...........................................................................................................................................................................................................................................................................................................................................................................
خوش آمدید این سایت دارای مجوز می باشد برای مشاهده مجوز ها پایین صفحه را مشاهده فرمائید.
در تحلیل عاملی تأییدی، مدل پیشفرضی از ساختار عاملی تعریف میشود و سپس میزان مطابقت بین دادههای مشاهده شده و مدل پیشفرض مورد بررسی قرار میگیرد. معمولاً در این روش، فرضیهها و روابط میان متغیرها از قبل تعیین شده و تحلیل بر اساس این فرضیهها انجام میشود. هدف اصلی تحلیل عاملی تأییدی، تأیید یا رد کردن یک مدل پیشفرض است و بررسی مطابقت دادهها با ساختار پیشفرض را در نظر دارد. در این روش، از معیارهای آماری مختلفی مانند بارهای عاملی، ضرایب مسیر، و شاخصهای مطابقت استفاده میشود. تحلیل عاملی اکتشافی (Exploratory Factor Analysis – EFA):
در تحلیل عاملی اکتشافی، هدف اولیه تشکیل و تعریف ساختار عاملی از متغیرها است، بدون داشتن فرضیههای خاص در مورد روابط بین متغیرها. در این روش، سعی میشود الگوهای پنهان و ساختار پنهان را در دادههای مشاهده شده شناسایی کنیم. تحلیل عاملی اکتشافی معمولاً با هدف کاهش ابعاد دادهها و یافتن عوامل یا مفاهیم پنهان در پس از متغیرها انجام میشود. با استفاده از تحلیل عاملی اکتشافی، میتوانیم متغیرها را در عواملی یا مفاهیم بزرگتر تجزیه و تحلیل کنیم و ساختار پنهان را بررسی کنیم. تفاوت اصلی بین تحلیل عاملی تأییدی و اکتشافی در هدف و رویکرد آنها است. تحلیل عاملی تأییدی بر روی یک مدل پیشفرض کار میکند و به تأیید یا رد کردن این مدل و مطابقت دادهها با آن میپردازد. اما تحلیل عاملی اکتشافی بدون فرضیه خاصی از قبل، سعی در شناسایی الگوها و ساختار پنهان در دادهها دارد و به ما کمک میکند تا عوامل یا مفاهیم پنهان در دادهها را شناسایی کنیم و ساختار پنهان را بررسی کنیم.
به متغیر تعدیل کننده گاهی متغیر مستقل فرعیگفته می شود.
متغیر تعدیلگر یک متغیر کمی یا کیفی است که جهت و قدرت رابطه متغیر مستقل و وابسته را تحت تاثیر قرار میدهد.
برای نمونه متغیر عزت نفس در بررسی رابطه فرسودگی شغلی و مدیریت زمان یک متغیر تعدیل کننده است.
حال در نظر بگیرید که اثر تعدیل گری عزت نفس منفی و معنی دار باشد باید به صورت زیر آن را تفسیر کنیم.
عزت نفس بر شدت تأثیر متغیرفرسودگی شغلی بر مدیریت زمان اثر منفی و معکوس دارد . لذا در افرادی که عزت نفس آن ها بالا هست، فرسودگی شغلی کمتر می تواند بر مدیریت زمان تأثیر بگذارد ولی در افرادی که عزت نفس آن ها پایین هست، فرسودگی شغلی بیشتر می تواند بر مدیریت زمان تأثیر بگذارد.
بنابراین عزت نفس ، رابطه فرسودگی شغلی و مدیریت زمان را تعدیل میکند.
انواع متغیر تعدیلکننده و روش محاسبه آن
بارون و کنی (۱۹۸۶) در مقاله خود چهار حالت گوناگون از وضعیت متغیر مستقل و تعدیلگر را به شرح زیر بررسی کردند:
حالت اول: متغیر مستقل و تعدیلگر هر دو از نوع طبقهای (اسمی-رتبهای) باشند.
حالت دوم: متغیر تعدیلگر از نوع طبقهای و متغیر مستقل پیوسته باشد.
حالت سوم: متغیر تعدیلگر پیوسته و متغیر مستقل از نوع طبقهای باشد.
حالت چهارم: هر دو متغیر تعدیلگر و مستقل پیوسته باشند.
در حالت اول برای مثال بخواهید نقش جنسیت را در تاثیر سمت سازمانی بر رضایت شغلی ارزیابی کنید در این حالت میتوانید از تحلیل واریانس دوراهه استفاده کنید.
حالت دوم بیشترین کاربرد را مطالعات مدیریت دارد. برای مثال بخواهید نقش جنسیت را در رابطه اعتماد و رضایت شغلی بسنجید. جنسیت یک متغیر طبقهای است و اعتماد و رضایت متغیرهای پیوسته میباشند. در این حالت میتوانید از روش محاسبه اثر تعدیلگر با رگرسیون خطی استفاده کنید.
برای محاسبه حالت سوم پیشنهادی ندارم زیرا رویه مرسومی نیست ولی برای حالت چهارم میتوانید از محاسبه متغیر تعدیلگر با روش رگرسیون هایس استفاده کنید.
متغیر تعدیلکننده و رگرسیون سلسلهمراتبی
رگرسیون سلسلهمراتبی یا ترتیبی این امکان را فراهم میآورد که تاثیر چند متغیر مستقل بر یک متغیر وابسته طی چند مرحله مشخص شود. از رگرسیون سلسلهمراتبی برای بررسی نقش متغیرهای تعدیلگر براساس رویه پیشنهادی بارون و کنی استفاده کرد.
اگر پرسشنامهای با طیف لیکرت استفاده میکنید تمامی سازههایی که توسط چندین گویه مورد سنجش قرار میگیرند باید به یک شاخص قابل مشاهده تبدیل میشوند. برای این کار میانگین گویههای سنجش آنها را محاسبه کنید.
این آموزش ها رایگان می باشند و هزینه ای بابت آن ها دریافت نمی شود.
فقط انتظاری که از کاربران محترم داریم این است که پیشنهادهای خود را ارائه کنند، برایمان دعای خیر کنند، ما را به دیگران معرفی کنند و در نهایت از محصولات پولی ما خریداری کنند! با تشکر
با توسعه فناوری و افزایش دانش، ابزارهای نوینی برای جمعآوری، توصیف، تحلیل، انتقال و ارائه اطلاعات توسط دانشپژوهان تولید شدهاند.
به عبارت دیگر، روشهای تحقیق نیز در حال تکامل و توسعه هستند. بنابراین، آگاهی یافتن از روشهای تحقیق و انجام تحلیلهای آماری ضروری است برای محققان، استادان و دانشجویان.
پژوهشگر برای پاسخگویی به مسئله تدوین شده و یا تصمیمگیری در مورد رد یا تایید فرضیه یا فرضیاتی که برای تحقیق در نظر گرفته است، از روشهای مختلف تجزیه و تحلیل استفاده میکند. همانطور که میدانید، هر مسئله نیازمند شیوه مطالعه و تحقیق خود را دارد.
بخش عمدهای از فعالیتهای علمی دانشجویان در دورههای تحصیلات تکمیلی، کارشناسی ارشد و دکتری، به انجام تحقیقات علمی و ارائه آنها به صورت گزارش، سمینار، پایاننامه و مقاله مربوط میشود. در این مطلب به طور خلاصه به بررسی و شرح بخشی از فرآیند تحقیق در زمینه تحلیل دادهها و روشهای آماری میپردازیم. همچنین با روشهای انجام تجزیه و تحلیل آماری آشنا خواهید شد. از آنجا که بیشتر پژوهشهای انجام شده در دانشگاهها جنبه کمی دارند، بنابراین یادگیری روشهای آماری، به ویژه آمار استنباطی، توصیه میشود. بدیهی است که برای این کار لازم است که دانشجویان و علاقمندان به یادگیری، نحوه استفاده از نرمافزارهای آماری و به ویژه انجام تحلیل آماری با SPSS اقدام کنند. برای یادگیری کار با این نرمافزار، لطفاً مقاله آموزش تحلیل آماری با SPSS را مطالعه فرمایید. در پایان این نوشتار، به معرفی آزمونهای آماری، آزمونهای پارامتریک و آزمونهای ناپارامتریک خواهیم پرداخت.
آمار توصیفی: آمار توصیفی به توضیح و تحلیل دادهها پرداخته و میتواند به ترتیب ارقامی بدون معنی که از آمار استفاده میشود، اطلاعات را معنادار کند تا اهداف پژوهشی و تحقیقات برآورده شوند. این به معنای اساسی هر مطالعه و پژوهش است که تمامی فعالیتهای تحقیقی را تا رسیدن به یک نتیجه، کنترل و هدایت میکند. نحوههای مختلف تجزیه و تحلیل برای دستیابی به پاسخگویی به مسئله تدوین شده و یا تصمیمگیری در مورد رد یا تایید فرضیه یا فرضیاتی که برای تحقیق در نظر گرفته شده است، استفاده میشود. به عبارت دیگر، هر مسئله نیازمند شیوه مطالعه و تحقیق خود است.
عناصر اساسی در تجزیه و تحلیل دادهها:
دادههای جمعآوری شده باید با دقت جمعآوری و ثبت شوند.
دادههای نقدی که توسط آمار معنادار میشوند، باید تجزیه و تحلیل شوند. (بازبینی دادههای جمعآوری شده)
باید اطمینان حاصل شود که دادههای جمعآوری شده به صحت و کیفیت مطلوب رسیدهاند.
دادههای جمعآوری شده را در قالب و فرمت یکنواخت ذخیره کنید.
در صورت وجود سوالات بدون پاسخ، باید آنها تکمیل شوند.
اگر پاسخهای سوالات با یکدیگر سازگار نیستند، علت این موضوع باید بررسی شود و پرسشنامه اصلاح شود.
