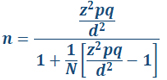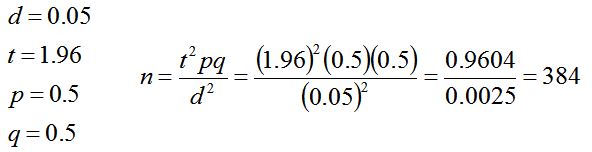...........................................................................................................................................................................................................................................................................................................................................................................
خوش آمدید این سایت دارای مجوز می باشد برای مشاهده مجوز ها پایین صفحه را مشاهده فرمائید.
روشهای نمونهگیری هدفمند و گلوله برفی در تحقیقات کیفی، دو روش نمونهگیری هدفمند و گلوله برفی معمولاً استفاده میشوند. در زیر به توضیح هر یک از این روشها میپردازم:
نمونهگیری هدفمند: در روش نمونهگیری هدفمند، محققان به صورت آگاهانه و با توجه به خصوصیات و معیارهای خاصی که با هدف تحقیق همخوانی دارند، افراد را برای شرکت در تحقیق انتخاب میکنند. این روش معمولاً در تحقیقات کیفی با هدف درک عمیق و جزئیات بیشتر از یک پدیده مورد استفاده قرار میگیرد. محققان ممکن است به صورت هدفمند افراد را بر اساس جنسیت، سن، تجربه، تحصیلات، موقعیت اجتماعی و سایر معیارهای مشخص انتخاب کنند. این روش به محققان امکان میدهد تا به صورت عمیقتری به نتایج و دادههایی که با افراد با خصوصیات خاص به دست میآیند، بپردازند.
تحلیل آماری – پژوهش – کیفی – کمی – کامپیوتر
نمونهگیری گلوله برفی: در روش نمونهگیری گلوله برفی، محققان با شروع از یک نقطه اولیه، به صورت تصادفی و بدون تعیین قبلی، افراد را برای مشارکت در تحقیق انتخاب میکنند. به طور معمول، نمونهگیری گلوله برفی در تحقیقات کیفی با هدف بررسی گستره و تنوع نظرات و تجارب افراد استفاده میشود. این روش به محققان اجازه میدهد تا نمونههای تنوع بخشی از جامعه مورد مطالعه را در بر بگیرند و نظرات و تجارب مختلف را در تحلیل دادهها در نظر بگیرند. با این روش، محققان میتوانند گستره و گوناگونی در نتایج و دادههای تحقیق را به دست آورند.
هر دو روش نمونهگیری هدفمند و گلوله برفی، به محققان اجازه میدهند تا به صورت خصوصیات خاص افراد را برای شرکت در تحقیق انتخاب کنند و به دست آوردن دادههایی که با هدف تحقیق هماهنگ هستند، کمک کنند. البته، در انتخاب هریک از این روشها باید با دقت وتوجه به هدف تحقیق، محدودیتها و مشکلات ممکن در هر روش در نظر گرفته شود. همچنین، نحوه اجرا و انتخاب نمونهها در هر روش نیز ممکن است متفاوت باشد و به سلیقه و تجربه محقق بستگی داشته باشد.
در تحلیل رگرسیون، ضریب بتا برای تفسیر ارتباط بین متغیرهای پیشبین و پاسخ استفاده میشود. تفسیر ضریب بتا به میزانی که یک واحد تغییر در متغیر پیشبین (متغیر مستقل) باعث تغییر در متغیر پاسخ (متغیر وابسته) میشود، صورت میگیرد.
در صورتی که ضریب بتا مثبت باشد، هر یک واحد افزایش در متغیر پیشبین باعث افزایش متغیر پاسخ در مقدار ضریب بتا میشود. به عنوان مثال، اگر ضریب بتا برابر با 0.5 باشد، این نشانگر است که هر واحد افزایش در متغیر پیشبین باعث افزایش نصف واحد در متغیر پاسخ میشود.
اگر ضریب بتا منفی باشد، هر یک واحد افزایش در متغیر پیشبین باعث کاهش متغیر پاسخ در مقدار ضریب بتا میشود. به عنوان مثال، اگر ضریب بتا برابر با -0.3 باشد، این نشانگر است که هر واحد افزایش در متغیر پیشبین باعث کاهش 0.3 واحد در متغیر پاسخ میشود.
ضریب بتا همچنین نشان میدهد که به چه اندازه تغییر متغیر پاسخ در واحدهای استاندارد تغییر میکند. مقدار مطلق ضریب بتا بزرگتر از 1 نشان میدهد که تغییر در متغیر پیشبین بر متغیر پاسخ با تغییر بیشتری همراه است. مقدار مطلق ضریب بتا کوچکتر از 1 نشان میدهد که تغییر در متغیر پیشبین با تغییر کمتری در متغیر پاسخ همراه است.
چگونه فایل اکسل را غیر قابل ویرایش کنیم
اهمیت ضریب بتا باید همراه با مقدار p-value مربوط به ضریب بتا در نظر گرفته شود. p-value اطلاعاتی درباره اهمیت آماری ضریب بتا ارائه میدهد. اگر p-value کمتر از سطح معناداری مشخص شده (معمولاً 0.05) باشد، ضریب بتا قابل قبول است و میتوان آن را به عنوان یک ارتباط معنادار بین متغیرهای پیشبین و پاسخ در نظر گرفت.
به طور کلی، تفسیر ضریب بتا نیازمند توجه به علت قرارگیری متغیرها در مدل رگرسیون، وجود متغیرهای دیگر و تفسیر کلیه ممتغیرهای مستقل و وابسته است. همچنین، در تفسیر ضریب بتا باید از توجه به مفهوم متغیرها و زمینه مورد مطالعه استفاده شود.
تحلیل داده های آماری با مناسبترین قیمت و کیفیت برتر!
با تجربهی بیش از 17 سال و ارائهی بهترین خدمات
مشاوره : پایان نامه و مقاله نویسی تحلیل داده های آماری
توجه: همه ی پرسشنامه هااز منابع معتبر تهیه شده، استاندارد ، دارای روایی و پایایی و منابع داخل و پایان متن می باشند . همه ی پرسشنامه ها قابل ویرایش در قالب نرم افزار ورد Word می باشد.
درود بر شما کاربر محترم و بزرگوار، به عرض می رساند امروزه هزینه های نگهداری و ارتقای سایت بالا می باشد، لذا جهت ادامه فعالیت مجبور شدیم در بعضی از جاها تبلیغ بگذاریم.
لطفاً با کلیک بر روی لینک های زیر از ما حمایت کنید تا بتوانیم خدمات بهتری ارائه دهیم. مطمئن باشد هیچ مشکلی برای شما پیش نخواهد آمد.
با تشکر.
،
در تحلیل رگرسیون، ضریب بتا یکی از پارامترهای مهم است که برای ارزیابی اثر یک متغیر مستقل (متغیر پیشبین) بر متغیر وابسته (متغیر پاسخ) استفاده میشود. ضریب بتا نشان دهنده تغییر متوسط متغیر پاسخ بر اثر یک واحد تغییر در متغیر پیشبین است، همچنین نشان دهنده جهت و قدرت ارتباط بین دو متغیر است.
بطور رسمی، ضریب بتا توسط مدل رگرسیون تخمین زده میشود. در یک مدل رگرسیون خطی ساده، ضریب بتا نشان دهنده تغییر متوسط متغیر پاسخ بر اثر یک واحد تغییر در متغیر پیشبین است. اگر ضریب بتا مثبت باشد، این نشانگر است که افزایش در متغیر پیشبین همراه با افزایش در متغیر پاسخ است. و اگر ضریب بتا منفی باشد، این نشانگر است که افزایش در متغیر پیشبین همراه با کاهش در متغیر پاسخ است.
چگونه فایل اکسل را غیر قابل ویرایش کنیم
مقدار ضریب بتا نیز نشان میدهد که به چه اندازه تغییر متغیر پاسخ در واحدهای استاندارد تغییر میکند. اگر ضریب بتا بزرگتر از 1 باشد، این نشانگر است که تغییر در متغیر پیشبین بر متغیر پاسخ با تغییر بیشتری همراه است. در صورتی که مقدار ضریب بتا کوچکتر از 1 باشد، تغییر در متغیر پیشبین با تغییر کمتری در متغیر پاسخ همراه است.
بنابراین، ضریب بتا به ما اطلاعاتی در مورد ارتباط بین متغیرهای پیشبین و پاسخ را میدهد و میتواند در تفسیر نتایج و پیشبینی مقادیر پاسخ براساس مقادیر پیشبین مفید باشد.
خلاصه: ضریب مسیر بیان کننده وجود رابطه علی خطی و شدت و جهت این رابطه بین دو متغیر مکنون است.
در حقیقت همان ضریب رگرسیون در حالت استاندارد است که ما در مدل های ساده تر رگرسیون ساده و چندگانه مشاهده می کردیم.
عددی بین 1- تا +1 است که اگر برابر با صفر شوند ، نشان دهنده ی نبود رابطه ی علی خطی بین دو متغیر پنهان است.
توجه: همه ی پرسشنامه هااز منابع معتبر تهیه شده، استاندارد ، دارای روایی و پایایی و منابع داخل و پایان متن می باشند . همه ی پرسشنامه ها قابل ویرایش در قالب نرم افزار ورد Word می باشد.
درود بر شما کاربر محترم و بزرگوار، به عرض می رساند امروزه هزینه های نگهداری و ارتقای سایت بالا می باشد، لذا جهت ادامه فعالیت مجبور شدیم در بعضی از جاها تبلیغ بگذاریم.
لطفاً با کلیک بر روی لینک های زیر از ما حمایت کنید تا بتوانیم خدمات بهتری ارائه دهیم. مطمئن باشد هیچ مشکلی برای شما پیش نخواهد آمد.
با تشکر.
،
نمونهگیری گلوله برفی (Snowball sampling) (نمونهگیری زنجیری)، یک روش نمونهگیری غیر احتمالی در تحقیقات است.
