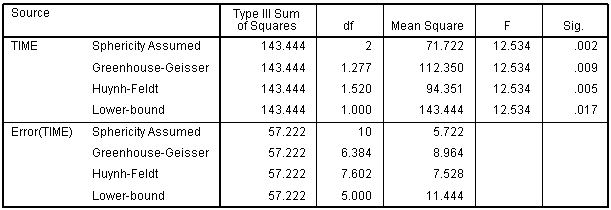
بنابراین نتیجه آزمون F ما از F(2،10)=12.534، p=0.002 تا F(1.277،6.384) =12.534، p=0.009 تصحیح می شود (درجه آزادی به دلیل گرد کردن کمی متفاوت است). این اصلاح ارزش معناداری دقیق تری را به دست آورده است. مقدار p را برای جبران این واقعیت افزایش داده است که وقتی کرویت نقض می شود، آزمون بیش از حد آزاد است.
تصحیح هیون-فلدت (Huynh–Feldt correction)
همانند تصحیح Greenhouse–Geisser، تصحیح Huynh–Feldt، اپسیلون را تخمین می زند (به عنوان اپسیلون تخمین هویند-فلد نشان داده می شود) تا درجات آزادی توزیع F را تصحیح کند.
با استفاده از مثال قبلی، و اگر کرویت نقض شده بود، خواهیم داشت:
بنابراین نتیجه آزمون F، از F(2،10)=12.534، p=0.002 تا F(1.520،7.602)=12.534، p=0.005 تصحیح می شود (درجه آزادی به دلیل گرد شدن کمی متفاوت است). همانند تصحیح Greenhouse–Geisser، این تصحیح ارزش اهمیت دقیق تری را به دست آورده است. مقدار p را برای جبران این واقعیت افزایش داده است که وقتی کرویت نقض می شود، آزمون بیش از حد آزاد است.
تصحیح Greenhouse–Geisser در مقابل Huynh–Feldt
زمانی تصحیح Greenhouse–Geisser تمایل به دست کم گرفتن اپسیلون (ε) دارد که اپسیلون (ε) نزدیک به 1 باشد (یعنی یک تصحیح محافظه کارانه است)، در حالی که تصحیح Huynh–Feldt تمایل دارد اپسیلون (ε) را بیش از حد تخمین بزند (یعنی، یک تصحیح لیبرال تر و آزادتر است). به طور کلی، توصیه می شود از تصحیح Greenhouse–Geisser استفاده کنید، به خصوص اگر اپسیلون تخمینی (ε) کمتر از 0.75 باشد. با این حال، برخی از آماردانان استفاده از تصحیح Huynd-Feldt را در صورتی که اپسیلون تخمینی (ε) بزرگتر از 0.75 باشد، توصیه می کنند. در عمل، هر دو تصحیح اصلاحات بسیار مشابهی ایجاد می کنند، بنابراین اگر اپسیلون تخمینی (ε) بزرگتر از 0.75 باشد، می توانید استفاده از هر دو تصحیح را توجیه کنید.