پس از در دست داشتن دادههای صحیح و با کیفیت، اقدام به استفاده از آمار و انجام تجزیه و تحلیل خواهیم نمود.
مراحل کنگره دادهها: الف) مراحل کردن و تنظیم دادهها ب) کدگذاری دادهها ج) سازماندهی دادهها مراحل کردن و تنظیم دادهها: برای تحلیل دادهها، دادههای جمعآوری شده را میبایست انجام کدینگ و تنظیم دهیم، به شکلی که دادههای نقدی را مشخص و مرتب کنیم. روشهای تحلیل آماری در برابر دادههای نقدی انجام میشود. روشهای تحلیل آماری را میتوان به دو شاخه توصیفی و استنباطی تقسیم کرد.
آمار توصیفی: آمار توصیفی به توضیح و تحلیل دادهها پرداخته و میتواند به ترتیب ارقامی بدون معنی که از آمار استفاده میشود، اطلاعات را معنادار کند تا اهداف پژوهشی و تحقیقات برآورده شوند. این به معنای اساسی هر مطالعه و پژوهش است که تمامی فعالیتهای تحقیقی را تا رسیدن به یک نتیجه، کنترل و هدایت میکند. نحوههای مختلف تجزیه و تحلیل برای دستیابی به پاسخگویی به مسئله تدوین شده و یا تصمیمگیری در مورد رد یا تایید فرضیه یا فرضیاتی که برای تحقیق در نظر گرفته شده است، استفاده میشود. به عبارت دیگر، هر مسئله نیازمند شیوه مطالعه و تحقیق خود است.
شاخصهای تمایل مرکزی: • میانگین: متوسط حسابی یک مجموعه دادهها میباشد. • نما: مقداری است که بیشترین تکرار را در مجموعه دادهها دارد. • میانه: عددی است که در وسط دادهها قرار دارد. • چارکها: چارک و صدکها مهم هستند، اما به طور کلی صدکها در مورد مجموعههای بزرگ به کار میروند.
شاخصهای پراکندگی: شاخصهای پراکندگی نشاندهنده میزان پراکندگی یا تغییراتی که در بین دادههای یک توزیع (نتایج تحقیق) وجود دارد، هستند. این شاخصها مهم هستند زیرا نشان میدهند که آیا دادهها دارای تنوع زیادی هستند یا خیر.
مثالهایی از شاخصهای پراکندگی: • واریانس: میزان انحراف اعداد از میانگین را نشان میدهد. واریانس بزرگتر به معنای تنوع بیشتر در دادهها است. • انحراف معیار: از این شاخص برای اندازهگیری انحراف اعداد از میانگین استفاده میشود. • دامنه: اختلاف بین حداکثر و حداقل دادهها را نشان میدهد. دامنه بزرگتر به معنای تنوع بیشتر است.
شاخصهای چولگی و کشیدگی: • چولگی: میزان شیب و تنگی توزیع دادهها را نشان میدهد. چولگی مثبت نشاندهنده دارا بودن دادههای بیشتر در یک طرف توزیع است و چولگی منفی نشاندهنده توزیع دادهها در طرف دیگر است. • کشیدگی (Kurtosis): اندازهگیری شکل و تیزی یا تخمین از فراوانی دادهها در دمایهای توزیع است. کشیدگی بزرگتر نشاندهنده دارا بودن دادههای زیاد در مرکز توزیع و کشیدگی کمتر نشاندهنده توزیع دادهها در دمایهای بیرونی توزیع است.
آمار استنباطی: آمار استنباطی به تفسیر، تحلیل و برداشت نتایج بر اساس نمونهگیری از یک جمعیت بزرگتر میپردازد. این نمونهگیری به این دلیل انجام میشود که ممکن است تحلیل کل جمعیت زمانبر و گرانقیمت باشد. از طریق نمونهگیری، اطلاعات زیادی از جمعیت به دست میآید و بر اساس آن نتایج برآورده میشود. در آمار استنباطی، از مفاهیمی مانند اطمیناناندازهگیری، تست فرضیهها، اندازهگیری خطا و اعتبارسنجی استفاده میشود.
مثالهایی از آمار استنباطی: • اندازهگیری اطمینان: میزان قطعیت و اعتماد ما به نتایج به دست آمده از نمونهگیری. • تست فرضیهها: بررسی فرضیههایی که در مطالعه ارائه شده و تصمیمگیری در مورد رد یا تایید آنها. • اندازهگیری خطا: تخمین خطاهای ممکن در نتایج به دست آمده از نمونهگیری. • اعتبارسنجی: بررسی اعتبار و صحت نتایج و مطالعات با استفاده از روشهای مختلف.
خواص شاخص های پراکندگی -شاخصهای پراکندگی مخصوص داده های کمی می باشد . – در شاخصهای پراکندگی همیشه عددی مثبت محاسبه می شود . -حداقل شاخصهای پراکندگی صفر می باشد و آن هنگامی است که همه داده ها برابر می باشند. برخی از مهمترین شاخص های پراکندگی عبارتند از: • دامنه تغییرات • واریانس • انحراف معیار • ضریب تغییر یا تعیین شاخص های چولگی شاخصی است که از نظر گرافیکی تقارن و یا عدم تقارن در مجموعه دیتا ها را نمایش می دهد و تقارن همیشه نسبت به میانگین است. شاخص های کشیدگی(Kurtosis) این شاخص مانند واریانس و انحراف معیار راجع به جمع شدن شکل یا پهن بودن شکل است. آمار استنباطی چیست؟ در بیشتر فعالیت های آماری جمع آوری، تنظیم و ارائه ی یافته ها و یا تعیین آماره ها کفایت نمی کند ، بلکه لازم است بر اساس این اطلاعات جمع آوری و تنظیم شده ، تجزیه و تحلیل و استنباط هایی برای تبیین و تصمیم گیری صورت گیرد .این بخش از آمار که به تحلیل ، تفسیر و تعمیم نتایج حاصل از تنظیم و محاسبه ی مقدماتی اماری تکیه دارد ، آمار استنباطی خوانده می شود .با استفاده از روش های امار استنباطی می توان مشخصات جامعه ی اماری را از روی نمونه ها استنباط کرد. ویژگی آمار تحلیلی یا استنباطیAnalytic Statistics • آمار تحلیلی به معنای تعمیم نتایج نمونه به جامعه است. • در آمار تحلیلی مفهوم ضریب اطمینان حائز اهمیت است. • ضریب اطمینان رایج در تحقیقات علوم پزشکی ۹۵% است. • بطور استثناء در موارد کم اهمیت تر از ضریب اطمینان ۹۰% و در مواردی که اهمیت زیادی دارد از ضریب اطمینان ۹۹% استفاده می شود. آمار استنباطی و آزمون فرضیه ها: بعد از توصیف متغیرها وپاسخهای بدست آمده از جامعه آماری در این بخش به بررسی فرضیه های مطرح شده و آزمون آماری مورد استفاده در پژوهش پرداخته شده است به بیان دیگر به تحلیل یافته های بدست آمده پرداخته میشود تا از نظر آماری نیز بتوان صحت و سقم فرضیات را مورد بررسی قرار داد. برای اینکه آزمون آماری مناسب، مورد استفاده در پژوهش را به درستی انتخاب کنید لطفا مقالات انتخاب صحیح آزمون های آماری را مطالعه فرمایید. آزمونهای آمار استنباطی به دو گروه تقسیم میشوند. 1. پارامتری: به تجزیه و تحلیل اطلاعات در سطح مقیاس فاصلهای و نسبی میپردازند که حداقل شاخص آماری آنها میانگین (Mean) و واریانس (Variance) است. 2. آزمونهای ناپارامتری : به تجزیه و تحلیل اطلاعات در سطح مقیاس اسمی و رتبهای میپردازند که شاخص آماری آنها میانه (Median) و نما (Mode) است. آزمونهای پارامتریک • آزمون t تک نمونه • آزمون t وابسته • آزمون t دو نمونه مستقل • آزمون t ولچ • آزمون t هتلینگ • تحلیل واریانس (ANOVA) • تحلیل واریانس چندعاملی (MANOVA) • تحلیل کوواریانس چندعاملی (MANCOVA) آزمونهای ناپارامتریک • آزمون علامت تک نمونه • آزمون علامت زوجی • ویلکاکسون • من-ویتنی • کروسکال-والیس • فریدمن • کولموگروف-اسمیرنف • آزمون تقارن توزیع • آزمون میانه • مک نمار • آزمون Q کوکران • ضریب همبستگی اسپیرمن تحلیلهای انجام گرفته در موسسه همیار پروژه دارای ویژگیهای زیر می باشد: • انجام تمام تحلیل های موجود • توضیح و تفسیر کامل برون دادها • ارائه مشاوره در حین تحلیل • استفاده از نرم افزارهای متنوع • بررسی نهایی تحلیل آماری • انجام انواع مختلف پروژه های آماری و تحلیل پایان نامه ها • انجام سفارشات تجزیه و تحلیل آماری داده های آماری بدست آمده از پرسشنامه • اطلاعات حاصل از آزمایشات و تحقیقات علمی و آنالیز آماری آنها • اجرای انواع آزمونها و روشهای آماری (اعم از آزمونهای پارامتری و ناپارامتریک) • و…
شاخصهای پراکندگی مخصوص دادههای کمی هستند و همیشه اعداد مثبت محاسبه میشوند. حداقل شاخصهای پراکندگی صفر است که در صورتی اتفاق میافتد که همه دادهها برابر باشند. این شاخصها از اهمیت زیادی برخوردارند و در تحلیل دادهها و اندازهگیری تغییرات مفید هستند. در ادامه به بررسی ویژگیهای آمار استنباطی و آزمونهای آماری پرداخته و تحلیلهایی که در موسسه همیار پروژه انجام میدهند، معرفی میشوند.