تحلیل آماری
statistical analysis
نمونهگیری احتمالی و غیر احتمالی
روشهای نمونهگیری غیر احتمالی، برای نتیجه گرفتن رفتار یک جامعه بر اساس نمونهٔ آن استفاده نمیشوند، بلکه از آنها زمانی استفاده میشود که تمرکز تحقیق بر روی درک پیچیدگی یک قضیه یا اتفاق است. در آنها همهٔ اعضا شانس انتخاب شدن ندارند و شانس هر عضو هم مشخص نیست. پس میزان تعمیم پذیری به کل جامعه و میزان خطا نیزمشخص نیست. نمونهگیریهای احتمالی بر اساس قانون احتمالات انجام میشوند و هر یک از اعضا شانس انتخاب شدن دارند. در آنها نظر محقق یا افراد نمونه تأثیری بر نتیجه ندارد و میتوان از روی نمونه، نتیجه را برای کل جامعه استنباط کرد.
نمونهگیری آسان
نمونهگیری آسان (در دسترس یا Convenience نوعی از روشهای نمونهگیری غیر احتمالی است.
یعنی استفاده از اعضایی که به آسانی در دسترس محقق قرار دارند. نظرسنجی یک استاد از دانشجویان خود، یا پرس و جو از رهگذران یک خیابان نمونههایی از آن اند. نمونهگیری گلوله برفی نوعی نمونهگیری آسان است.
نمونهگیری گلوله برفی
نمونهگیری گلوله برفی یا همچنین به آن “نمونهگیری تصادفی یکنواخت” نیز گفته میشود، یک روش نمونهگیری تصادفی است که در آن از یک مجموعه از عناصر در نظر گرفته شده و برای انتخاب نمونهها از یک فرایند تصادفی استفاده میشود. این روش به خوبی مناسب برای انتخاب نمونهها در مطالعات آماری است و برای اطمینان از نمایندگی صحیح و عمومیت نتایج بسیار مهم است.
در این روش اعضای آیندهٔ نمونه از طریق اعضای سابق نمونه انتخاب میشوند و نمونه مانند یک گلولهٔ برفی بزرگ و بزرگتر میشود. برای مثال در یک پژوهش کیفی با روش مصاحبه، از افراد پرسیده میشود که آیا فرد دیگری را برای مصاحبه پیشنهاد میکنند و این گونه نمونهٔ آنها بزرگ و بزرگتر خواهد شد. اگر در این نمونهگیری از شبکههای اجتماعی فضای مجازی استفاده شود، به آن نمونهگیری گلوله برفی مجازی میگویند.
کاربرد اصلی نمونهگیری گلوله برفی برای تحقیق در مورد جوامع پنهان است. مثلاً جامعهٔ مصرفکنندگان مواد مخدر در یک کشور، جمعیت افراد بی خانمان یک کشور یا جامعهٔ افراد مبتلا به یک بیماری نادر.
این نمونهگیری با داشتن تعداد اولیه ای از افراد شروع میشود. سپس از آنها خواسته میشود تا کسانی را که فکر میکنند برای این تحقیق مناسب هستند، به برنامهٔ تحقیقاتی معرفی کنند. ممکن است گروههایی با مشکل مورد تحقیق پیدا شوند که میتوان آنها را هم در نمونهگیری به کار برد. در آخر باید با مطالعه شخصیت و زندگی افراد مطمئن بشویم که بازهٔ خوبی از انواع افراد در نمونه ما حضور داشته باشند.
انجام پژوهش کیفی.jpg
انواع نمونه گیری گلوله برفی
نمونهگیری خطی: در این روش هر یک از اعضای نمونه، یک فرد جدید را برای ادامهٔ روند نمونهگیری معرفی میکنند.
نمونهگیری نمایی بدون تبعیض: در این روش هر عضو نمونه، گروهی از افراد را پیشنهاد میکند.
نمونهگیری نمایی با تمییز: در این روش هر عضو نمونه، گروهی از افراد را پیشنهاد میکند اما در نهایت یکی از این افراد در نمونه حضور پیدا خواهند کرد.
در هر سه روش، روند نمونهگیری ادامه میابد تا به تعداد کافی از افراد دست پیدا کنیم.
شرح روش نمونهگیری گلوله برفی عبارت است از:
تعریف جامعه: ابتدا باید جامعه مورد مطالعه را به دقت تعریف کنید. جامعه میتواند مجموعهای از افراد، اشیا یا واحدهای دیگر باشد که برای مطالعه مورد نظر شما قابل تشخیص هستند.
تعیین اندازه نمونه: بر اساس هدف مطالعه و نیازهای آماری، باید اندازه نمونه را تعیین کنید. اندازه نمونه باید به طور معقول و با توجه به قابلیت دسترسی به اعضای جامعه و همچنین دقت مورد نیاز برآورد تعیین شود.
شمارهگذاری: به هر عنصر در جامعه یک شماره یا برچسب نسبت دهید تا بتوانید به راحتی عناصر را از هم تمییز دهید.
ایجاد یک جدول تصادفی: برای ایجاد نمونه، جدولی تصادفی از اعداد تولید کنید. اگر جامعه شما اندازهای N دارد، جدول تصادفی باید اعداد 1 تا N را در خود شامل شود.
انتخاب نمونه: با استفاده از جدول تصادفی، عناصری که با شمارههای تصادفی در جدول مطابقت دارند را انتخاب کنید. این عناصر انتخاب شده نمونه شما خواهند بود.
تحلیل نمونه: پس از جمعآوری نمونه، میتوانید آن را تحلیل کنید و نتایج را به جامعه کلی تعمیم دهید. این تعمیمها بر اساس قوانین آماری و تجزیه و تحلیل مناسب انجام میشود.
نمونهگیری گلوله برفی در اطلاعات آماری به عنوان یک روش نمونهگیری تصادفی معموماً در استفاده از نمونهگیری گلوله برفی، هیچ عنصری از جامعه نادیده گرفته نمیشود و همه عناصر در فرآیند نمونهگیری شرکت میکنند. این باعث میشود تا همه اعضای جامعه فرصت یکسانی برای انتخاب شدن در نمونه داشته باشند و نمونه نهایی به طور کامل
پایان نامه – مقاله نویسی
مزایا
امکان دسترسی به جوامع پنهان به علت روابط و آشناییهای احتمالی این افراد. نتیجه یافتن این روش به میزان جلب اعتماد افراد مورد نمونهگیری از سوی جامعه شناسان و دانشمندان دارد.
وقتی میخواهیم به افرادی از یک جامعهٔ پنهان دست یابیم، از این طریق به افراد، زمان و هزینهٔ کمتری نیاز است تا نمونهگیری انجام شود.
این نمونهگیری برای تشخیص افراد متخصص یک جامعه در یک موضوع علمی نیز به کار میرود. زیرا این افراد معمولاً یکدیگر را میشناسند و میشود از طریق چند نفر از آنها به عنوان نمونه اولیه، به تعداد بیشتری از این افراد دست پیدا کرد.
این نمونهگیری، وقت کمی میگیرد و افراد جدید به سبب آشنایی افراد قبلی با محقق، با او راحت تر ارتباط برقرار خواهند کرد.
معایب
افراد نمونهٔ اولیه تأثیر زیادی بر کل روند نمونهگیری دارند. زیرا این نمونهگیری اساساً به معرفی افراد مناسب جهت ادامهٔ نمونهگیری بستگی دارد.
نمونهگیری تصادفی نیست.
اندازهٔ نمونه مشخص نیست.
جامعه شناسان و محققان خود پروژه، کنترل نسبتاً کمی روی روند نمونهگیری دارند.
وقتی جامعه به میزان خوبی همگون باشد (یعنی افراد دارای دیدگاهها و تجربیات مشابه باشند)، این نمونهگیری مناسب است اما اگر جامعه دارای چندین دسته با عقاید مختلف و در واقع نا همگون باشد، این نمونهگیری با احتمال خطای بالایی همراه است.
بنابراین بهترین کار این است که مطمئن شویم که نمونهٔ اولیه شامل تنوع خوبی از افراد باشد.[
به متغیر تعدیل کننده گاهی متغیر مستقل فرعیگفته می شود.
متغیر تعدیلگر یک متغیر کمی یا کیفی است که جهت و قدرت رابطه متغیر مستقل و وابسته را تحت تاثیر قرار میدهد.
برای نمونه متغیر عزت نفس در بررسی رابطه فرسودگی شغلی و مدیریت زمان یک متغیر تعدیل کننده است.
حال در نظر بگیرید که اثر تعدیل گری عزت نفس منفی و معنی دار باشد باید به صورت زیر آن را تفسیر کنیم.
عزت نفس بر شدت تأثیر متغیرفرسودگی شغلی بر مدیریت زمان اثر منفی و معکوس دارد . لذا در افرادی که عزت نفس آن ها بالا هست، فرسودگی شغلی کمتر می تواند بر مدیریت زمان تأثیر بگذارد ولی در افرادی که عزت نفس آن ها پایین هست، فرسودگی شغلی بیشتر می تواند بر مدیریت زمان تأثیر بگذارد.
بنابراین عزت نفس ، رابطه فرسودگی شغلی و مدیریت زمان را تعدیل میکند.
انواع متغیر تعدیلکننده و روش محاسبه آن
بارون و کنی (۱۹۸۶) در مقاله خود چهار حالت گوناگون از وضعیت متغیر مستقل و تعدیلگر را به شرح زیر بررسی کردند:
حالت اول: متغیر مستقل و تعدیلگر هر دو از نوع طبقهای (اسمی-رتبهای) باشند.
حالت دوم: متغیر تعدیلگر از نوع طبقهای و متغیر مستقل پیوسته باشد.
حالت سوم: متغیر تعدیلگر پیوسته و متغیر مستقل از نوع طبقهای باشد.
حالت چهارم: هر دو متغیر تعدیلگر و مستقل پیوسته باشند.
در حالت اول برای مثال بخواهید نقش جنسیت را در تاثیر سمت سازمانی بر رضایت شغلی ارزیابی کنید در این حالت میتوانید از تحلیل واریانس دوراهه استفاده کنید.
حالت دوم بیشترین کاربرد را مطالعات مدیریت دارد. برای مثال بخواهید نقش جنسیت را در رابطه اعتماد و رضایت شغلی بسنجید. جنسیت یک متغیر طبقهای است و اعتماد و رضایت متغیرهای پیوسته میباشند. در این حالت میتوانید از روش محاسبه اثر تعدیلگر با رگرسیون خطی استفاده کنید.