تفسیر پرینت های آماری (Statistical Printouts)
برای مشاهده عملی همه موارد فوق، مجموعه داده هایی را که برای این مقاله استفاده کرده ایم در نظر بگیرید. ما میتوانیم در جدول قبلی ببینیم که برای مجموعه دادههای ما، اپسیلون تخمینی (ε) با استفاده از روش Greenhouse–Geisser 0.638 است (یعنی اپسیلون برآورد Greenhouse–Geisser = 0.638). جدول زیر خروجی ANOVA اندازه گیری های مکرر ما (در SPSS) را نشان می دهد:
خروجی SPSS اندازه گیری های مکرر ANOVA – کرویت
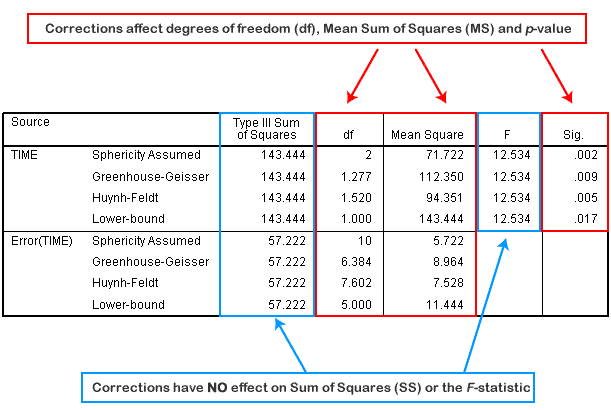
در SPSS، ردیف(های) Sphericity Assumed “کرویت فرضی” جایی است که کرویت نقض نشده است، و بنابراین، نشان دهنده محاسبات عادی است که ما برای محاسبه یک مقدار اهمیت برای ANOVA اندازه گیری های مکرر انجام می دهیم. توجه کنید که چگونه مجموع مربع ها و آماره F بدون در نظر گرفتن اینکه کدام تصحیح اعمال شده است یا خیر یکسان هستند (در شکل زیر با رنگ آبی نشان داده شده است). این بیشتر نشان میدهد که اصلاحات برای تقسیم مجموع مربعها اعمال نمیشوند، بلکه در درجههای آزادی اعمال میشوند.
در نمودار بالا می بینیم که اصلاحات درجات آزادی (df) را تغییر داده است، که به نوبه خود میانگین مجموع مربعات (Mean Sum of Squares) (MS) را هم برای عامل TIME و هم برای خطای آن (Error(TIME)) تغییر داده و سطح معنی داری، آماره F را تغییر داده است.
تحلیل تک متغیره (Univariate) در مقابل تحلیل چند متغیره (Multivariate)
یک روش جایگزین استفاده از MANOVA به جای ANOVA اندازه گیری های مکرر است. دلیل انجام این کار این است که MANOVA به فرض کروی بودن نیاز ندارد. دلایل مختلفی برای انتخاب MANOVA به جای ANOVA اندازه گیری های مکرر و بالعکس وجود دارد،.
آزمون اپسیلون گرین هاوس در مقایسه با سایر آزمونهای مشابه چه محدودیتهایی دارد؟
آزمون اپسیلون گرین هاوس هرچند که در تحلیل طرحهای تکراری بسیار مفید است، اما نیز محدودیتهایی دارد. برخی از محدودیتهای این آزمون عبارتند از:
مقاله و پایان نامه نویسی پیشرفته
فرض زمینهای یکسانی (Sphericity assumption): آزمون اپسیلون گرین هاوس برای اصلاح آزمون فون در طرحهای تکراری، به فرض زمینهای یکسانی نیاز دارد. این فرض به معنای برابر بودن واریانسهای تفاوتها بین دو شرایط تکراری است. اگر این فرض برقرار نباشد، نتایج آزمون اپسیلون گرین هاوس ممکن است نادرست باشد. حساسیت به تعداد شرایط تکراری: آزمون اپسیلون گرین هاوس به تعداد شرایط تکراری حساس است. در صورتی که تعداد شرایط تکراری کم باشد، دقت و قدرت آماری آزمون کاهش مییابد. محدودیتهای نمونهبرداری: همانند سایر آزمونهای طرحهای تکراری، آزمون اپسیلون گرین هاوس نیازمند تعداد نمونههای کافی است. در صورتی که تعداد نمونهها کم باشد، دقت و قدرت آماری آزمون کاهش مییابد.
خدمات تخصصی پژوهش و تحلیل داده های آماری با مناسبترین قیمت و کیفیت برتر!
کیفیت بالا، قیمت مناسب و خدماتی که به نیازهای شما پاسخ میدهند!
با ما همراه باشید و پروژهی خود را به یک تجربهی موفق تبدیل کنید.