آمار استنباطی: آمار استنباطی به تفسیر، تحلیل و برداشت نتایج بر اساس نمونهگیری از یک جمعیت بزرگتر میپردازد. این نمونهگیری به این دلیل انجام میشود که ممکن است تحلیل کل جمعیت زمانبر و گرانقیمت باشد. از طریق نمونهگیری، اطلاعات زیادی از جمعیت به دست میآید و بر اساس آن نتایج برآورده میشود. در آمار استنباطی، از مفاهیمی مانند اطمیناناندازهگیری، تست فرضیهها، اندازهگیری خطا و اعتبارسنجی استفاده میشود.
آزمونهای آماری: آزمونهای آماری به دو گروه تقسیم میشوند: پارامتریک و ناپارامتریک.
آزمونهای پارامتریک از تجزیه و تحلیل اطلاعات در سطح مقیاس فاصلهای و نسبی میپردازند که حداقل شاخص آماری آنها میانگین و واریانس است. برخی از آزمونهای پارامتریک عبارتند از:
آزمون t تک نمونه
آزمون t وابسته
آزمون t دو نمونه مستقل
آزمون t ولچ
تحلیل واریانس (ANOVA)
تحلیل واریانس چندعاملی (MANOVA)
تحلیل کوواریانس چندعاملی (MANCOVA)
آزمونهای ناپارامتریک به تجزیه و تحلیل اطلاعات در سطح مقیاس اسمی و رتبهای میپردازند که شاخص آماری آنها میانه و نما است. برخی از آزمونهای ناپارامتریک عبارتند از:
تجزیه و تحلیل آماری ابزاری قدرتمند است که کسب و کارها و سازمانها، مراکز تحقیقاتی از آن برای استخراج معنا از دادهها و هدایت تصمیمگیری استفاده میکنند. انواع مختلفی از تکنیکهای تجزیه و تحلیل آماری وجود دارد که میتواند برای طیف گستردهای از دادهها، صنایع و برنامهها استفاده شود. تجزیه و تحلیل آماری شامل جمعآوری، سازماندهی و تجزیه و تحلیل دادهها بر اساس اصول ثابت شده برای شناسایی الگوها و روندها است. این یک رشته گسترده با برنامههای کاربردی در دانشگاه، کسب و کار، علوم اجتماعی، ژنتیک، مطالعات جمعیت، پزشکی، مهندسی و چندین زمینه دیگر میباشد.
به عبارتی تحلیل آماری عبارتست از گزارشی شامل جداول و نمودارهای آماری و تحلیل و تفسیر آنها، به گونه ای که تصویری روشن و توصیفی از داده ها و هم چنین استنباط های حاصل از استخراج نکات کلیدی و مدیریتی از داده ها ارائه می دهد.
روند تجزیه و تحلیل اطلاعات
در تجزیه و تحلیل آماری چندین مرحله وجود دارد اما در این قسمت به پنج مرحله مهم اشاره خواهیم کرد:
1- انتخاب جامعه هدف
جامعه آماری عبارتست از مجموعه تمام افراد، گروهها، اشیاء و یا رویدادهایی که دارای یک یا چند ویژگی مشترک باشند. تعداد اعضای جامعه را حجم یا اندازه جامعه مینامند و با حرف بزرگ N نشان میدهند.
2- انتخاب حجم نمونه
نمونه آماری گروه کوچکتری از جامعه است که طبق ضابطهای معین برای مشاهده و تجزیه و تحلیل انتخاب میشود و باید معرف جامعه باشد. نتایج نمونه ای را که معرف جامعه نباشد نمیتوان به جامعه تعمیم داد. تعداد اعضای نمونه را با حرف کوچک n نشان می دهند.
3- تمیز سازی داده( data cleaning)
پاکسازی داده ها (Data cleaning)، شامل شناسایی و رفع خطاهای احتمالی دادهها برای بهبود کیفیت آنهاست. در این فرآیند، شما دادههای «کثیف» را شناسایی، بررسی، تجزیه و تحلیل، اصلاح یا حذف میکنید تا مجموعه دادههای خود را پاکسازی کنید. دادههای کثیف به معنی ناهماهنگیها و خطاها هستند که میتوانند از هر بخش فرآیند تحقیق، مانند طراحی ضعیف، اندازه گیری غلط، ورود دادههای ناقص و… به دست آیند.
4- تجزیه و تحلیل داده ها
از آنجا که دادهها هر لحظه برجستهتر میشوند، سازمانها نیز عملکردهایی مبتنی بر داده محوری را پیش میگیرند. این میان، تجزیه و تحلیل داده، به معنای اتخاذ روشهایی برای جمعآوری اطلاعات بیشتر است. سپس این دادهها مرتب شده، ذخیره میشوند و مورد تجزیه و تحلیل قرار میگیرند تا اطلاعات منطقی و ارزشمندی بدست آید. تجزیه و تحلیل دادهها فرایند پیشرفت کار را ممکن و البته تسهیل میکند.
تجزیه و تحلیل دادهها شامل آنالیز مجموعه دادهها برای شناسایی الگوها، روندها و روابط با استفاده از تکنیکهای آماری، مانند تجزیه و تحلیل آماری استنباطی و توصیفی است. شما میتوانید از نرمافزارهای رایانهای مانند صفحات گسترده برای خودکار کردن این فرآیند و کاهش احتمال خطای انسانی در روند تجزیه و تحلیل آماری استفاده کنید. این امر میتواند به شما امکان تجزیه و تحلیل موثر دادهها را بدهد.
5- تفسیر نتایج
آخرین مرحله تفسیر دادهها است، که نتایج قطعی در مورد هدف تجزیه و تحلیل ارائه میدهد. پس از تجزیه و تحلیل، میتوانید نتیجه را به صورت نمودار، گزارش، کارت امتیاز و داشبورد ارائه دهید تا در اختیار افراد غیر حرفهای قرار گیرد. به عنوان مثال، تفسیر تجزیه و تحلیل تأثیر کارخانهای دارای ۶۰۰۰ کارگر بر میزان جرم و جنایت در یک شهر کوچک با ۱۳۰۰۰ نفر جمعیت، میتواند میزان نزولی فعالیتهای جنایی را نشان دهد. برای نمایش این کاهش میتوانید از نمودار خطی استفاده کنید.
به صورت کلی دو نوع تجزیه و تحلیل داده اصلی وجود دارد: توصیفی و استنباطی(تحلیلی). هر یک از این انواع اهداف و نقشهای خاص خود را در روند تجزیه و تحلیل دادهها دارند. در ادامه هر کدام از آنها را به صورت جداگانه بررسی خواهیم کرد:
آمار توصیفی
در این نوع تجزیه و تحلیل، اگر تجزیه و تحلیل به صورت کمّی باشد، پژوهشگر دادههای جمعآوری شده را با استفاده از شاخصهای آماری توصیفی، خلاصه و طبقهبندی میکند. بهعبارت دیگر، در تجزیه و تحلیل توصیفی پژوهشگر ابتدا دادههای جمعآوری شده را با تهیه و تنظیم جدول توزیع فراوانی خلاصه میکند و سپس به کمک نمودار آنها را نمایش میدهد و سرانجام، با استفاده از سایر شاخصهای آمار توصیفی آنها را خلاصه میکند. مهم ترین شاخصهای آمار توصیفی که کاربرد زیادی دارند عبارتاند از: میانگین، میانه و انحراف استاندارد.ولی اگر تجزیه و تحلیل کیفی باشد، در تحلیل توصیفی چگونگی صفات هر یک از متغیرهای موجود، در تحلیل تشریح میشود.
آمار تحلیلی
آمار تحلیلی یا استنباطی برای مطالعه رابطه میان متغیرها در دادهها استفاده میشود. از این آمارها برای پیشبینی، نتیجهگیری یا تعمیم نتایج به کل جامعه آماری استفاده میشود. در تحلیل استنباطی نمونه کوچکی از دادهها گرفته میشود و نتایج آن برای جامعه هدفی بزرگتر استفاده میشود.
ابزارهای لازم برای انجام تحلیل آماری
یکی از ابزارهای اصلی مورد نیاز برای انجام و نگارش تحلیل آماری، نرم افزار آماری است. و تصور “تحلیل آماری” بدون استفاده از نرم افزارهای آماری غیر ممکن است. زیرا برای تجزیه و تحلیل داده ها نیاز به عملیات های آماری خاصی است که محاسبات آن به صورت دستی غیر ممکن یا بسیار سخت و زمان بر می باشد.
تجزیه و تحلیل آماری توصیفی شامل جمع آوری، تفسیر، تجزیه و تحلیل و خلاصه کردن داده ها برای ارائه آنها در قالب نمودارها، نمودارها و جداول است. به جای نتیجه گیری، به سادگی خواندن و درک داده های پیچیده را آسان می کند.
آمار توصیفی ساده ترین شکل تحلیل آماری است که از اعداد برای توصیف کیفیات یک مجموعه داده استفاده می کند. این به کاهش مجموعه داده های بزرگ به اشکال ساده و فشرده تر برای تفسیر آسان کمک می کند. میتوانید از آمار توصیفی برای خلاصه کردن دادههای یک نمونه استفاده کنید یا یک نمونه کامل را در یک جامعه پژوهشی نشان دهید. آمار توصیفی از ابزارهای تجسم دادهها مانند جداول و نمودارها برای آسانتر کردن تحلیل و تفسیر استفاده میکند. اما آمار توصیفی برای نتیجه گیری مناسب نیست. این فقط می تواند داده ها را نشان دهد بنابراین شما می توانید ابزارهای تحلیل آماری پیچیده تری را برای استنتاج استفاده کنید.