برای محاسبه حالت سوم پیشنهادی ندارم زیرا رویه مرسومی نیست ولی برای حالت چهارم میتوانید از محاسبه متغیر تعدیلگر با روش رگرسیون هایس استفاده کنید.
متغیر تعدیلکننده و رگرسیون سلسلهمراتبی
رگرسیون سلسلهمراتبی یا ترتیبی این امکان را فراهم میآورد که تاثیر چند متغیر مستقل بر یک متغیر وابسته طی چند مرحله مشخص شود. از رگرسیون سلسلهمراتبی برای بررسی نقش متغیرهای تعدیلگر براساس رویه پیشنهادی بارون و کنی استفاده کرد.
اگر پرسشنامهای با طیف لیکرت استفاده میکنید تمامی سازههایی که توسط چندین گویه مورد سنجش قرار میگیرند باید به یک شاخص قابل مشاهده تبدیل میشوند. برای این کار میانگین گویههای سنجش آنها را محاسبه کنید.
برای بررسی روابط علی بین متغیرها به طور هماهنگ تلاش های زیادی در دهه اخیر صورت گرفته است. یکی از روش های امید بخش در این زمینه معادلات ساختاری یا تحلیل چند متغیری با متغیرهای پنهان است. از این روش تحت عنوان مدل علی و تحلیل انکوانام شده است. از طریق این روش می توان قابل پذیرش بودن مدل های نظری را در جامعه های خاص با استفاده از داده های همبستگی، غیر آزمایشی و آزمایشی تحلیل کرد. فرضیه مورد بررسی در یک مدل معادلات ساختاری، یک ساختار علی ویژه بین گروهی ا از متغیرهای غیرقابل مشاهده است. این متغیرها ها از طریق گروهی از متغیرهای آشکار اندازه گیری می شود یک مدل معادلات ساختاری کامل از دو جزء بوجود شده است:
الف) یک مدل ساختاری که ساختار علی خاصی را بین متغیرهای پنهان در نظر می گیرد و
ب) یک مدل اندازه گیری که روابطی را بین متغیرهای پنهان و متغیرهای آشکار تعریف می کند. هنگامی که داده های بدست آمده از نمونه مورد بررسی به صورت طیف همبستگی یا کواریانس در آید و توسط گروهی از معادلات رگرسیون تعریف شود، مدل را می توان با استفاده از نرم افزارهای مرتبط تحلیل کرد و نتایج آن را برای جامعه ای که نمونه از آن استخراج شده بدست آورد.
این تحلیل برآوردهایی از پارامترهای مدل (ضرایب مسیر و جملات خطا) و همچنین چند ویژگی برای خوب بودن نتایج بدست آمده فراهم می آورد. تخمین پارامترها و اطلاعات مربوط به خوب بودن تحلیل را می توان برای تغییرات احتمالی در مدل و آزمون دوباره مدل نظری مورد آزمون قرار داد
پایان نامه – مقاله نویسی
مقدمه
یکی از شیوه های تحلیل داده های آماری، تحلیل مسیر است که بیشتر با استفاده از رگرسیون چند متغیره انجام می گیرد. این روش برای تحلیل مدل های علی به کار گرفته می شود و مستلزم طرح مدلی به صورت نمودار علی است و در واقع رابطه علی را نشان می دهد و به ما کمک می کند بدانیم چه می خواهیم بگوییم. علاوه برآن تحلیل مسیر، شکلی از تحلیل رگرسیون عملی است که در آن برای حل کردن مسئله با تحلیل فرضیه های پیچیده، از نمودار مسیر استفاده می شود. تحلیل مسیر یکی از چندین تحلیل آماری است که تحت عنوان مدل معادلات ساختاری شناخته شده اند. این روش امکان تحلیل روابط علی بین دو یا چند متغیر را بوجود می آورد، که ممکن است به صورت مستقل، وابسته، گسسته یا پیوسته، پنهان یا آشکار و یا هر دو در یک معادله خطی به کار روند. تحلیل مسیر معمولا در تحقیقات اکتشافی و تحلیل های نظریه ثانویه بکار می رود. یک محقق می تواند گروهی از داده ها را برای بررسی روابط غیر قابل پیش بینی بین متغیرها تحلیل کند، خواه بطور مستقیم باشد، خواه غیر مستقیم، و به همین ترتیب از طریق مدل های گوناگون بهترین مدل را به دست آورد. همچنین می تواند نظریه ها را به وسیله برقراری ارتباط که پیش بینی شده اند یا مورد شک هستند تحلیل کند و از این طریق بهترین مدل را بدست آورد.
تحلیل چند متغیره تحلیل مسیر
تحلیل مسیر روش آماری به کار بردن ضرایب بتای استاندارد رگرسیون چند متغیرى در مدل هاى ساختاری است. هدف تحلیل مسیر به دست آوردن تخمین های کمى روابط علّى بین گروهی از متغیرهاست. ساختن یک مدل علّی الزاما به معنای وجود روابط علّی در بین متغیرهای مدل نیست بلکه این روابط علی بر اساس فرضیه های همبستگی و نظریه و پیشینه تحقیق استوار است. تحلیل مسیر به ما می گوید که کدام مسیر مهمتر و یا معنادارتر است.
ضرایب مسیر براساس ضریب استاندارد شده رگرسیون تحلیل مى شود. یک متغیر به صورت مجموعه ای از دیگر متغیرها در نظر گرفته مى شود و مدل رگرسیونى آن طرح مى شود. برای بدستآوردن تخمین های ضرائب اصلی مسیر کافی است هر متغیر وابسته (درونزا) به متغیرهائی که مستقیماً تحت تأثیر آن است برگردانده می شود.
به بیان دیگر برای تخمین های هر یک از مسیرهای مشخص شده، ضرائب استانداردشده رگرسیون (یا ضرائب مسیر) مورد محاسبه قرار می گیرد. این ضرائب از طریق ایجاد معادلههای ساختاری یعنی معادلههائی که ساختار روابط در نظر گرفته شده در یک مدل را معین میسازد به دست میآیند. تحلیل مسیر صرفًا بر روی متغیرهای دیده شده قابل انجام است.
مشروط کردن مدل نظری
برای ساختن یک مدل از طریق تحلیل مسیر، ده شرط بیان شده است که به کمک آنها، امکان تجزیه و تحلیل علّی فراهم میشود. درده شرط بحث، شده هفت شرط اول مدل نظری مناسبی را برای تجزیه و تحلیل و نتیجه گیری علّی ایجاد می کند
. بیان رسمی نظری در قالب مدل ساختاری ۲. وجود منطق نظری برای فرضیههای علّی ۳. مشخص نمودن نظم علّی ۴. مشخصنمودن مسیر روابط علّی ۵. نوشتن معادلات توابع ۶. معین نمودن مرزهای مدل ۷. ثابت بودن مدل ساختاری ۸. کاربردیکردن متغیرها ۹. تأیید تجربی معادلات کاربردی ۱۰. نتیجه گیری مدل ساختاری از طریق دادههای تجربی
اصول طرح نمودار مسیر
نبود حلقه ۲. نبود مسیر رفت و برگشت بین متغیرها ۳. حداکثر تعداد رابطه های اجازه داده شده بین متغیرهای درونی برابر با تعداد مسیرها در تحلیل مسیر یک متغیر ممکن است همزمان هم نقش متغیر مستقل و یا وابسته را داشته باشد . به عبارت دیگر یک متغیر در مدل علّی ممکن است نسبت به بعضی متغیرها مستقل و نسبت به بعضی دیگر وابسته باشد. برای جلوگیری از ابهام و سردرگمی به جای مستقل و وابسته از دو عنوان دیگر برای مشخص کردن نوع متغیرها در روش تحلیل مسیر استفاده می شود.
متغیر های درونی و بیرونی
کلیه متغیرهای موجود در یک مدل و الگوی علی دارای دو نوع اصلی است. نوع اول متغیر برونی است و نوع دوم متغیر درونی نام دارد. متغیر بیرونی متغیری است که هیچ تاثیری از سایر متغیرهای الگو و مدل طراحی شده قبول نمی کند. در حقیقت مقدار متغیر ببیرونی توسط بقیه متغیرهای درونی مدل مشخص نمی شود بلکه مقدار آن دربیرون از مدل مشخص می شود. متغیر درونی (وابسته) متغیری است که از حداقل یک متغیر دیگر در مدل و الگوی طراحی شده تاثیر می گیرد. مقدار متغیر وابسته توسط سایر متغیرهای درونی مدل مشخص می شود. بنابراین بر اساس تعریف یک متغیر نمی تواند همزمان هم وابسته و هم مستقل باشد. از نظر نموداری متغیر مستقل متغیری است که با هیچ فلشی نشان داده نمی شود در حالیکه متغیر وابسته متغیری است که حداقل یک فلش به سمت آن می رود و توسط یک فلش نشان داده می شود.
مسیر
مسیر در مدل علّی نشان دهنده تاثیر یک متغیر بر متغیر دیگر است. در تحلیل مسیر معمولا مسیر را با یک فلش جهت دار یک جهته که ازمتغیر مستقل به متغیر مربوطه وابسته رسم شده است نشان می دهند. نمایش تحلیل مسیر دارای یک نمایش ریاضی است که به صورت عمومی داده می شود. حرف i نشان دهنده متغیر مستقل حرف jنشان گر متغیر وابسته است و همواره اصل j>I برقرار است به عبارت دیگر I متغیر ی است که تحت تاثیر قرار می گیرد و j متغیری است که تاثیر می گذارد بر روی آن . پس مسیر فرضی ۴۱ pیعنی یک متغیر بر چهار متغیر دیگر موثر است یا این که متغیر یک متغیر مستقل و متغیرچهار متغیر وابسته است
جملات اشتباه
جمله اشتباه نشان دهنده میزانی از واریانس متغیر وابسته است که از سوی متغیرهای موثر بر آن تحلیل می شود بنابراین در یک مدل علّی به تعداد متغیرهای وابسته، جمله اشتباه وجود دارد. جمله اشتباه را معمولا با حرف e یا d نشان می دهند.