پیچیدگی محاسباتی: آزمون اپسیلون گرین هاوس نیاز به محاسبات مربوط به تخمین پارامتر اپسیلون دارد. این محاسبات ممکن است پیچیده باشند و نیازمند دانش آماری مناسب باشند. تأثیر اندازه نمونه: همانند سایر آزمونهای طرحهای تکراری، اندازه نمونه در آزمون اپسیلون گرین هاوس نقش مهمی در قدرت آماری و قابلیت تشخیص تفاوتها دارد. اندازه نمونه باید به اندازه کافی بزرگ باشد تا تفاوتها را بهطور قابل توجهی تشخیص دهد. در نهایت، همواره توجه به محدودیتها و شرایط مربوطه و مشاوره از یک آماردان ماهر در انتخاب آزمون مناسب برای تحلیل دادههای تکراری بسیار حائز اهمیت است.
چه عواملی بر انتخاب آزمون اپسیلون گرین هاوس در تحلیل دادههای تکراری تأثیر میگذارند؟
در انتخاب آزمون اپسیلون گرین هاوس برای تحلیل دادههای تکراری، عوامل زیر تأثیرگذار هستند:
نوع طرح تجربی: آزمون اپسیلون گرین هاوس برای طرحهای تجربی با متغیرهای مکرر (repeated measures) مناسب است. این طرحها شامل آزمایشهایی هستند که هر شرکت کننده در آنها به طور مکرر در طول زمان یا شرایط مختلف اندازهگیری میشود.
پایان نامه – مقاله نویسی
فرض صفر: آزمون اپسیلون گرین هاوس برای بررسی فرض صفر استفاده میشود که میانگینها در تمامی گروهها یکسان هستند. اگر شما به دنبال بررسی تفاوتهای معنادار بین میانگین گروهها هستید، این آزمون مناسب خواهد بود.
وابستگی دادهها: آزمون اپسیلون گرین هاوس برای مدلهای آماری استفاده میشود که وابستگی بین دادهها را در نظر میگیرند. این آزمون برای تحلیل طرحهای تکراری که دادهها در آنها همبسته هستند، مناسب است.
تداخل زمینهای: اگر در طرح تجربی شرایط زمینهای وجود دارد که میتواند تأثیری بر نتایج آزمون داشته باشد، آزمون اپسیلون گرین هاوس میتواند به عنوان یک روش مناسب جهت کنترل و تصحیح تداخل زمینهای استفاده شود.
توجه داشته باشید که انتخاب آزمون مناسب بر اساس ویژگیهای دادهها و سوال تحقیق انجام میشود. برای تحلیل دقیقتر و انتخاب آزمون، همواره مشاوره از یک آماردان متخصص توصیه میشود.
آزمون اپسیلون گرین هاوس (Greenhouse-Geisser Epsilon test) یک روش آماری است که در تجزیه و تحلیل طرحهای طبقهبندیشده با متغیرهای مکرر (repeated measures) استفاده میشود. این آزمون برای بررسی تفاوتهای معنادار بین میانگین گروهها در طرحهای تجربی با تکرارهای بیش از یکی مورد استفاده قرار میگیرد.
در طرحهای تجربی با متغیرهای مکرر، هر شرکت کننده در آزمایش به طور مکرر در طول زمان یا شرایط مختلف اندازهگیری میشود. مثالهایی از این نوع طرحها شامل آزمایشهایی است که در طول زمان انجام میشوند و نتایج بازه زمانیهای مختلف را نشان میدهند یا آزمایشهایی که در شرایط متغیری مانند دما یا فشار انجام میشوند و تأثیر این متغیرها روی نتایج را بررسی میکنند.
آزمون اپسیلون گرین هاوس برای بررسی فرض صفر استفاده میشود که میانگینها در تمامی گروهها یکسان هستند. این آزمون به منظور بررسی تفاوت معنادار بین میانگین گروهها در طرحهای تجربی تکراری، از طریق اصلاح ماتریس کوواریانس استفاده میکند. ماتریس کوواریانس نشان میدهد که چقدر دادهها در هر گروه با هم مرتبط هستند.