آمار توصیفی می تواند از معیارهای گرایش مرکزی استفاده کند که از یک مقدار واحد برای توصیف یک گروه استفاده می کند. میانگین، میانه و مد برای به دست آوردن مقدار مرکزی برای یک مجموعه داده معین استفاده می شود. به عنوان مثال، می توانید از تجزیه و تحلیل آماری توصیفی برای یافتن میانگین سنی رانندگان دارای بلیت در شهرداری استفاده کنید. آمار توصیفی نیز می تواند اندازه گیری پراکندگی را پیدا کند. به عنوان مثال، شما می توانید محدوده سنی رانندگان با DUI و تصادفات رانندگی در یک ایالت را پیدا کنید. تکنیک های مورد استفاده برای یافتن اندازه گیری پراکندگی شامل محدوده، تنوع و انحراف استاندارد است.
تحلیل آماری استنباطی بر نتیجه گیری معنادار بر اساس داده های تحلیل شده تمرکز دارد. رابطه بین متغیرهای مختلف را مطالعه می کند یا برای کل جمعیت پیش بینی می کند.
تجزیه و تحلیل آماری استنباطی برای استنباط یا نتیجهگیری در مورد یک جمعیت بزرگتر بر اساس یافتههای یک گروه نمونه در آن استفاده میشود. این می تواند به محققان کمک کند تا تمایز بین گروه های حاضر در یک نمونه را پیدا کنند. از آمار استنباطی نیز برای تأیید تعمیمهای انجام شده در مورد یک جامعه از یک نمونه استفاده میشود، زیرا توانایی آن در محاسبه خطاها در نتیجهگیری در مورد بخشی از یک گروه بزرگتر است.
برای انجام تحلیل آماری استنباطی ، محققان پارامترهای جامعه را از نمونه تخمین می زنند. آنها همچنین می توانند یک آزمون فرضیه های آماری را انجام دهند تا به فاصله اطمینانی برسند که تعمیم های انجام شده از نمونه را تأیید یا رد کند.
3-2- تجزیه و تحلیل پیشگویانه (Predictive analysis)
تحلیل آماری پیشبینیکننده نوعی تحلیل آماری است که دادهها را برای استخراج روندهای گذشته و پیشبینی رویدادهای آینده بر اساس آنها تجزیه و تحلیل میکند. برای انجام تجزیه و تحلیل آماری داده ها از الگوریتم های یادگیری ماشین، داده کاوی، مدل سازی داده و هوش مصنوعی استفاده می کند.
تجزیه و تحلیل پیشگو شاخه ای از هوش تجاری است زیرا بسیاری از سازمان ها با فعالیت در بازاریابی، فروش، بیمه و خدمات مالی برای انجام برنامه های بلندمدت به داده ها متکی هستند. توجه به این نکته مهم است که تحلیل پیشبینیکننده فقط میتواند پیشبینیهای فرضی انجام دهد و کیفیت پیشبینیها به دقت مجموعه دادههای زیربنایی بستگی دارد.
4-2- تحلیل پرسپکتیو (Prescriptive analysis)
تجزیه و تحلیل تجویزی تجزیه و تحلیل داده ها را انجام می دهد و بر اساس نتایج بهترین اقدام را تجویز می کند. این یک نوع تجزیه و تحلیل آماری است که به شما در تصمیم گیری آگاهانه کمک می کند.
تحلیل آماری تجویزی به سازمان ها کمک می کند تا از داده ها برای هدایت فرآیند تصمیم گیری خود استفاده کنند. شرکت ها می توانند از ابزارهایی مانند تجزیه و تحلیل گراف، الگوریتم ها، یادگیری ماشینی و شبیه سازی برای این نوع تحلیل استفاده کنند. تجزیه و تحلیل تجویزی به کسب و کارها کمک می کند تا بهترین انتخاب را از چندین دوره اقدام جایگزین داشته باشند.
5-2- تجزیه و تحلیل داده های اکتشافی (Exploratory data analysis)
تجزیه و تحلیل اکتشافی شبیه به تحلیل استنباطی است، اما تفاوت آن در این است که شامل بررسی ارتباط داده های ناشناخته است. روابط بالقوه درون داده ها را تحلیل می کند.
تجزیه و تحلیل داده های اکتشافی تکنیکی است که دانشمندان داده برای شناسایی الگوها و روندها در یک مجموعه داده استفاده می کنند. آنها همچنین می توانند از آن برای تعیین روابط بین نمونه ها در یک جامعه، اعتبار سنجی مفروضات، آزمون فرضیه ها و یافتن نقاط داده از دست رفته استفاده کنند. شرکت ها می توانند از تجزیه و تحلیل داده های اکتشافی برای ایجاد بینش بر اساس داده ها و اعتبارسنجی داده ها برای خطاها استفاده کنند.
6-2- تحلیل علّی (Causal analysis)
تحلیل آماری علی بر تعیین رابطه علت و معلولی بین متغیرهای مختلف در دادههای خام متمرکز است. به عبارت ساده، علت وقوع یک اتفاق و تأثیر آن بر سایر متغیرها را مشخص می کند. این روش می تواند توسط مشاغل برای تعیین دلیل شکست استفاده شود.
تحلیل علّی از داده ها برای تعیین علت یا علت اتفاق افتادن چیزها به روشی که انجام می دهند استفاده می کند. این بخشی جدایی ناپذیر از تضمین کیفیت، بررسی حادثه و سایر فعالیتهایی است که هدف آنها یافتن عوامل زمینهای است که منجر به یک رویداد شده است. شرکت ها می توانند از تحلیل علی برای درک دلایل یک رویداد استفاده کنند و از این درک برای هدایت تصمیمات آینده استفاده کنند.
آمار انجمنی ابزاری است که محققان برای پیشبینی و یافتن علت استفاده میکنند. آنها از آن برای یافتن روابط بین چندین متغیر استفاده می کنند. همچنین برای تعیین اینکه آیا محققین می توانند استنباط و پیش بینی در مورد یک مجموعه داده از ویژگی های مجموعه دیگری از داده ها داشته باشند یا خیر استفاده می شود. آمار انجمنی پیشرفته ترین نوع تجزیه و تحلیل آماری است و به ابزارهای نرم افزاری پیچیده برای انجام محاسبات ریاضی سطح بالا نیاز دارد. برای اندازه گیری ارتباط، محققان از طیف وسیعی از ضرایب تغییرات، از جمله تحلیل همبستگی و رگرسیون استفاده می کنند.
فرض صفر (Null Hypothesis) در آمار و تحلیل آماری، یک فرضیهی متداول است که معمولاً برای آزمایش فرضیات و تحلیلهای آماری استفاده میشود.
این فرضیه معمولاً اینگونه بیان میشود که هیچ تفاوت یا تأثیر معنیداری بین متغیرها یا گروههای مورد مطالعه وجود ندارد.
به طور رسمی، فرض صفر با علامت �0H0 نمایش داده میشود. مثالی از فرض صفر میتواند به صورت زیر باشد:
�0:میانگین افراد گروه A = میانگین افراد گروه BH0:میانگین افراد گروه A = میانگین افراد گروه B
در این مثال، فرض صفر مدعی است که میانگین دو گروه (گروه A و گروه B) با یکدیگر برابر است و هیچ تفاوت معنیداری بین آنها وجود ندارد.
هدف اصلی از آزمون فرض، اثبات یا رد فرض صفر است. اگر پس از تحلیل دادهها، متوجه شویم که فرض صفر رد میشود، این به معنی این است که دلیلهای کافی برای تصدیق این که تفاوت یا تأثیر معنیداری وجود دارد، فراهم شده است.
در مقابل، اگر نتایج نشان دهند که فرض صفر تایید میشود، این به این معنی است که تا این لحظه دلایل کافی برای رد کردن آن وجود ندارد.
آیا قصد دارید تحقیقی را انجام دهید؟ و یا اینکه در حال مطالعه یک تحقیق می باشید؟
چگونه میتوانید از صحت روش تجزیه و تحلیل داده ها اطمینان حاصل فرمائید؟
شاخه های مختلف علوم برای تجزیه و تحلیل داده ها از روش های مختلفی مانند روش های ذیل استفاده می نمایند:
الف) روش تحلیل محتوا
ب) روش تحلیل آماری
ج) روش تحلیل ریاضی
د) روش اقتصاد سنجی
ه) روش ارزشیابی اقتصادی
و) …
تمرکز این نوشتار بر روش های تجزیه و تحلیل سیستمهای اقتصادی اجتماعی و بویژه روش های تحلیل آماری می باشد.
آمار علم طبقه بندی اطلاعات، علم تصميم گيری های علمی و منطقی، علم برنامه ريزي های دقيق و علم توصيف و بيان آن چيزي است که از مشاهدات می توان فهميد.
هدف ما آموزش درس آمار نیست زیرا اینگونه مطالب تخصصی را میتوان در مراجع مختلف یافت، هدف اصلی ما ارائه یک روش دستیابی سریع به بهترین روش آماری می باشد.
يكي از مشكلات عمومی در تحقبقات ميداني انتخاب روش تحلیل آماري مناسب و یا به عبارتی انتخاب آزمون آماری مناسب براي بررسي سوالات يا فرضيات تحقيق مي باشد.
در آزمون های آماری هدف تعیین این موضوع است که آیا داده های نمونه شواهد کافی برای رد یک حدس یا فرضیه را دارند یا خیر؟
انتخاب نادرست آزمون آماری موجب خدشه دار شدن نتایج تحقیق می شود.