طراحی مدل مسیر
محقق بر اساس تحقیقات قبلی مشابه و دارای ارتباط شروع به انتخاب متغیرها و تعیین روابط علّی بین آنها بر اساس منطق تحلیلی و نظری می نماید. نتایج این مرحله ممکن است گروهی از فرضیه های مرتبط و منسجم باشد که معمولا از طریق طرح و یا مدل ریاضی بیان می شود. در تحقیقات علوم اجتماعی مدلهای مفهومی معمولا به شکل رسم کردن مدل و رسم نمودار بیان می شوند.
انواع مدلهای تحلیل مسیر
مدل متغیرهای مستقل : همان رگرسیون چندگانه است اما بین متغیرهای مستقل ۲. همبستگی برقرار نمی شود. ۳. مدل وابسته : مدل وابسته همانند مدل مستقل است با این تفاوت که بین برخی متغیرهای مدل رابطه وجود دارد. ۴. مدلهای دارای متغیر تعدیل کننده : حداقل یک متغیر تعدیل کننده بین دو متغیر دیگر قرارمی گیرد. ۵. مدلهای دارای متغیر میانجی : یک متغیر بر ارتباط بین دو متغیر دیگر اثر تعدیل کننده دارد. ۶. مدلهای یک طرفه :جهت فلشها به یک طرف بوده و برگشت به عقب ندارد یعنی همه مسیرها به یک سمت هستند. ۷. مدلهای دوطرفه : جهت فلشها و مسیرها دارای حرکت به طرف عقب بوده و یک حلقه درست می کند. این نوع مدلها در مطالعات علوم اجتماعی و جامعه شناسی زیاد استفاده نمی شود .
آزمون مدل نظری
برای تحلیل مدل نظری می توان از رگرسیون در نرم افزار اس پی اس اس و معادلات ساختاری در نرم افزارهایی مانند .. آموس و لیزرل استفاده نمود. در نرم افزار اس پی اس اس به تعداد متغیرهای وابسته باید از گزینه رگرسیون خطی چندگانه و یا ساده استفاده نمود. لیکن در نرم افزار آموس مدل نظری تحقیق به صورت یکجا تحلیل می شود
انواع رابطه بین متغیرها در نمودار تحلیل مسیر
دو روشی که یک متغیر مستقل ممکن است بر یک متغیر وابسته تأثیر بگذارد. ۱. اثر مستقیم: نشان دهنده یک اثر مستقیم متغیر x بر روی متغیر y است (x1 ® y ) 2. اثر غیر مستقیم: یک اثر غیرمستقیم متغیر x بر روی y از طریق یک متغیر مستقل دیگر.رابطه بین X و Y وقتى غیر مستقیم است که X علت Z است و Z نیز به نوبه خود در Y تاثیر می گذارد . بسیاری از پژوهشگران تمایل دارند اثر کلی یک متغیر را بر متغیر دیگر حساب کنند کنند این کار با استفاده از روش جمع اثر مستقیم با مجموع آثار غیرمستقیم آن به دست میآید. آثار غیرمستقیم از طریق حاصلضرب ضرائب هر مسیر بدست می آید : ۳. اثر نامشخص: رابطه بین X و Y وقتى نامشخص است که Z علت هر دو متغیر X و Y باشد. ۴. اثرات تبیین نشده: رابطه بین دو متغیر وقتى تبیین نشده است که هر دوى آنها مستقل بوده و بنابراین تبیین تغییر پذیرى بین آنها توسط مدل ما ممکن نباشد
بوجود آورندگان آزمون تحلیل مسیر
تحلیل مسیر در سال ۱۹۱۸ توسط سیول رایت طرح شد که تا سال ۱۹۲۰ مطالب بسیاری را در مورد آن نوشته است. و از آن زمان برای مدل سازی های پیچیده در زمینه روان شناسی، اقتصاد و جامعه شناسی به کار رفت
نوع آزمون تحلیل مسیر (توضیح علت پارامتریک ؛ ناپارمتریک و …)
آزمون تحلیل مسیر جزء آزمون های نرمال بحساب می آید دلایل آن به شرح زیر می باشد: ۱. هر یک از موارد مشاهده شده مستقل است، یعنی اینکه انتخاب یک مورد به انتخاب مورد دیگری وابسته نیست. ۲. واریانس متغیرها مساوی یا تقریبا مساوی است. ۳. توصیف متغیرها براساس مقیاس فاصله ای یا نسبی انجام می گیرد. ۴. توزیع نمره ها در جامعه نرمال یا نزدیک به توزیع نرمال است
شرایط استفاده از آزمون تحلیل مسیر (در مقیاس اسمی، ترتیبی و ..)
برخی از فرضیه های به کار گیری تحلیل مسیر به شرح زیر می باشد: ۱. کالین سفارش می کند که به ازای هر شاخص ( نه متغیر) در مدل حداقل ۱۰ مورد به محدوده نمونه اضافه باید کرد . در نظر گرفتن نسبت ۲۰ نمونه برای هر شاخص بسیار خوب است . ۲. مقیاس فاصله ای و نسبتی بودن برای متعیرهای مدل. اگر چه در مطالعات علوم اجتماعی از طیف لیکرت به مقدار زیادی استفاده می شود و این مقیاس رتبه ای است لیکن بسیاری از محققان مقیاس لیکرت را بصورت ، مقیاس فاصله ای در نظر می گیرند. ۳. وجود رابطه خطی بین متغیرهای مستقل با متغیر وابسته ۴. غیر همبسته بودن جملات اشتباه متغیرها . ۵. نرمال بودن داده ها و مشخص کردن آن با آزمون ۶. عدم وجود وابستگی چندگانه : وابستگی چندگانه زمانی ایجاد می شود که بین حداقل دو متغیر مستقل همبستگی زیادی وجود داشته باشد. ۷. تک بودن متغیرها : یک متغیر از ترکیب دو متغیر غیر اصلی بوجود آمده باشد و متغیرهای فرعی دارای رابطه دارای علامت مشابه با سایر متغیرها باشد. ۸. تجزیه همبستگی : همبستگی = اثرات مستقیم + اثرات غیرمستقیم
به کار گیری آزمون تحلیل مسیر
آزمون تحلیل مسیر امکان آزمون روابط علی بین دو یا چند متغیر رابوجود می آورد ، که ممکن است به صورت مستقل، وابسته، گسسته یا پیوسته، پنهان یا آشکار و یا هر دو در یک معادله دارای رابطه همبستگی به کار روند)
حل مثال با نرم افزار اس پی اس اس spss
به منظور بررسی رابطه بین سرمایه روانشناختی و مشغولیت تحصیلی با میانجی انگیزه پیشرفت در دانش آموزان دختر پایه اول متوسطه پژوهشی انجام گرفت که تعداد ۱۰۰ دانش آموز پسر پایه اول متوسطه به عنوان نمونه برای تحقیق انتخاب شدند و فرضیه های زیر مورد تحلیل قرار گرفت: فرضیه ۱. سرمایه روانشناختی بر انگیزه پیشرفت تاثیر مثبت دارد. فرضیه ۲. سرمایه روانشناختی بر مشغولیت تحصیلی تاثیر مثبت دارد. فرضیه ۳. انگیزه پیشرفت بر مشغولیت تحصیلی تاثیر مثبت دارد. فرضیه ۴. سرمایه روانشناختی از طریق انگیزه پیشرفت بر مشغولیت تحصیلی اتاثیر مثبت دارد. این روابط در الگوی پیشنهادی حاضر در نمودار ۱ نشان داده شده اند.
آموزش روش تحلیل مسیر در اس پی اس اس
همانگونه که نتایج جدول ۱ نشان می دهد، میانگین و انحراف معیار آزمودنی های کل نمونه (۱۰۰) به ترتیب در سرمایه روانشناختی (۱۴۵) و (۲۳.۳۴)، انگیزه پیشرفت (۴۵/۷۵) و (۶۳/۷) و مشغولیت تحصیلی (۷۳/۶۸) و (۲۹/۴۲) است.
میانگین و انحراف معیار هر یک از خرده شاخص های پنهان به طور مفصل در جدول ۱ ارائه شده است.
آموزش روش تحلیل مسیر در اس پی اس اس spss
رابطه همبستگی متغیرهای پژوهش در جدول ۲ نشان داده شده است.
آموزش روش تحلیل مسیر در اس پی اس اس spss
همانطور که نتایج جدول ۲ نشان می دهد، همه رابطه های همبستگی بین متغیرها در سطح ۰۱/۰ معنی دار هستند. این تحلیل های همبستگی نظریه ای در خصوص روابط دومتغیری بین متغیرهای پژوهش را ایجاد میکنند.
جهت آزمودن همزمان روابط درنظر گرفته شده در پژوهش حاضر، روش الگویابی معادلات ساختاری اجرا شده است. نمودار ۲ الگوی پایانی پژوهش حاضر و ضریب های مسیر در میان متغیرها را نشان می دهد.
آموزش روش تحلیل مسیر در اس پی اس اس spss
جدول ۳ الگوی ساختاری، مسیرها و ضریب های استاندارد آن ها در الگوی نهایی این پژوهش را نشان می دهد. جدول ۳ نشان می دهد که همه ضریب های مسیرهای مستقیم در الگوی نهایی معنی دار هستند.
آموزش روش تحلیل مسیر در اس پی اس اس spss
یافته های مربوط به فرضیه های الگوی پیشنهادی
در این بخش ابتدا مسیرهای مستقیم الگو و سپس یافته های مربوط به مسیرهای غیرمستقیم (به طور واسطه ای ) گزارش می شوند.
مسیرهای مستقیم الگوی مطرح شده
یافته های مربوط به فرضیه های مستقیم الگوی مطرح شده با توجه به نتایج جدول ۳ مورد بررسی قرار می گیرند:
فرضیه ۱. سرمایه روانشناختی بر انگیزه پیشرفت تاثیر مثبت دارد. سرمایه روانشناختی + انگیزه پیشرفت با توجه به جدول شماره ۳ ضریب مسیر سرمایه روانشناختی با انگیزه پیشرفت معنیدار می باشد (۲۵۵/۰ =β، ۰۰۳/۰ =Ƥ(. این نتیجه ، فرضیه ۱ را تأیید می کند.