چگونه فایل اکسل را غیر قابل ویرایش کنیم
آزمون اپسیلون گرین هاوس تخمینی از معنیدار بودن تفاوت بین گروهها را ارائه میدهد و با استفاده از یک پارامتر به نام “اپسیلون”، تغییراتی را در واریانس دادهها اعمال میکند. این پارامتر به منظور تصحیح آزمون فون در طرحهای تکراری استفاده میشود و هدف آن افزایش قدرت آماری آزمون است.
به طور خلاصه، آزمون اپسیلون گرین هاوس برای بررسی تفاوتهای معنادار بین میانگین گروهها در طرحهای تجربی با تکرارهای بیش از یکی استفاده میشود و با استفاده از اصلاح ماتریس کوواریانس و پارامتر اپسیلون، تاثیر تغیرات واریانس دادهها را در آزمونهای فون کاهش میدهد.
آزمون اپسیلون حد پایین یا Low-bound Test یکی از آزمونهای آماری است که برای بررسی فرضیههای مرتبط با حداقل یکنواختی در توزیع استفاده میشود. این آزمون برای بررسی این فرضیه استفاده میشود که توزیع دادهها در یک بازه مشخص، حداقل یکنواخت است.
فرض صفر در آزمون اپسیلون حد پایین این است که توزیع دادهها در بازه مورد نظر، حداقل یکنواخت نیست و دارای حداقل یک نقطه ناهمگن است. در صورت رد فرض صفر، نشان داده میشود که توزیع دادهها حداقل یکنواخت در بازه مشخص است.
نحوه انجام آزمون اپسیلون حد پایین به این صورت است که با استفاده از دادههای مشاهده شده، مقداری به نام اپسیلون را محاسبه میکنند. اپسیلون نشان میدهد که چقدر دادهها میتوانند از یکنواختی بازه مشخص (یا حداقل یکنواختی) خارج شوند. سپس، با استفاده از روشهای آماری، احتمال این که دادهها به طور تصادفی از توزیع یکنواخت خارج شوند و اپسیلون محاسبه شده را به دست آورده و با یک مقدار آستانه مقایسه میکنند. اگر مقدار اپسیلون محاسبه شده از آستانه مشخص کمتر باشد، فرض صفر رد میشود و نتیجه میگوید که دادهها حداقل یکنواخت در بازه مشخص هستند.
آزمون اپسیلون حد پایین معمولاً در زمینههایی مانند پردازش تصویر، آشکارسازی ناهنجاریها و تحلیل سیگنالها مورد استفاده قرار میگیرد.
سفارش تحلیل داده های آماری برای پایان نامه و مقاله نویسی
تحلیل داده های آماری شما با نرم افزارهای کمی و کیفی ،مناسب ترین قیمت و کیفیت عالی انجام می گیرد.
نرم افزار های کمی: SPSS- PLS – Amos
نرم افزارهای کیفی: Maxquda- NVivo
تعیین حجم نمونه با:Spss samplepower
Mobile : 09143444846 09143444846
Telegram: https://t.me/RAVA2020
E-mail: abazizi1392@gmail.com
چه عواملی در انتخاب نوع آزمون آماری مناسب باید در نظر گرفته شود؟
در انتخاب نوع آزمون آماری مناسب، عوامل زیر را باید در نظر گرفت:
هدف تحقیق: نوع آزمون آماری بستگی به هدف تحقیق دارد. آیا قصد بررسی تفاوت بین دو گروه، بررسی تأثیر یک متغیر بر متغیر دیگر، مقایسه بیش از دو گروه یا بررسی رابطه بین دو متغیر را دارید؟ با تعیین هدف تحقیق، می توانید نوع آزمون آماری مناسب را انتخاب کنید. نوع دادهها: نوع دادههای جمعآوری شده نیز تعیین کننده نوع آزمون آماری است. آیا دادهها از نوع عددی هستند (مانند میانگین و انحراف معیار)، دادههای رتبهای (مانند آزمون رتبه ویلکاکسون)، دادههای دستهای (مانند آزمون کای-دو) یا دادههای دستهای مرتبهای (مانند آزمون کروسکال-والیس) هستند؟ نوع دادهها تعیین کننده نوع آزمون آماری است. تعداد گروهها یا متغیرها: اگر قصد مقایسه بیش از دو گروه یا بررسی تأثیر بیش از دو متغیر را دارید، آزمونهای چندگانه مانند آزمون ANOVA یا آزمون همبستگی چندگانه را باید در نظر بگیرید. در غیر این صورت، آزمونهای دوگانه مانند آزمون t یا آزمون کای-دو مناسب خواهند بود. فرضیات تحقیق: فرضیاتی که در تحقیق بررسی میشوند، نوع آزمون آماری را تعیین میکنند. آیا قصد دارید فرض صفر را رد کنید و فرض جایگزین را تأیید کنید؟ یا فرض صفر را قبول کنید و تفاوت یا ارتباطی معنادار وجود ندارد؟ وجود فرض صفر و فرض جایگزین و جهت آنها (دوطرفه یا یکطرفه) تعیین کننده نوع آزمون آماری است. سطح اهمیت (معناداری): سطح اهمیت مشخص میکند چقدر مقدار آمار آزمون باید از حدی که برای رد فرض صفر لازم است، دور باشد تا فرض صفر را رد کنیم. این سطحاهمیت به عنوان آلفا (α) شناخته میشود. معمولاً مقدار آلفا را 0.05 (یا 5٪) استفاده میکنند، که به معنای قبول خطای 5٪ است. با تعیین سطح اهمیت، میتوانید نوع آزمون آماری مناسب را انتخاب کنید، زیرا برخی آزمونها برای سطحهای اهمیت مختلف طراحی شدهاند. نمونهبرداری: نوع آزمون آماری ممکن است بستگی به نحوه نمونهبرداری داشته باشد. آیا نمونهها به طور تصادفی و مستقل انتخاب میشوند؟ آیا نمونهها از توزیع نرمال پیروی میکنند؟ این عوامل میتوانند تأثیری در انتخاب نوع آزمون آماری داشته باشند. قدرت آزمون: قدرت آزمون نشان میدهد که آیا آزمون قادر به شناسایی تفاوت یا ارتباط واقعی است یا خیر. قدرت آزمون معمولاً باید بالاترین مقدار ممکن (معمولاً بیش از 80٪) باشد. در انتخاب نوع آزمون آماری، باید توجه داشته باشید که آیا آزمون انتخاب شده قدرت کافی برای تشخیص تفاوت یا ارتباط واقعی دارد یا خیر.
ما در این سایت پرسشنامه های استاندارد (دارای روایی، پایایی، روش دقیق نمره گذاری ، منبع داخل و پایان متن ) ارائه می کنیم و همچنین تحلیل آماری کمی و کیفی رابا قیمت بسیار مناسب و کیفیت عالی و تجربه بیش از 17 سال انجام می دهیم. برای تماس به ما به شماره 09143444846 در شبکه های اجتماعی پیام بفرستید. ایمیلabazizi1392@gmail.com
تمامی حقوق مادی و معنوی این سایت متعلق به لنسرسرا و محفوظ است.
این سایت دارای مجوز می باشد







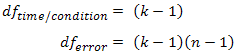




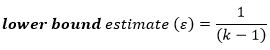

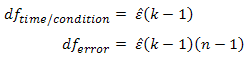

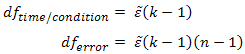


 با تجربهی بیش از 17 سال و ارائهی بهترین خدمات
با تجربهی بیش از 17 سال و ارائهی بهترین خدمات


 با ما در ارتباط باشید:
با ما در ارتباط باشید: تماس: 09143444846 (پیامک، ایتا، واتساپ، تلگرام)
تماس: 09143444846 (پیامک، ایتا، واتساپ، تلگرام) کانال تلگرام:
کانال تلگرام:  کیفیت بالا، قیمت مناسب و خدماتی که به نیازهای شما پاسخ میدهند!
کیفیت بالا، قیمت مناسب و خدماتی که به نیازهای شما پاسخ میدهند!