دکتر غلامرضا جندقی استاد یار دانشگاه تهران در مقاله ای كاربرد انواع آزمون هاي آماري را با توجه به نوع داده ها و وبژگي هاي نمونه آماري و نوع تحليل نشان داده است که در این بخش به نکات کلیدی آن اشاره می شود:
قبل از انتخاب یک آزمون آماری بایستی به سوالات زیر پاسخ داد:
1- چه تعداد متغیر مورد بررسی قرار می گیرد؟
2- چند گروه مفایسه می شوند؟
3- آیا توزیع ویژگی مورد بررسی در جامعه نرمال است؟
4- آیا گروه های مورد بررسی مستقل هستند؟
5- سوال یا فرضیه تحقیق چیست؟
6- آیا داده ها پیوسته، رتبه ای و یا مقوله ای Categorical هستند؟
قبل از ادامه این مبحث لازم است مفهوم چند واژه آماری را یاد آور شوم که زیاد وقت گیر نیست.
1- جامعه آماری: به مجموعه كاملي از افراد يا اشياء يا اجزاء كه حداقل در يك صفت مورد علاقه مشترك باشند ،گفته می شود.
2- نمونه آماری: نمونه بخشي از يك جامعة آماری تحت بررسي است كه با روشي كه از پيش تعيين شده است انتخاب ميشود، به قسمي كه ميتوان از اين بخش، استنباطهايي دربارة كل جامعه بدست آورد.
3- پارامتر و آماره: پارامتر يك ويژگي جامعه است در حالي كه آماره يك ويژگي نمونه است. براي مثال ميانگين جامعه يك پارامتر است. حال اگر از جامعه نمونهگيري كنيم و ميانگين نمونه را بدست آوريم، اين ميانگين يك آماره است.
4- برآورد و آزمون فرض: برآوردیابی و آزمون فرض دو روشی هستند که برای استنباط درمورد پارامترهای مجهول دو جمعیت به کار می روند.
5- متغير: ويژگي يا خاصيت يک فرد، شئ و يا موقعيت است که شامل يک سری از مقادير با دسته بنديهای متناسب است. قد، وزن، گروه خونی و جنس نمونه هايي از متغير هستند. انواع متغير می تواند کمی و کیفی باشد.
6- داده های کمی مانند قد، وزن يا سن درجه بندی مي شوند و به همين دليل قابل اندازه گيری می باشند. داده های کمی نیز خود به دو دسته دیگر تقسیم می شوند:
الف: داده های فاصله ای (Interval data)
ب: داده های نسبتی (Ratio data)
7- داده های فاصله ای: به عنوان مثال داده هایی که متغیر IQ (ضریب هوشی) را در پنج نفر توصیف می کنند عبارتند از: 80، 110، 75، 97 و 117، چون این داده ها عدد هستند پس داده های ما کمی اند اما می دانیم که IQ نمی تواند صفر باشد و صفر در اینجا فقط مبنایی است تا سایر مقادیر IQ در فاصله ای منظم از صفر و یکدیگر قرار گیرند پس این داده ها فاصله ای اند.
8- داده های نسبتی: داده های نسبتی داده هایی هستند که با عدد نوشته می شوند اما صفر آنها واقعی است. اکثریت داده های کمی این گونه اند و حقیقتاً دارای صفر هستند. به عنوان مثال داده هایی که متغیر طول پاره خط بر حسب سانتی متر را توصیف می کنند عبارتند از: 20، 15، 35، 8 و 23، چون این داده ها عدد هستند پس داده های ما کمی اند و چون صفر در اینجا واقعاً وجود دارد این داده نسبتی تلقی می شوند.
9- داده های کيفی مانند جنس، گروه خونی يا مليت فقط دارای نوع هستند و قابل بيان با استفاده از واحد خاصی نيستند. داده های کیفی خود به دو دسته دیگر تقسیم می شوند:
الف: داده های اسمی (Nominal data)
ب: داده های رتبه ای (Ordinal data)
10- داده های رتبه ای Ordinal: مانند کیفیت درسی یک دانش آموز (ضعیف، متوسط و قوی) و یا رتبه بندی هتل ها ( یک ستاره، دو ستاره و …)
11- داده های اسمی (nominal ) که مربوط به متغير يا خواص کيفی مانند جنس يا گروه خونی است و بيانگر عضويت در يک گروها category خاص می باشد. (داده مقوله ای)
12- متغیر تصادفی گسسته و پیوسته: به عنوان مثال تعداد تصادفات جادهاي در روز يك متغير تصادفي گسسته است ولی انتخاب يك نقطه به تصادف روي دايرهاي به مركز مبدأ مختصات و شعاع 3 يك متغير تصادفي پيوسته است.
13- گروه: یک متغیر می تواند به لحاظ بررسی یک ویژگی خاص در یک گروه و یا دو و یا بیشتر مورد بررسی قرار گیرد. نکته 1: دو گروه می تواند وابسته و یا مستقل باشد. دو گروه وابسته است اگر ویژگی یک مجموعه افراد قبل و بعد از وقوع یک عامل سنجیده شود. مثلا میزان رضایت شغلی کارکنان قبل و بعد از پرداخت پاداش و همچنین اگر در مطالعات تجربی افراد از نظر برخی ویژگی ها در یک گروه با گروه دیگر همسان شود.
14- جامعه نرمال: جامعه ای است که از توزیع نرمال تبعیت می کند.
15- توزیع نرمال: یکی از مهمترین توزیع ها در نظریه احتمال است. و کاربردهای بسیاری در علوم دارد.
فرمول این توزیع بر حسب دو پارامتر امید ریاضی و واریانس بیان می شود. منحنی رفتار این تابع تا حد زیادی شبیه به زنگ های کلیسا می باشد. این منحنی دارای خواص بسیار جالبی است برای مثال نسبت به محور عمودی متقارن می باشد، نیمی از مساحت زیر منحنی بالای مقدار متوسط و نیمه دیگر در پایین مقدار متوسط قرار دارد و اینکه هرچه از طرفین به مرکز مختصات نزدیک می شویم احتمال وقوع بیشتر می شود.
سطح زیر منحنی نرمال برای مقادیر متفاوت مقدار میانگین و واریانس فراگیری این رفتار آنقدر زیاد است که دانشمندان اغلب برای مدل کردن متغیرهای تصادفی که با رفتار آنها آشنایی ندارند، از این تابع استفاده می کنند. به عنوان مثال در یک امتحان درسی نمرات دانش آموزان اغلب اطراف میانگین بیشتر می باشد و هر چه به سمت نمرات بالا یا پایین پیش برویم تعداد افرادی که این نمرات را گرفته اند کمتر می شود. این رفتار را بسهولت می توان با یک توزیع نرمال مدل کرد.
اگر یک توزیع نرمال باشد مطابق قضیه چی بی شف 26.68 % مشاهدات در فاصله میانگین، مثبت و منفی یک انحراف معیار قرار دارد. و 44.95 % مشاهدات در فاصله میانگین، مثبت و منفی دو انحراف معیار قرار دارد. و 73.99 % مشاهدات در فاصله میانگین، مثبت و منفی سه انحراف معیار قرار دارد.
نکته 1: واضح است که داده های رتبه ای دارای توزیع نرمال نمی باشند.
نکته 2: وقتی داده ها کمی هستند و تعداد نمونه نیز کم است تشخیص نرمال بودن داده ها توسط آزمون کولموگروف – اسمیرنف مشکل خواهد شد.
16- آزمون پارامتریک: آزمون هاي پارامتريک، آزمون هاي هستند که توان آماري بالا و قدرت پرداختن به داده هاي جمع آوري شده در طرح هاي پيچيده را دارند. در این آزمون ها داده ها توزيع نرمال دارند. (مانند آزمون تی).
17- آزمون هاي غيرپارامتري: آزمون هائی مي باشند که داده ها توزیع غیر نرمال داشته و در مقايسه با آزمون های پارامتري از توان تشخیصی کمتري برخوردارند. (مانند آزمون من – ویتنی و آزمون کروسکال و والیس)
نکته3: اگر جامعه نرمال باشد از آزمون های پارامتریک و چنانچه غیر نرمال باشد از آزمون های غیر پارامتری استفاده می نمائیم.
نکته 4: اگر نمونه بزرگ باشد، طبق قضیه حد مرکزی جتی اگر جامعه نرمال نباشد می توان از آزمون های پارامتریک استفاده نمود.