فرضیه ۲. سرمایه روانشناختی بر مشغولیت تحصیلی تاثیر مثبت دارد. سرمایه روانشناختی + مشغولیت تحصیلی با توجه به جدول شماره ۳ ضریب مسیر سرمایه روانشناختی به مشغولیت تحصیلی معنی دار میباشد (۷۹۹/۰ =β، ۰۰۰۱/۰ =Ƥ(. این نتیجه ، فرضیه ۲ را تأیید می کند.
فرضیه ۳. انگیزه پیشرفت بر مشغولیت تحصیلی تاثیر مثبت دارد. انگیزه پیشرفت + مشغولیت تحصیلی با توجه به جدول شماره ۳ ضریب مسیر انگیزه پیشرفت به مشغولیت تحصیلی معنی دار می باشد (۲۱۲/۰ =β، ۰۰۴/۰ =Ƥ(. این نتیجه ، فرضیه ۳ را تأیید می کند.
مسیرهای غیرمستقیم الگوی مطرح شده
با توجه به مسیرهای غیرمستقیم مطرح شده به بررسی روابط تعدیل کننده متغیرهای مدل مطرح شده در پژوهش حاضر می پردازیم .
یافته های مربوط به روابط واسطه ای متغیرهای مطرح شده
در این بخش نتایج حاصل از آزمون فرضیه های مربوط به مسیرهای غیرمستقیم و تاثیرهای واسطه-ای بیان خواهند شد. در این پژوهش، ۱ فرضیه بر اساس وجود روابط غیرمستقیم است.
فرضیه ۴. سرمایه روانشناختی از طریق انگیزه پیشرفت بر مشغولیت تحصیلی تاثیر مثبت غیرمستقیم دارد.
برای تعیین معنی داری روابط واسطه ای، از بوت استراپ استفاده شده است. جدول ۴ نتایج حاصل از بوت استراپ در برنامه ماکرو، پریچر و هیز (۲۰۰۸) را در رابطه سرمایه روانشناختی و مشغولیت تحصیلی با میانجی گری انگیزه پیشرفت نشان می دهد.
آموزش روش تحلیل مسیر در اس پس اس اس spss
مطابق با جدول ۴ محدوده پایین محدوده اطمینان برای انگیزه پیشرفت به عنوان متغیر تعدیل کننده بین سرمایه روانشناختی و مشغولیت تحصیلی (۰۲۳۶/۰) و حد بالای آن (۱۳۶۶/۰) است.
محدوده اطمینان برای این محدوده اطمینان ۹۵ و تعداد نمونه گیری مجدد بوت استراپ ۲۰۰ است. با توجه به اینکه صفر بیرون از این محدوده اطمینان قرار می گیرد، این رابطه با واسطه معنی دار بوده و فرضیه ما مورد تأیید قرار می گیرد.
تحلیل آماری با کم ترین هزینه و بالاترین کیفیت انجام می گیرید. تحلیل داده های آماری با نرم افزارهای کمی و کیفی نرم افزار های کمی SPSS و PLS و Amos نرم افزار های کیفی: Maxquda و Nvivo تعیین حجم نمونه با:Spss samplepower کافی است قیمت ها را با جاهای دیگر مقایسه کنید. کیفیت بالا، قیمت مناسب و خدماتی که به نیازهای شما پاسخ می دهند! با ما همراه باشید و پژوهش خود را به یک تجربه ی موفق تبدیل کنید.
انجام پژوهش کیفی.jpg
خدمات تخصصی پژوهش و تحلیل داده های آماری با مناسبترین قیمت و کیفیت برتر!
SPSS (نام کامل: Statistical Package for the Social Sciences) یکی از متداولترین و قدرتمندترین ابزارها برای تحلیل دادههای آماری در زمینههای مختلف از جمله علوم اجتماعی، علوم رفتاری، بهداشت، اقتصاد و … است.
در اینجا به توضیحات مختصری درباره چگونگی تحلیل آماری با استفاده از SPSS میپردازیم:
1. ورودی دادهها به SPSS:
ابتدا، دادههای خود را به فرمت متنی یا اکسل آماده کنید و سپس آنها را به نرمافزار SPSS وارد کنید. معمولاً دادهها به صورت جدول وارد میشوند که هر ستون مربوط به یک متغیر و هر سطر مربوط به یک مشاهده (نمونه) است.
2. توصیف آماری:
متغیرها: بررسی و توصیف متغیرها شامل میانگین، واریانس، مد، میانه و… است. این اطلاعات به توصیف متغیرها کمک میکند.
جمعیت و نمونه: اطلاعات مربوط به تعداد مشاهدات (نمونه) و اطلاعات مختصر درباره ویژگیهای جمعیتی.
3. آزمونهای آماری:
SPSS به شما امکان ترکیبی از آزمونهای آماری کلاسیک و پیشرفته را فراهم میکند:
آزمون t (تی-آزمون): برای مقایسه میانگین دو گروه.
آنالیز واریانس (ANOVA): برای مقایسه میانگین بیش از دو گروه.
رگرسیون و کوواریانس: برای بررسی ارتباط بین متغیرها.
آزمونهای همبستگی: بررسی رابطه بین متغیرها.
4. گزارشگیری:
نتایج تحلیلهای آماری به صورت گزارشهای استانداردی ارائه میشوند که شامل نمودارها، جداول و تفسیر نتایج آماری است. این گزارشها میتوانند به عنوان اسناد معتبر برای ارائه نتایج به دیگران (مثلاً همکاران یا استادان) استفاده شوند.
برای یادگیری بیشتر و استفاده بهینه از SPSS، میتوانید از منابع آموزشی آنلاین، کتابها، دورههای آموزشی محلی یا دورههای آموزشی آنلاین استفاده کنید. همچنین، وبسایت رسمی SPSS منابع و آموزشهای آنلاین بسیار مفیدی را برای یادگیری این نرمافزار ارائه میکند.
کیفیت بالا، قیمت مناسب و خدماتی که به نیازهای شما پاسخ میدهند!
با ما همراه باشید و پروژهی خود را به یک تجربهی موفق تبدیل کنید.
درود بر شما کاربر محترم و بزرگوار، به عرض می رساند امروزه هزینه های نگهداری و ارتقای سایت بالا می باشد، لذا جهت ادامه فعالیت مجبور شدیم در بعضی از جاها تبلیغ بگذاریم.
لطفاً با کلیک بر روی لینک های زیر از ما حمایت کنید تا بتوانیم خدمات بهتری ارائه دهیم. مطمئن باشد هیچ مشکلی برای شما پیش نخواهد آمد.
با تشکر.
،
تعیین حجم نمونه در روش تحقیق به روشها و فرمولهایی اشاره دارد که برای محاسبه تعداد نمونه معرف جامعه آماری مورد استفاده قرار میگیرد. مهمترین تصمیم برای تعمیمپذیری نتایج یک تحقیقات علمی انتخاب یک نمونه معرف جامعه است. اگر نمونه به خوبی نتواند ویژگیهای جامعه را دربرگیرد استفاده از بهترین روش آماری نیز فاقد وجهات لازم برای استناد میباشد.
در مباحث جامعه و نمونه نباید روشهای تعیین حجم نمونه با روشهای نمونهگیری اشتباه گرفته شود. روش نمونهگیری شیوه دستیابی به حداقل نمونهای است که محاسبه شده است. یعنی ابتدا باید با یک روش صحیح حجم نمونه تعیین شود. پس از آن با یک روش مناسب به نمونه برآورد شده دست پیدا کرد.
نظر به اهمیت تعیین اندازه نمونه و از سوی دیگر روشهای مختلف تحلیل آماری، روشهای متعددی برای محاسبه حجم نمونه معرفی شده است. البته پژوهشگران ایرانی به طور مرسوم برای تعیین اندازه نمونه به سراغ فرمول کوکران میروند که اشتباه بسیار بزرگی است. در این آموزش کوشش شده است تا روشهای مختلف تعیین حجم نمونه تشریح شود.
۱- تعیین حجم نمونه با فرمول کوکران
فرمول کوکران پرکاربردترین شیوه در تعیین حجم نمونه است. فرمول کوکران بهصورت زیر محاسبه میشود:
فرمول کوکران
در این فرمول N حجم جامعه است.
آماره p درصد توزیع صفت در جامعه یعنی نسبت افرادی است که دارای صفت موردمطالعه هستند.
آماره q نیز درصد افرادی است که فاقد صفت مورد مطالعه هستند.
اگر میزان p و q مشخص نباشد از حداکثر مقدار آنها یعنی ۰/۵ استفاده کنید.
آماره z=t است و اگر به جای z از t استفاده کنید نیز ایرادی ندارد. درسطح خطای ۵% مقدار z برابر ۱/۹۶ و و Z2 برابر ۳/۸۴۱۶ است.
مقدار d نیز تفاضل نسبت واقعی صفت در جامعه با میزان تخمین پژوهشگر برای وجود آن صفت در جامعه است. دقت نمونهگیری به این عامل بستگی دارد و اگر بخواهید نمونهگیری دارای بیشترین دقت باشد از حداکثر مقدار d برابر ۰/۰۵ استفاده کنید.
۱-۱- تعیین حجم نمونه با جدول مورگان
جدول مورگان یکی دیگر از روشهای محاسبه حجم نمونه است. اگر حجم جامعه معلوم باشد سادهترین روش برای تعیین حجم نمونه رجوع به جدول مورگان است. زمانی که نه از واریانس جامعه و نه از احتمال موفقیت یا عدم موفقیت متغیر اطلاع دارید و نمی توان از فرمولهای آماری برای براورد حجم نمونه استفاده کرد از جدول مورگان استفاده میکنیم.
آیا جدول مورگان و فرمول کوکران تفاوت دارند؟
هیچ تفاوتی بین جدول کریسی-مورگان و فرمول کوکران وجود ندارد. در واقع دو پژوهشگر به نامهای کریسی (کرجسی) و مورگان اعداد مختلف را در فرمول کوکران در سطح خطای ۵% قرار داده اند و حجم نمونه حاصل در یک جدول ارائه کردهاند. به صفحه محاسبه آنلاین حجم نمونه با فرمول کوکران رجوع کنید و نتایج را با جدول کرجسی و مورگان مقایسه کنید.