حال به کمک جدول زیر براحتی می توانید یکی از 24 آزمون مورد نظر خود را انتخاب کنید:
هدف
داده کمی و دارای توزیع نرمال
داده رتبه ای و یا داده کمیغیر نرمال
داده های کیفی اسمی Categorical
توصیف یک گروه
آزمون میانگین و انحراف معیار
آزمون میانه
آزمون نسبت
مقایسه یک گروه با یک مقدار فرضی
آزمون یک نمونه ای
آزمون ویلکاکسون
آزمون خی – دو یا آزمون دو جمله ای
مقابسه دو گروه مستقل
آزمون برای نمونه های مستقل
آزمون من – ویتنی
آزمون دقیق فیشر ( آزمون خی دو برای نمونه های بزرگ)
مقایسه دو گروه وابسته
آزمون زوجی
آزمون کروسکال
آزمون مک – نار
مقایسه سه گروه یا بیشتر (مستقل)
آزمون آنالیز واریانس یک راهه
آزمون والیس
آزمون خی – دو
مقایسه سه گروه یا بیشتر (وابسته)
آزمون آنالیز واریانس با اندازه های مکرر
آزمون فریدمن
آزمون کوکران
اندازه همبستگی بین دو متغیر
آزمون ضریب همبستگی پیرسون
آزمون ضریب همبستگی اسپرمن
آزمون ضریب توافق
پیش بینی یک متغیر بر اساس یک یا چند متغیر
آزمون رگرسیون ساده یا غیر خطی
آزمون رگرسیون نا پارامتریک
آزمون رگرسیون لجستیک
در رویکردی دیگر بر مبنای تعداد متغیر، تعداد گروه و نرمال بودن جامعه نیز می توان به الگوریتم آزمون آماری مورد نظر دست یافت:
یک متغیر:
انتخاب آزمون آماری برای یک متغیر
یک متغیر در یک گروه
یک متغیر در دو گروه
یک متغیر در سه گروه یا بیشتر
متغیر نرمال
آزمون میانگین و انحراف معیار
آزمون تی
آزمون آنالیز واریانس ANOVA
متغیر غیر نرمال
آزمون نسبت (دو جمله ای)
آزمون خی -دو
آزمون ناپارامتریک
دو متغیر
انتخاب آزمون آماری برای دو متغیر
هر دو متغیر پیوسته هستند
یک متغیر پیوسته و دیگری گسسته است
هر دو متغیر مقوله ای هستند
آزمون همبستگی
آزمون آنالیز واریانس ANOVA
آزمون خی – دو
سه متغیر و بیشتر:
انتخاب آزمون آماری برای سه متغیر و بیشتر
یک گروه
دو گروه و بیشتر
آنالیز کواریانس
تحلیل ممیزی
آنالیز واریانس با اندازه های مکرر
آنالیز واریانس چند متغیره
تحلیل عاملیورگرسیون چند گانه
قابل ذکر است قبل از ورود به الگوریتم انتخاب آزمون آماری بهتر است به سوالات زیر پاسخ دهیم:
1- آیا اختلافی بین میانگین (نسبت) یک ویژگی در دو یا چند گروه وجود دارد؟
2- آیا دو متغیر ارتباط دارند؟
3- چگونه می توان یک متغیر را با استفاده از متغیر های دیگر پیش بینی کرد؟
4- چه چیزی می توان با استفاده از نمونه در مورد جامعه گفت؟
پس از انتخاب آزمون آماری مناسب حال می توان با هر یک از آزمون ها به صورت تخصصی برخورد کرد:
آزمون كي دو (خي دو يا مربع كاي)
اين آزمون از نوع ناپارامتري است و براي ارزيابي همقوارگي متغيرهاي اسمي به كار ميرود. اين آزمون تنها راه حل موجود براي آزمون همقوارگي در مورد متغيرهاي مقياس اسمي با بيش از دو مقوله است، بنابراين كاربرد خيلي زيادتري نسبت به آزمونهاي ديگر دارد. اين آزمون نسبت به حجم نمونه حساس است.
آزمون z – آزمون خطاي استاندارد ميانگين
اين آزمون براي ارزيابي ميزان همقوارگي يا يكسان بودن و يكسان نبودن (Goodness of fit) ميانگين نمونه اي و ميانگين جامعه به كار مي رود. اين آزمون مواقعي به كار مي رود كه مي خواهيم بدانيم آيا ميانگين برآورد شده نمونه اي با ميانگين جامعه جور مي آيد يا نه. اگر این تفاوت کم باشد، اين تفاوت معلول تغيير پذيري نمونه اي شناخته مي شود، ولي اگر زياد باشد نتيجه گرفته مي شود كه برآورد نمونه اي با پارامتر جامعه يكسان (همقواره) نيست. اين آزمون پارامتري است يعني استفاده از آن مشروط به آن است كه دو پارامتر جامعه كه میانگین و انحراف معیار معلوم باشند. همچنين براي آزمون متغيرهاي پيوسته (مقياس فاصله اي) كاربرد دارد. تعداد نمونه بزرگتر و يا مساوي 30 باشد و نيز توزيع متغير در جامعه نرمال باشد.
آزمون استيودنت t
اين آزمون براي ارزيابي ميزان همقوارگي يا يكسان بودن و نبودن ميانگين نمونه اي با ميانگين جامعه در حالتي به كار مي رود كه انحراف معيار جامعه مجهول باشد. چون توزيع t در مورد نمونه هاي كوچك (کمتر از 30) با استفاده از درجات آزادي تعديل ميشود، ميتوان از اين آزمون براي نمونه هاي بسيار كوچك استفاده نمود. همچنين اين آزمون مواقعي كه خطاي استاندارد جامعه نامعلوم و خطاي استاندارد نمونه معلوم باشد، كاربرد دارد.
براي به كاربردن اين آزمون، متغير مورد مطالعه بايد در مقياس فاصله اي باشد، شكل توزيع آن نرمال و تعداد نمونه کمتر از 30 باشد.
آزمون t در حالتهاي زير كاربرد دارد:
– مقايسه يك عدد فرضي با ميانگين جامعه نمونه
– مقايسه ميانگين دو جامعه
– مقايسه يك نسبت فرضي با يك نسبتي كه از نمونه بدست آمده
– مقايسه دو نسبت از دو جامعه
آزمون F
اين آزمون تعميم يافته آزمون t است و براي ارزيابي يكسان بودن يا يكسان نبودن دو جامعه و يا چند جامعه به كار برده ميشود. در اين آزمون واريانس كل جامعه به عوامل اوليه آن تجزيه ميشود. به همين دليل به آن آزمون آناليز واريانس (ANOVA) نيز ميگويند.
وقتي بخواهيم بجاي دو جامعه، همقوارگي چند جامعه را تواما با هم مقايسه نماييم از اين آزمون استفاده ميشود، چون مقايسه ميانگين هاي چند جامعه با آزمون t بسيار مشكل است. مقايسه ميانگين ها و همقوارگي چند جامعه بوسيله اين آزمون (F يا ANOVA) راحت تر از آزمون t امكان پذير است.
آزمون كوكران
آزمون كوكران تعميم يافته آزمون مك نمار است. اين آزمون براي مقايسه بيش از دو گروه كه وابسته باشند و مقياس آنها اسمي يا رتبه اي باشند به كار ميرود و همچون آزمون مك نمار، جوابها بايد دوتايي باشند.
براي آزمون تغييرات يك نمونه در زمان ها و يا موقعيت هاي مختلف (مثل آراء راي دهندگان قبل از انتخابات در زمانهاي مختلف) به كار ميرود. مقياس ميتواند اسمي يا رتبه اي باشد. به جاي چند سوال ميتوان يك سوال را در موقعيت هاي مختلف ارزيابي نمود. همه افراد بايد به همه سوالات پاسخ گفته باشند. چون پاسخ ها دو جوابي است، در بعضي از انواع تحقيقات ممكن است اطلاعات بدست آمده از دست برود و بهتر است از رتبه بندي استفاده كرد كه در اين صورت «آزمون ويلكاكسون» بهتر جوابگو خواهد بود.
در صورت كوچك بودن نمونه ها آزمون كوكران مناسب نيست و بهتر است از «آزمون فريد من» استفاده شود.
آزمون فريدمن
اين آزمون براي مقايسه چند گروه از نظر ميانگين رتبه هاي آنهاست و معلوم ميكند كه آيا اين گروه ها ميتوانند از يك جامعه باشند يا نه؟
مقياس در اين آزمون بايد حداقل رتبه اي باشد. اين آزمون متناظر غير پارامتري آزمون F است و معمولا در مقياس هاي رتبه اي به جاي F به كار ميرود و جانشين آن ميشود (چون در F بايد همگني واريانس ها وجود داشته باشد كه در مقياسهاي رتبه اي كمتر رعايت ميشود).
آزمون فريدمن براي تجريه واريانس دو طرفه (براي داده هاي غير پارامتري) از طريق رتبه بندي به كار ميرود و نيز براي مقايسه ميانگين رتبه بندي گروه هاي مختلف. تعداد افراد در نمونه ها بايد يكسان باشند كه اين از معايب اين آزمون است. نمونه ها بايد همگي جور شده باشند.
آزمون كالماگورف- اسميرانف
اين آزمون از نوع ناپارامتري است و براي ارزيابي همقوارگي متغيرهاي رتبه اي در دو نمونه (مستقل و يا غير مستقل) و يا همقوارگي توزيع يك نمونه با توزيعي كه براي جامعه فرض شده است، به كار ميرود (اسميرانف يك نمونه اي). اين آزمون در مواردي به كار ميرود كه متغيرها رتبه اي باشند و توزيع متغير رتبه اي را در جامعه بتوان مشخص نمود. اين آزمون از طريق مقايسه توزيع فراواني هاي نسبي مشاهده شده در نمونه با توزيع فراواني هاي نسبي جامعه انجام ميگيرد. اين آزمون ناپارامتري است و بدون توزيع است اما بايد توزيع متغير در جامعه براي هر يك از رتبه هاي مقياس رتبه اي در جامعه بطور نسبي در نظر گرفته شود كه آنرا نسبت مورد انتظار مي نامند.
آزمون كالماگورف- اسميرانف دو نمونه اي Two- Sample Kalmogorov- Smiranov Test
اين آزمون در مواقعي به كار ميرود كه دو نمونه داشته باشيم (با شرايط مربوط به اين آزمون كه قبلا گفته شد) و بخواهيم همقوارگي بين آن دو نمونه را با هم مقايسه كنيم.
آزمون كروسكال- واليس
اين آزمون متناظر غير پارامتري آزمون F است و همچون آزمون F ، موقعي به كار برده ميشود كه تعداد گروه ها بيش از 2 باشد. مقياس اندازه گيري در كروسكال واليس حداقل بايد ترتيبي باشد.
اين آزمون براي مقايسه ميانگين هاي بيش از 2 نمونه رتبه اي (و يا فاصله اي) بكار ميرود. فرضيات در اين آزمون بدون جهت است يعني فقط تفاوت را نشان ميدهد و جهت بزرگتر يا كوچكتر بودن گروه ها را از نظر ميانگين هايشان نشان نمي دهد. كارايي اين آزمون 95 درصد آزمون F است.
آزمون مك نمار
اين آزمون از آزمونهاي ناپارامتري است كه براي ارزيابي همانندي دو نمونه وابسته بر حسب متغير دو جوابي استفاده ميشود. متغيرها ميتوانند داراي مقياس هاي اسمي و يا رتبه اي باشند. اين آزمون در طرح هاي ماقبل و مابعد ميتواند مورد استفاده قرار گيرد (يك نمونه در دو موقعيت مختلف). اين آزمون مخصوصا براي سنجش ميزان تاثير عملكرد تدابير به كار ميرود.
ويژگي ها: اگر متغيرها اسمي باشند، اين آزمون بي بديل است اما اگر رتبه اي باشد ميتوان از آزمون t نيز استفاده كرد (در صورت وجود شرايط آزمون t) ، و يا آزمون ويلكاكسون استفاده نمود. از عيوب اين آزمون اين است كه جهت و اندازه تغييرات را محاسبه نميكند و فقط وجود تغييرات را در نمونه ها در نظر ميگيرد.
آزمون ميانه
اين آزمون همتاي ناپارامتري آزمون هاي t – Z – F است و وقتي دو يا چند گروه از ميان دو يا چند جامعه مستقل با توزيع هاي يكسان انتخاب شده اند به كار برده ميشود. در اين آزمون مقياس اندازه گيري ترتيبي است و بين داده ها نبايد همرتبه وجود داشته باشد. اين آزمون، هم براي گروه هاي مستقل و هم وابسته كاربرد دارد و لزومي ندارد كه حتما حجم گروه هاي نمونه با يكديگر برابر باشند.
آزمون تك نمونه اي دورها
اين آزمون مواقعي به كار ميرود كه توالي مقادير متغيرها را بخواهيم آزمون نماييم كه آيا تصادفي بوده و يا نه. در واقع آزمون كي دو و يا آزمون هاي ديگر كه در آنها توالي متغيرها بي اهميت است، در اين آزمون مهم و اصل انگاشته ميشود. به عبارت ديگر، براي اينكه بتوانيم در يك نمونه كه در آن رويدادهاي مختلف از طرف فرد و يا واحد آماري رخ داده است، آزمون نماييم كه آيا اين رويدادها تصادفي است يا نه، به كار برده ميشود. هيچ آزمون ديگري همچون اين آزمون نمي تواند توالي را مورد نظر قرار دهد. بنابراين براي اين منظور منحصر به فرد ميباشد.
آزمون علامت
اين آزمون از انواع آزمونهاي غير پارامتري است و هنگامي به كار برده ميشود كه نمونه هاي جفت، مورد نظر باشد (مثل زن و شوهر و يا خانه هاي فرد و زوج و . . . ). زيرا در اين آزمون يافتهها به صورت جفت جفت بررسي ميشوند و اندازه مقادير در آن بي اثر است و فقط علامت مثبت و منفي و يا در واقع جهت پاسخ ها و يا بيشتر و كمتر بودن پاسخ هاي جفتهاي گروه مورد تحقيق (نمونه آماري) در نظر گرفته ميشود.
هنگامي كه ارزشيابي متغير مورد مطالعه با روشهاي عادي قابل اندازه گيري نباشد و قضاوت در مورد نمونه هاي آماري (كه به صورت جفت ها هستند) فقط با علامت بيشتر (+) و كمتر (-) مورد نظر باشد ، از اين آزمون ميتوان استفاده كرد. شكل توزيع ميتواند نرمال و يا غير نرمال باشد و يا از يك جامعه و يا دو جامعه باشند (مستقل و يا وابسته). توزيع بايد پيوسته باشد. اين آزمون فقط تفاوت هاي زوجها را مورد بررسي قرار ميدهد و در صورت مساوي بودن نظرات هر زوج (مشابه بودن) آنها را از آزمون حذف ميكند. چون مقادير در اين آزمون نقشي ندارند، شدت و ضعف و اندازه بيشتر يا كمتر بودن نظرات پاسخگويان (جفت ها) در اين آزمون بي اثر است و در واقع نقص اين آزمون حساب ميشود.
آزمون تي هتلينگ (T)
آزمون T هتلينگ تعميم يافته t استيودنت است. در آزمون t يك نمونه اي، ميانگين يك صفت از يك نمونه، با يك عدد فرضي كه ميانگين آن صفت از جامعه فرض ميشد، مورد مقايسه قرار ميگرفت، اما در T هتلينگ K متغير (صفت) از آن جامعه (نمونه هاي جامعه) با k عدد فرضي، مورد مقايسه قرار ميگيرند. در واقع اين آزمون از نوع آزمونهاي چند متغيره است كه همقوارگي (Goodness of fit) را بين صفت هاي مختلف از جامعه بدست ميدهد. در T هتلينگ دو نمونه اي نيز همچون T استيودنت دو نمونه اي، مقايسه دو نمونه است اما در اين آزمون K صفت از يك جامعه (نمونه) با K صفت از جامعه ديگر (نمونه ديگر) مورد مقايسه قرار ميگيرد.
آزمون مان وايتني U
هر گاه دو نمونه مستقل از جامعه اي مفروض باشد و متغيرهاي آنها به صورت ترتيبي باشند، از اين آزمون استفاده ميشود. اين آزمون مشابه t استيودنت با دو نمونه مستقل است و آزمون ناپارامتري آن محسوب ميشود.
هرگاه شرايط استفاده از آزمونهاي پارامتري در متغيرها موجود نباشد، يعني متغيرها پيوسته و نرمال نباشند از اين آزمون استفاده ميشود. دو نمونه بايد مستقل بوده و هر دو كوچكتر از 10 مورد باشند. در صورت بزرگتر بودن از 10 مورد بايد از آماره هاي Z استفاده كرد (در محاسبات كامپيوتري، تبديل به Z به طور خودكار انجام ميشود). در اين آزمون شكل توزيع، پيش فرضي ندارد يعني ميتواند نرمال و يا غير نرمال باشد.
آزمون ويلكاكسون
اين آزمون از آزمونهاي ناپارامتري است كه براي ارزيابي همانندي دو نمونه وابسته با مقياس رتبه اي به كار ميرود. همچون آزمون مك نمار، اين آزمون نيز مناسب طرح هاي ماقبل و مابعد است (يك نمونه در دو موقعيت مختلف)، و يا دو نمونه كه از يك جامعه باشند. اين آزمون اندازه تفاوت ميان رتبه ها را در نظر ميگيرد بنابراين متغيرها ميتوانند داراي جوابهاي متفاوت و يا فاصله اي باشند. اين آزمون متناظر با آزمون t دو نمونه اي وابسته است و در صورت وجود نداشتن شرايط آزمون t جانشين خوبي براي آن است. نمونه هاي به كار برده شده در اين آزمون بايد نسبت به ساير صفت هايشان جور شده (جفت شده) باشند.
آزمون لون Levene
آزمون لون همگنی واریانس ها را در نمونه های متفاوت بررسی می نماید. به عبارتی فرض تساوی متغیر وابسته را برای گروه هائی که توسط عامل رسته ای تعیین شده اند، آزمون می کند و نسبت به اکثر آزمونها کمتر به فرض نرمال بودن وابسته بوده و در واقع به انحراف نرمال مقاوم است.
این آزمون به منظور بررسی برابری واریانس جمعیت آماری در نمونههای مختلف انجام میشود. فرض صفر در اینجا این است که واریانسها همگن هستند، یعنی واریانس جمعیتها با یکدیگر برابر هستند. اگر مقدار P-VALUE در اماره لون کمتر از 0.05 باشد، تفاوت بدست آمده در واریانس نمونه بهطور بعید اتفاق افتاده است و بنابراین فرض صفر که برابری واریانسهاست رد میشود و نتیجه میگیریم که بین واریانسها در نمونه تفاوت وجود دارد.
پارامتر و آماره (Parameter & Statistics)، برای تخمین یک مقدار مجهول استفاده می شوند، پارامتر مقدار مجهول جامعه و آماره مقدار مجهول نمونه را مشخص می کند.
هدف تحقیق کمی، درک ویژگی های جمعیتها از طریق یافتن پارامترها است. در عمل، جمعآوری دادهها از هر یک از اعضای یک جمعیت اغلب بسیار دشوار، زمانبر یا غیرممکن است. در عوض، داده ها از نمونه ها جمع آوری می شود.
با آمار استنباطی، میتوانیم از آمار نمونهای برای حدسهای آموزشی در مورد پارامترهای جمعیت استفاده کنیم.
ویژگی پارامتر و آماره
پارامتر و آماره ها اعدادی هستند که هر ویژگی قابل اندازه گیری یک نمونه یا یک جامعه را خلاصه می کنند. برای متغیرهای طبقه بندی شده (به عنوان مثال، وابستگی سیاسی)، رایج ترین آمار یا پارامتر یک نسبت است. برای متغیرهای عددی (به عنوان مثال، ارتفاع)، آمار توصیفی مانند میانگین یا انحراف استاندارد معمولاً آماره یا پارامترهای گزارش شده هستند.
در گزارش های خبری و تحقیقاتی، همیشه مشخص نیست که یک عدد یک پارامتر است یا یک آماره. برای اینکه بفهمید با کدام نوع شماره سروکار دارید، موارد زیر را از خود بپرسید: آیا این عدد یک جمعیت کامل و کامل را توصیف می کند که می توان برای جمع آوری داده به هر عضو دسترسی داشت؟ آیا می توان در یک بازه زمانی معقول اطلاعات مربوط به این ویژگی را از هر یک از اعضای جمعیت جمع آوری کرد؟ اگر پاسخ هر دو سوال مثبت است، احتمالاً عدد یک پارامتر است. برای جمعیت های کوچک براساس نمونه گیری، داده ها را می توان از کل جمعیت جمع آوری کرد و در پارامترها خلاصه کرد. اگر پاسخ به هر یک از سؤالات منفی باشد، احتمالاً این عدد یک آماره است. نمونهگیری برای جمعآوری دادهها از جمعیتهای بزرگ و تعمیم آمار به جامعه گستردهتر به روشی معتبر خارجی استفاده میشود.