۲-۱- محاسبه حجم نمونه برای جوامع نامعلوم
در برخی موارد پارامتر N یعنی حجم جامعه به دلایلی مشخص نیست. اگر حجم جامعه نامعلوم باشد از فرمول کوکران به صورت زیر استفاده میشود:
روشهای محاسبه حجم نمونه (حجم جامعه نامعلوم)
در این فرمول مهمترین پارامتری که نیاز به برآورد دارد S² است که همان واریانس نمونه اولیه است. برای محاسبه S² تعدادی پرسشنامه توزیع شده و واریانس نمونه اولیه محاسبه میشود.
مقدار Z2 یک مقدار ثابت است که به فاصله اطمینان و سطح خطا (α) بستگی دارد. معمولاً سطح خطا ۵% یا ۱% در نظر میگیرند. برای مثال اگر سطح خطا یا سطح معناداری (significant level) برابر ۵% در نظر گرفته شود سطح اطمینان برابر با ۹۵% خواهد بود. در نتیجه Z2 با توجه به جدول آماری ۱/۹۶ خواهد بود.
مقدار d نیز براساس همان سطح خطا یا برابر ۰/۰۵ در نظر گرفته میشود.
مثال: در یک پژوهش ذیحسابان دستگاههای اجرائی کشور جامعه آماری پژوهش را تشکیل میدهند. جهت تعیین حجم نمونه یک مطالعه مقدماتی با توزیع پرسشنامه بین ۲۰ نفر از ذیحسابان دستگاههای اجرائی کشور انجام شد و با برآورد واریانس نمونه اولیه در سطح اطمینان ۹۵ درصد، حجم نمونه از طریق فرمول زیر محاسبه گردید:
n= (3.8416 × ۰.۰۵۳۲) ÷ ۰.۰۰۲۵ ≈ ۸۲
با توجه به محاسبات انجام شده ۸۲ نفر به عنوان نمونه آماری مورد مطالعه برآورد گردید.
۳-۱- محاسبه حجم نمونه برای جوامع نامعلوم و واریانس نامعلوم
چون حجم جامعه مشخص نیست و اطلاعی از واریانس جامعه در دسترس نیست از فرمول زیر حجم نمونه مشخص شده است:
برآورد واریانس نمونه
همچنین چون پرسشنامه با طیف لیکرت ۵ درجه استفاده شده است، بزرگ ترین مقدار ۵ و کوچکترین مقدار ۱ خواهد بود بنابراین انحراف معیار آن برابر است میتوان از مقدار ۰.۶۶ استفاده کرد. این مقدار بیشینه انحراف معیار است. همچنین سطح اطمینان ۹۵% و دقت برآورد ۰.۰۱ درنظر گرفته شده است بنابراین حجم نمونه برابر است با:
Zα/۲ = ۱.۹۶ , ε = ۰.۰۱, σ=۰.۶۶ => n = 170
۴-۱- محاسبه حجم نمونه برای جوامع خیلی بزرگ
اگر حجم جامعه خیلی بزرگ باشد از فرمول کوکران برای جوامع نامعین به صورت زیر استفاده میشود.
فرمول کوکران برای جوامع نامعین
برای مثال در تحقیقات پیرامون مشتریان، دانشجویان، دانشآموزان، شهروندان و … حجم نمونه ۳۸۴ نفر تخمین زده میشود. برای جوامع محدود با حجم مشخص از فرمول ارائه شده در ابتدای این بحث استفاده کنید.
۲- تعیین حجم نمونه براساس توان آزمون
فرمول کوکران برای محاسبه حجم نمونه روشی منسوخ است که هنوز مورد تاکید پژوهشگران داخلی است. در مطالعات اخیر از فرمول کوهن براساس اندازه اثر و توان آزمون برای تعیین حجم نمونه استفاده میشود. یک مزیت دیگر این روش آن است که تعداد متغیرهای اصلی و سوالات پرسشنامه نیز در محاسبه حجم نمونه دخیل است.
رای محاسبه حجم نمونه با فرمول کوهن به صورت آنلاین به سایت Danielsoper وارد شوید.
مطابق دستور مقادیر کادر زیر را تکمیل کنید:
محاسبه حجم نمونه براساس توان آزمون
روش محاسبه حجم نمونه با فرمول کوهن
اندازه اثر شاخصی است که قدرت اثرگذاری متغیرهای مستقل مدل را نشان میدهد. براساس نظر کوهن (۱۹۸۸) میزان این شاخص به ترتیب ۰/۰۲ (ضعیف) ۰/۱۵ (متوسط) و ۰/۳۵ (قوی) میباشد. بنابراین بهتر است این مقدار حداقل روی ۰/۱۵ تنظیم شود.
توان آزمون Desired statistical power level مقداری بین ۸۰ تا ۹۰ درصد انتخاب میشود. آزمون حداقل باید توانی برابر با ۰/۸ داشته باشد.
تعداد متغیرهای پنهان و آشکار نیز براساس پرسشنامه و مدل پژوهش قابل تعیین است.
در نهایت سطح اطمینان را میتوانید ۹۹% یا ۹۵% در نظر گرفته و به ترتیب از ۰/۰۵ یا ۰/۰۱ استفاده کنید.
۳- تعیین حجم نمونه خبرگان
در برخی از تحقیقات مانند تحقیقات مبتنی بر تصمیمگیری چندمعیاره یا مطالعات کیفی با تعداد محدودی از خبرگان سروکار داریم. در این موارد معمولا باید ملاحظات خاصی درنظر گرفته شود و فرمول کوکران مصداق ندارد. مطلب روشهای نمونهگیری هدفمند و نمونهگیری خبرگان را مطالعه کنید.
تعیین حجم نمونه و برآورد تعداد نمونه لازم که معرف ویژگیهای یک جامعه آماری باشد از مباحث مهم روش تحقیق است. به طور سنتی برای این منظور از فرمول کوکران استفاده میشود. همچنین اگر حجم جامعه معلوم باشد راهکار سادهتر آن است که از جدول مورگان استفاده شود. اگر حجم جامعه نامعلوم اما محدود باشد میتوان از فرمول کوکران با برآورد واریانس نمونه اولیه استفاده کرد. اگر حجم جامعه نامعلوم و اندازه آن بسیار بزرگ باشد استفاده از فرمول کوکران به عدد ۳۸۴ ختم میشود. در مطالعات اخیر مدیریت و علوم اجتماعی از اندازه اثر و توان آماری برای محاسبه حجم نمونه استفاده میشود. با این روش میتوان با اطمینان بیشتری به نمونهگیری پرداخت.
یکی از مهمترین عوامل برای شرکتهای بزرگ در خارج از کشور یا موسسات داخلی و درآمد آنها، استفاده از علم تحلیل آمار است؛
زیرا با کمک این علم نوین میتوانند به پیشبینیهای بسیار جامع و کاملی از روند برخی موارد دست پیدا کنند
و به علاوه، گزارش دقیقی از وضعیت حال را در اختیار بگیرند. همچنین، ممکن است بارها با مسئله ارائه پایان نامه توسط spss رو به رو شده باشید.
این نرم افزار توسط شرکت آی بی ام طراحی و توسعه داده شده است.
برای تحلیل آماری نرمافزارهای زیادی طراحی شدهاند که معروفترین آنها، نرمافزار spss یا نرمافزار بسته آماری برای علوم اجتماعی است.
به دلیل اهمیت این نرمافزار در جامعه آماری، مقالهای جامع درباره این نرمافزار تهیه شده است.
اگر میخواهید ببینید spss چیست و به دنبال آموزش این نرمافزار هستید، ادامه مقاله را از دست ندهید.
آشنایی کلی با نرم افزار spss
نرمافزار SPSS یا Statistical Package for the Social به عنوان یک نرمافزار تحلیلی و آنالیز اطلاعات، از پرسشنامهها و فرمهای مختلف دریافت میکند
و سپس آنها را در قالب جداول و نمودارها به کاربر ارائه میدهد تا تجزیه و تحلیل آنها به صورت دقیقتر صورت پذیرد.
این نرمافزار در زمینه بازار و داد و ستد، سلامتی، نقشهبرداری دولتی و آموزشی توسط پژوهشگران به کار گرفته میشود.
کاربردهای نرم افزار spss چیست؟
بعد از اینکه با زبان ساده به پاسخ spss چیست رسیدید، نوبت به این میرسد که کاربردهای این نرم افزار آماری را مورد بررسی قرار دهید.
به این ترتیب است که اهمیت آشنایی با آن را بیشتر درک میکنید.
به طور کلی میتوان کاربردهای زیرا را برای این نرمافزار بیان کرد:
– این نرم افزار توسط پژوهشگران در شرکت های دولتی و نقشه برداری و سازمان های آموزشی و بازاریابی استفاده میشود. – انواع آمار توصیفی را با جداول همراه با ذکر بسامد ها و کاوشها به صورتی دقیق و نسبی ارائه میدهد. – برای به دست آوردن آمارهای دو یا چند متغیر کاربرد دارد. نمونه آن تحلیل پراکنش و همبستگی آزمونهای استخدامی است. – درآمدها را به صورت نسبی و دقیق پیش بینی و ارائه میکند. – انواع آمارها را به صورت تحلیل بندی و خوشه ها بررسی و توصیف خواهد کرد. – خلاصه آماری گراف ها، جداول و نمودارهای آماری و توزیع های گسسته و پیوسته را به دست میآورد. – رگرسیون را مورد پردازش قرار میدهد. علاوه بر این کاربردها میتوان استفاده از نرم افزار spss را در رشتههای مختلف مورد بررسی قرار داد.
– Spss و صنایع
بیشتر افراد با کاربرد گسترده این نرمافزار در حوزه های علمی و پژوهشی آشنا هستند. با این حال بهتر است مسئله spss چیست در رشته صنایع نیز مورد بحث قرار بگیرد.
حتی میتوان این ابزار را یکی از شیوه های پرکاربرد در رشته صنایع به حساب آورد. زیرا در این حوزه علاوه بر مباحث تحلیلی و آماری،
نرم افزار spss بستر خوبی برای داده کاوی و تحلیل اطلاعات حاصل از بخش های تولیدی، فروش، تدارکات و نیروی انسانی به شمار میرود.