به خاطر سپردن پارامتر و آماره آسان است! هر دو مقادیر خلاصه ای هستند که یک گروه را توصیف می کنند، و یک دستگاه یادگاری مفید برای به خاطر سپردن این که هر گروه کدام گروه را توصیف می کند وجود دارد. فقط روی حرف اول آنها تمرکز کنید:
پارامتر = جمعیت آماره = نمونه جمعیت کل گروهی از افراد، اشیاء، حیوانات، معاملات و غیره است که شما در حال مطالعه آنها هستید. نمونه بخشی از جامعه است.
تفاوت جمعیت و نمونه
در تحقیق، یک جمعیت کل گروهی است که شما علاقه مند به مطالعه آن هستید. این ممکن است گروهی از افراد باشد (به عنوان مثال، همه بزرگسالان در ایالات متحده یا همه کارکنان یک شرکت)، اما میتواند به معنای گروهی باشد که شامل انواع دیگری از عناصر است: اشیا، رویدادها، سازمانها، کشورها، گونهها، ارگانیسمها و غیره. نمونه، گروه کوچکتری است که از جامعه گرفته شده است. نمونه گروهی از عناصر است که شما در واقع از آنها داده ها را جمع آوری خواهید کرد
محاسبه پارامتر و آماره
محققان معمولا بیشتر به درک پارامترهای جمعیت علاقه مند هستند. به هر حال، درک خواص یک نمونه نسبتا کوچک به خودی خود ارزشمند نیست. به عنوان مثال، دانشمندان به تأثیر متوسط یک داروی جدید فقط بر تعداد کمی از افراد اهمیت نمی دهند، که یک آمار نمونه است. در عوض، آنها میخواهند تأثیر میانگین آن را در کل جمعیت، یک پارامتر، درک کنند. متأسفانه، اندازه گیری کل جمعیت برای محاسبه دقیق پارامتر آن معمولاً غیرممکن است زیرا آنها بسیار بزرگ هستند. بنابراین، ما در استفاده از نمونه ها و آمار آنها گیر کرده ایم. خوشبختانه با آمار استنباطی، تحلیلگران می توانند از آمار نمونه برای تخمین پارامترهای جمعیت استفاده کنند که به پیشرفت علم کمک می کند. به طور کلی در بررسی پارامتر و آماره، استفاده از آماره نمونه برای تخمین پارامتر جمعیت، فرآیندی است که با استفاده از روش نمونه گیری شروع می شود که تمایل به تولید نمونه های معرف دارد – نمونه ای با ویژگی های مشابه جامعه. دانشمندان اغلب از نمونه گیری تصادفی استفاده می کنند. سپس تحلیلگران میتوانند از تحلیلهای آماری مختلفی که خطای نمونهگیری را محاسبه میکنند برای تخمین پارامتر جمعیت استفاده کنند. این فرآیند به استنتاج آماری معروف است.
با استفاده از آمار استنباطی، می توانید پارامترهای جمعیت را از آماره نمونه تخمین بزنید. برای تخمین های بی طرفانه، نمونه شما در حالت ایده آل باید نماینده جمعیت شما باشد و/یا به طور تصادفی انتخاب شود. دو نوع تخمین مهم وجود دارد که می توانید در مورد پارامتر جمعیت انجام دهید: تخمین نقطه ای و تخمین فاصله. تخمین نقطه ای یک تخمین مقدار واحد از یک پارامتر بر اساس یک آمار است. به عنوان مثال، میانگین نمونه، تخمین نقطه ای از میانگین جمعیت است. تخمین بازه ای محدوده ای از مقادیر را به شما می دهد که انتظار می رود پارامتر در آن قرار داشته باشد. فاصله اطمینان رایج ترین نوع تخمین فاصله است. هر دو نوع تخمین برای جمع آوری یک ایده واضح از جایی که یک پارامتر احتمالاً در آن قرار دارد، مهم هستند.
مثال برآورد پارامتر و آماره
مثال مرتبط در تخمین پارامتر و آماره این است: در مطالعه خود در مورد حمایت از مجازات اعدام در میان ساکنان ایالات متحده، متوجه می شوید که ۶۱٪ از شرکت کنندگان در نمونه شما از مجازات اعدام حمایت می کنند. برای تخمین پارامتر جمعیت، یک تخمین نقطه ای و یک تخمین فاصله ای را از آمار نمونه خود محاسبه می کنید. تخمین امتیاز شما آماره نمونه شماست – شما تخمین می زنید که ۶۱ درصد از تمام ساکنان ایالات متحده از مجازات اعدام حمایت می کنند.
برای یافتن تخمین بازه، یک بازه اطمینان ۹۵% ایجاد میکنید که به شما میگوید انتظار میرود پارامتر جمعیت در بیشتر مواقع در کجا قرار داشته باشد. با نمونه گیری تصادفی، احتمال ۰.۹۵ وجود دارد که پارامتر جمعیتی واقعی برای حمایت از مجازات اعدام در میان ساکنان ایالات متحده بین ۵۷٪ تا ۶۵٪ است.
نقطه برش (Cut-off point)، مشخص کردن حد امتیازی براساس یک آزمون است که افراد جامعه را به طبقات مختلف تقسیم می کند.
روش تعیین نقطه برش در اقتصاد، کارایی سرمایه گذاری و روش های بهینه سازی آموزشی مورد استفاده قرار می گیرد.
نقطه برش باید بر اساس یک متدولوژی مورد قبول عموم بوده و منعکس کننده قضاوت افراد با کفایت و واجد شرایط باشد.
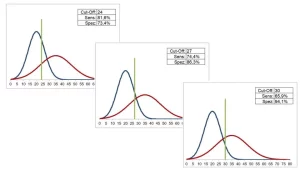
تغییر نقاط برش با مقادیر متفاوتی برای حساسیت و ویژگی همراه است، به معنای مبادله: حساسیتهای بالاتر با ویژگیهای کمتر مرتبط هستند و بالعکس. این مبادله در شکل زیر به وضوح قابل مشاهده است.
محاسبه نقطه برش
نقطه برش سطح معناداری
در آمار، اگر میخواهید در مورد یک فرضیه صفر H0 (رد یا شکست در رد) بر اساس مقدار p نتیجه بگیرید، باید یک نقطه برش از پیش تعیینشده را تعیین کنید که در آن فقط مقادیر p کوچکتر یا مساوی با مقدار قطع میشوند. منجر به رد H0 می شود.در حالی که ۰.۰۵ یک نقطه برش بسیار محبوب برای رد H0 است، نقاط برش و تصمیمگیریهای حاصل میتواند متفاوت باشد – برخی افراد از برشهای سختگیرانهتری مانند ۰.۰۱ استفاده میکنند، که قبل از رد H0 به شواهد بیشتری نیاز دارند، و برخی دیگر ممکن است برشهای سختگیری کمتری مانند ۰.۱۰ داشته باشند. شواهد کمتر اگر H0 رد شود (یعنی p-value کمتر یا مساوی با سطح معنیداری از پیش تعیینشده باشد)، محقق میتواند بگوید که نتیجه آماری معنیداری پیدا کرده است. یک نتیجه از نظر آماری معنادار است اگر خیلی بعید باشد که به طور تصادفی با فرض H0 درست باشد. اگر نتیجه آماری معنیداری دریافت کردید، شواهد کافی برای رد ادعای H0 دارید و نتیجه میگیرید که چیزی متفاوت یا جدید در کار است (یعنی Ha).
پایان نامه نویسی مقاله نویسی
محاسبه نقطه برش پرسشنامه
در تحلیل های کمی آماری، از پرسشنامه استفاده می شود. روایی با شاخص های CVI و CVR محاسبه می شود و پایایی با آلفای کرونباخ. نقطه برش نیز براساس طیف پرسشنامه یک مقدار استاندارد دارد. به عنوان مثال عدد ۳ به عنوان میانگین طیف لیکرت ۵ تایی. اما براساس شرایط و اهداف تحقیق و دقت مدنظر نقطه برش تغییر می کند. کاتآف پوینت در تحلیل دلفی فازی عدد ۰.۷ به صورت توافقی انتخاب شده است.
زمانی که به بررسی یک جامعه پرداخته می شود گام اول بررسی نرمالیتی توزیع متغیرها در جامعه است. در حالت نرمال، براساس آمار توصیفی میانگین، میانه یا مد می توان نقطه برش را تشخیص داد. اما با غیرنرمال بودن جامعه، چندک ها، صدک ها و دیگر شاخص های آماری به عنوان نقطه برش تشخیص داده می شود.
به طور کلی براساس انحراف معیار (فاصله اعداد جامعه از میانگین) می توان به بررسی نقاط برش و تغییر آنها پرداخت. تعداد اعضای جامعه، مقدار صدک مدنظر و انحراف استاندارد می تواند با سطح ۹۵% نقاط برش جامعه را تشخیص دهد. به منظور محاسبه آنلاین نقاط برش بر روی لینک زیر کلیک کنید.
ما در این سایت پرسشنامه های استاندارد (دارای روایی، پایایی، روش دقیق نمره گذاری ، منبع داخل و پایان متن ) ارائه می کنیم و همچنین تحلیل آماری کمی و کیفی رابا قیمت بسیار مناسب و کیفیت عالی و تجربه بیش از 17 سال انجام می دهیم. برای تماس به ما به شماره 09143444846 در شبکه های اجتماعی پیام بفرستید. ایمیلabazizi1392@gmail.com
تمامی حقوق مادی و معنوی این سایت متعلق به لنسرسرا و محفوظ است.
این سایت دارای مجوز می باشد