– Spss و کشاورزی
استفاده از آزمون های آنالیز واریانس در پایان نامه ها متداول ترین شیوه استفاده اس.پی.اس.اس در کشاورزی است.
تحلیل های آماری در طرح های آزمایشی کشاورزی به ویژه در دنیای پیشرفته امروز برای توسعه خود به ایده های خلاقانه احتیاج دارند. بنابراین بهترین گزینه برای آنها spss است.
– Spss و روانشناسی
روانشناسی از جمله علوم های پژوهشی محور است که تنها با تحلیل دادههای آماری میتواند نتایجی را برای فرضیات در نظر بگیرد.
بنابراین کار با نرم افزار spss است که به آنها فرصت تحلیل دادههای به دست آمده را با توجه به پرسشنامه های متعدد در این حوزه میدهد.
سپس با بررسی و تحقیقات روی این دادها است که به بهترین نتیجه دست پیدا میکنند.
– Spss و پزشکی
نتیجه تحقیقات و آزمایشات پزشکی را میتوان در نرم افزار spss مورد تحلیل و بررسی قرار داد. آزمون های آماری طراحی شده در این برنامه اسن امکان را به خوبی فراهم کردهاند.
برای مثال میتوان به آزمون هایی چون آزمون t ، آزمون نسبت ، آزمون مقایسه و میانگین، آنالیز و بررسی واریانس، رگرسیون و آزمون های ناپارامتری اشاره کرد.
– Spss و اقتصاد
تحلیل گران اقتصادی نیز به پاسخ spss چیست، احتیاج پیدا میکنند.
زیرا با کمک این نرم افزار است که آنالیز فرآیند های اقتصادی را انجام داده و با توجه به نتیجهی آماری تاثیر هر عامل اقتصادی بر سایر عوامل را مورد تحلیل و بررسی قرار میدهند.
– پایان نامه با spss
در نوشتن پایان نامه دکترا و کارشناسی ارشد یکی از پرکاربردترین نرمافزارها، spss است.
تحلیل و بررسی داده های آماری در فصل 4 پایان نامه با کمک از برنامه اس.پی.اس.اس انجام میشود و آن دسته افرادی که با این نرمافزار آشنایی ندارد،
باید هزینه زیادی برای انجام این فصل از پایان نامه به افراد متخصص پرداخت کنند تا کار آن ها انجام دهند.
از جمله کاربردهای نرم افزار آماری SPSS میتوان به موارد زیر اشاره کرد:
تحلیل و آنالیز دادههای وارد شده
انجام تحقیقها و پایان نامههای آماری
ایجاد جدولهای فراوانی و نتیجه گیریهای آماری
تهیه جداول و نمودارهای آماری
بدست آوردن توزیعها و رفتار دادههای وارد شده
بدست آوردن دادههای تصادفی
پردازش انواع رگرسیون
محاسبه انواع آزمونهای آماری
انجام تحلیل واریانسهای یک طرفه، دو طرفه و چند طرفه
ایجاد طرحهای آماری
نرم افزار آماری SPSS برای افرادی که قصد ورود به حوزه علم داده را دارند هم مناسب است؛ چرا که ساخت مدلهای توصیفی، پیش بینانه، استقرار مدلهای مبتنی بر یادگیری ماشین و آمار جز وظایف یک متخصص علم داده است.
میتوان گفت SPSS علاوه بر کاربرد فراوان در حوزههای آماری، تحلیلی و علم داده و استفاده آسان و وجود طیف وسیعی از امکانات در منوی نرم افزار SPSS عاملی برای محبوبیت آن در بین سایر نرم افزارهای آماری شده است،
البته جامع بودن خروجیها، راحتی تبدیل خروجی به فرمتهای دیگر از دیگر مزیتهای این نرم افزار آماری است.
در حال حاضر نسخههای 22 و26 از نرم افزار SPSS قابل نصب در کامپیوتر با ویندوز 10 است؛
در ادامه با نحوه کار کردن با SPSS و پستی و بلندیهای آن و همچنین کاربرد آن در حوزههای مختلف بیشتر آشنا می شویم.
اجزای اصلی و مهم در SPS
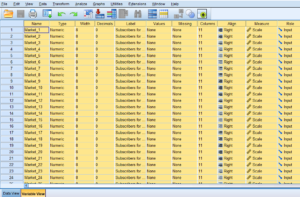
هنگام ورود به صفحه اصلی SPSS با صفحه گسترده Data Editor مواجه میشوید که در بالا و پایین این دو نوار وجود دارد؛ نوار بالای صفحه ابزارهای مختلف برای انجام دستورهای مختلف بر طبق نیاز است
و نوار پایین با داشتن دو گزینه Variable View و Data View محل ویرایش و وارد کردن اطلاعات است پرسشنامه در SPSS است.
نوار ابزار که در بالای صفحه قرار دارد، دارای 10 منوی اصلی برای تحلیل پرسشنامه است؛
این منوها عبارتند از: منوی فایل، منوی ویرایش، منوی نمایش، منوی دادهها، منوی تبدیل و انتقال، منوی آنالیز، منوی نمودارها و گرافها، منوی امکانات، منوی ویندو و منوی کمک میباشد هر کدام از این منوها بر حسب نیاز کاربردهای مخصوص خودشان را دارند که در ادامه به آنها اشاره خواهیم کرد.
آشنایی با منو نرم افزار spss
هنگام شروع کار با نرمافزار spss با دو بار کلیک بر روی برنامه آن را باز کنید. در بالای صفحه یک نوار ابزار دیده میشود که به عنوان منوی این نرم افزار معرفی میشود. این منو شامل چند بخش است که در ادامه معرفی شدهاند:
– منوی File
این منو خود شامل چند گزینه میشود. گزینه اول مربوط به بخشی است که شما میتوانيد به پرونده های از قبل ساخته شده دسترسی داشته باشید.
این گزینه همان Open است. گزینه New نیز به شما در ایجاد یک فایل و پرونده جدید جهت آنالیز و تحلیل کمک میکند. گزینه های save و save as هم برای ذخیره فایلها به شما کمک میکنند.
با استفاده از گزینه save as میتوانید نوع خروجی خود را تعیین کنید. گزینه دیگر در این منو گزینه print است که با آن میتوانيد خروجی کار خود را چاپ کنید. علاوه بر اینها گزینه Exit نیز جهت خروج از نرم افزار قرار داده شده است.
– منوی Edit
در منوی Edit برای پاک کردن نوشتهها گزینه clear را انتخاب کنید. حذف پروندهها نیز با کمک گزینه Delete ممکن شده است.
در این منو گزینههای دیگری نیز قرار داده شدهاند که برای کپی کردن و الصاق سند در محلی دیگر به کار میروند. این گزینهها Copy، Cut و Paste در منوی Edit نرم افزار spss هستند.
– منوی View
در ادامه spss چیست، باید گزینههای مختلف این منو را بررسی کنید. از طریق گزینههای آن نمایش حالتهای پنجره های نرم افزار را انتخاب میکنید.
همچنین اگر بخواهید قسمتی از نرم افزار مانند tollbar برای شما نشان داده شود یا مخفی شود، کافی است تیک کنار هر گزینه را فعال کنید.
– منوی Data
در این منو میتوانید با کمک از گزینهها متغیرها را شخصی سازی کنید. برای مثال با استفاده از گزینه Define variable properties میتوان ویژگیهای متغیرها را تعریف کرد.
بهعلاوه با کمک گزینه Sort است که متغیر های تعریف شده، متناسب با الگوریتم های خود مرتب سازی میشوند. برای ترکیب فايل های متنوع ساخته شده در spss ، گزینه Merge Files را انتخاب کنید.
همچنین انتخاب گزینه Weigth cases باعث وزن دادن به مورد یا کیس ها میشود.
– منوی Transform
با کمک منوی Transform است که میتوان متغیر جدید تعریف شده را با استفاده از متغیر های قدیمی و توابع ریاضی محاسبه کرد.
در این منو برای محاسبه متغیر جدید با استفاده از توابع ریاضی باید گزینه Compute انتخاب شود. با استفاده از گزینه Recode کار کد گذاری دوباره داده را انجام دهید.
بهعلاوه برای جایگزین کردن مقادیر جدید به جای مقادیر داده هایی که گم شده اند از گزینه Replace Missing Values استفاده کنید.
– منوی Analyze
منوی Analyze دیگر مبحث spss چیست، میباشد. این منو در واقع قلب نرم افزار به حساب میآید که کار اصلی در این نرم افزار را برعهده دارد.
با کمک از آزمونهای آماری و ریاضی طراحی شده در این منو است که فرضیه های مطرح شده در حین بررسی رد و یا تثبیت میشوند.
– منوی Direct Marketing
کسانی که بخش بازاریابی و بیزینس فعالیت دارند به یادگیری این بخش از منو احتیاج پیدا میکنند. زیرا در پیشرفت به آنها کمک خواهد کرد.
– منوی Graphs
تحلیل هایی که به نمودار احتیاج دارند و یا زمانی که به ویرایش نمودارهای خود نیاز است، منوی Graphs به کمک شما میآید. در این قسمت با گزینه Compare Subgroups میتوان گروه های ساخته شده در این برنامه را با هم مقایسه و مورد بررسی قرار داد.
– منوی Utilities
هر آنچه را که مربوط به استخراج متغیرهاست و از آن ها برای پیشبرد کار استفاده میکنید، در این منو طراحی شدهاند.
چگونه اطلاعات پرسشنامهها را در SPSS وارد کنیم؟
برای وارد کردن اطلاعات پرسشنامهها در نرم افزار SPSS هر یک از پرسش نامهها به عنوان یک نمونه و اطلاعات داخل آن متغیرهایی هستند که هر کدام دارای ماهیتهای متفاوتی است، بعد از باز کردن نرم افزار SPSS با صفحه گستردهای رو به رو میشویم که برای وارد کردن اطلاعات پرسشنامه باید از نوار پایین صفحه قسمت Variable View را انتخاب کرده و شروع به وارد کردن متغیرها شده و با توجه به هدف خواسته شده ماهیت متغیرها را تعیین کنیم.
بعد از وارد کردن متغیرها و اطلاعاتشان، از نوار پایین صفحه گزینه Data View را انتخاب میکنیم، در این صفحه تمام متغیرهای وارد شده در نرم افزار SPSS نشان داده میشود به این صورت که هر ستون از آن مربوط به یک متغیر بوده و هر سطر بیانگر پاسخ شرکت کنندگان در پرسشنامه است؛ باید متذکر شویم که هرگونه اشتباه در وارد کردن اطلاعات در صفحه Variable View باعث میشود در ادامه فرآیند در صفحه Data View هم با مشکل مواجه شوید.
چگونه فایلها را در نرم افزار SPSS مرتب کنیم؟
یک فایل را که حاوی داده است میتوان برحسب نوع متغیرهای آن مرتب کرد؛ برای این کار باید از منو Data گزینه Sort انتخاب شود، پس از انتخاب این دستور در پنجره باز شده از فهرست متغیرهای موجود که در سمت چپ جعبه قرار دارد میتوان متغیر یا متغیرهایی را برای مرتب کردن انتخاب کرد؛ در این حالت متغیرهای موجود در فایل بر اساس متغیر یا متغیرهای انتخاب شده مرتب میشوند. این مرتب کردن میتواند به صورت افزایشی (Ascending) یا کاهشی (Descending) باشد.
متغیرها در نرم افزار آماری SPSS چگونه باید نامگذاری شوند؟
نکاتی باید در نامگذاری متغیرها در نرم افزار SPSS مورد توجه قرار بگیرد، بطور مثال: حتما نام متغیرها باید با حروف شروع شود چون در غیر این صورت برای نرم افزار شناخته شده نخواهد بود، حداکثر نام انتخابی برای هر متغیر باید 64 کاراکتر باشد، هرگز از فاصله در نوشتن نام استفاده نکنید.
میتوانید برای نامگذاری از ترکیب حروف و عدد هم استفاده کنید، در انتهای نامگذاری استفاده از (.) و (_) غیر مجاز است در صورتی که در برچسب میتوانید استفاده کنید، اسامی غیر مجاز مانند All, And, Bye را در نامگذاری به کار نبرید همچنین به یاد داشته باشید که در نامگذاری متغیر حتما از لاتین و در برچسب گذاری از فارسی استفاده کنید.
ادغام متغیرها در SPSS
Add Variable یا ادغام متغیرها در نرم افزار آماری SPSS برای یکی کردن دو فایل در کنار یا زیر یکدیگر انجام میشود که این کار اغلب برای مقایسه کردن دو فایل استفاده میشود؛ نکته ی مهم این جا است که برای ادغام کردن متغیرها باید ماهیت آن ها از یک نوع باشد همچنین نام متغیرها هم نباید یکی باشد، برای این کار باید از نوار بالای صفحه نرم افزار SPSS گزینهی Data را انتخاب کنید سپس از پنجره باز شده بخش Merge File را کلیک کنید.
توجه داشته باشد در ادامه دو گزینه پیش رو دارید که یکی برای ادغام کردن فایلها یا به نوعی نمونه است و دیگری برای ادغام کردن متغیرها استفاده میشود. برای ادامه ی این روند میبایست فایل یا متغیر مورد نظر خود از محل ذخیرهسازی آن انتخاب کنید. فرایند ادغام متغیرها معمولا در مواقعی که محقق با حجم بالایی از داده رو به رو است و تعداد محققین در روند کار زیاد است از دستهبندی و ادغام متغیرها برای تجزیه و تحلیل بهتر استفاده میکنند.
برای انجام تحلیلهای آماری با استفاده از نرم افزار آماری SPSS می توان به جدولهای فراوانی، نمودارهای آماری و مقایسهای و مقایسه شاخصها دست پیدا کرد؛ بدست آوردن قابلیت اطمینان پرسشنامهها، آزمونهای پارامتری مرتبط به میانگین جامعه، سنجش همبستگی بین متغیرها رگرسیون، اکتشاف و خوشه بندی از جمله فرآیندیهایی است که در تحلیل آماری پایان نامه با استفاده از نرم افزار SPSS انجام میشود.
برای انجام هرکدام از آنها با وارد کردن دادههای مورد نظر و انتخاب گزینههای صحیح صورت میگیرد؛ بطور مثال برای تحلیل عاملی اکتشاف با انتخاب Analyze از نوار بالای صفحه نرم افزار در پنجره باز شده گزینهی Descriptive Statistics و سپس Explore را انتخاب میکنیم، این فرآیند برای دادههای کمی که از طرحهای مستقل جمع آوری شدهاند کاربرد دارد.
همچنین این دستور امکان توصیف دادهها به تفکیک گروههای مختلف را فراهم میکند. خلاصه این تحلیلها با استفاده از ابزاری مانند Plot ها و میانگین و فاصلههای تعیین شده بدست میآیند که در نهایت خروجی تحلیل آماری از پرسشنامه را در قالب جدول فراوانی و Plot نمایش میدهد.
چگونه در SPSS خروجی بگیریم؟
بعد از اینکه دستور مورد نظر در SPSS انجام شد، نتایج حاصل در پنجره ای به نام Output view نشان داده میشود؛ این نمایش شامل نتایج و تحلیل تمام دستورات خواسته شده از SPSS است که به صورت جدولهای فراوانی و انواع نمودارها مشخص میشود، در صورت نیاز میتوان از طریق منوی File گزینه Print را برای چاپ فیزیکی نتایج استفاده کرد.
گاهی اوقات برای استفاده از نتایج تحلیلها در نرم افزار آماری SPSS می توان برای تفسیر این خروجیها آنها را نرم افزارهای دیگر مثل Word یا Excel انتقال داد؛ یکی از ساده ترین روشها برای انتقال خروجی در SPSS به Word و Excel استفاده از دستور کپی وPaste است به این صورت که با انتخاب خروجی مورد نظر در پنجره Output و استفاده از کلیک راست یا دکمه Edit دستور Copy Special را انتخاب میکنید.
سپس در برنامه Word یا Excel عملیات Paste را انجام داده یا با استفاده از کلیدهای ترکیبی ctrl+v خروجی در SPSS در محل مورد نظر پیاده میکنید. میتوانید از اطلاعات بدست آمده در خروجی SPSS فایلهای اطلاعاتی بدست آورید که این قابلیت میتواند ورودی برای تحلیلهای بعدی مورد استفاده قرار بگیرد؛ در آینده بیشتر به این موضوع میپردازیم.
می توان گفت امروزه تمام پروژه ها، پایان نامهها و تحقیقها با آمار و ارقام سر و کار دارند به همین دلیل نرم افزار SPSS هم یکی از انتخابهای کارشناسان برای انجام پروژههای آماری خود در حوزههای مختلف است؛ بسیاری از سایتها و افراد هستند که انجام پروژههای آماری در نرم افزار SPSS را برعهده میگیرند اما در این بین باید دقت کرد که چه کسی را برای این کار در نظر میگیرید چرا که با توجه به رشته و گرایش و حوزه کاری استفاده از نرم افزار SPSS هم کاربرد متفاوتی را ارائه میدهد.
نرم افزار SPSS و R
در تجزیه و تحلیلهای آماری نرم افزار SPSS و R استفاده گسترده ای را در اختیار کاربران قرار میدهد؛ البته یادگیری نرم افزار SPSS آسانتر از نرم افزار R است اما خروجی گرفتن در هر دو نرم افزار براحتی انجام میشود، هر چند که هر کدام در حوزهی آماری کاربردهای زیادی دارند اما نرم افزار SPSS را بیشتر به یک نرم افزار آماری و R به عنوان نرم افزاری ایدهآل در حوزه علم داده و برنامه نویسی شهرت دارد.
بهترین نسخه نرم افزار spss کدام است؟
شرکت سازنده spss هر سال و یا هر دو سال یک بار نسخه جدیدی از این نرم افزار را انتشار میکند. نکته مشترک در بین تمام ورژن های این نرم افزار این است که نسخه ها قابلیت جدیدی پیدا کرده و سنگین تر میشوند. تمام نسخه های اصلی spss یک کار اصلی را انجام میدهند و با چند تفاوت جزئی به روز رسانی میشوند.
یادگیری نرم افزار آماری SPSS
اگر بدنبال آموزش و یادگیری نرم افزار SPSS هستید بسیاری از دورهها، ویدیوها و کتابهای آموزشی هستند که میتوانند شما را در فرآیند یادگیری نرم افزار SPSS کمک کنند، اگر به دنبال ویدیوهای آموزشی هستید، سایت مکتب خونه دورههای آموزشی را ارائه داده که میتوانید از آنها استفاده کنید؛ اما اگر بدنبال کتابهای آموزشی هستید کتاب آموزش SPSS نوشته منصور مومنی، مقدمهای بر آمار SPSS در روانشناسی نوشته Dennis Howitt و Duncan Cramer، آموزش جامع SPSS نوشته رضا بهرامی و چندین کتاب دیگر میتوانند کمک کننده شما در این مسیر باشند.
کلام پایانی
دنیای یادگیری نرم افزارها به علت پیشرفت روز به روز تکنولوژی، دنیای وسیع و بیانتهایی است، برای قدم گذاشتن در این دنیا قبل از هر چیزی به دانشی به روز نیاز دارید تا ادامه راه هموارتر شده و به پیشرفت برسید چرا که شروع هرکاری بدون دانش ابتدایی مثل درخت بی ریشه است.
مطالب گفته شده تنها بخشی از نرم افزار SPSS است تا صرفا شما را به یک دید جامع و کلی از این نرم افزار برساند و با کاربردها و جایگاه آن در دنیای نرم افزارها به خصوص نرم افزارهای آماری آشنا کند؛ نرم افزار SPSS رقبای زیادی در حوزه تحلیلهای آماری و داده کاوی دارد مثل:R،Minitab و SAS؛ اما بسته به اینکه هدف چه خواهد بود استفاده نیز متفاوت خواهد شد.
اما نرم افزار SPSS به علت یادگیری آسان و سهولت در کاربرد مورد توجه بسیاری از کاربران قرار می گیرد؛ همانطور که گفته شد این نرم افزار در روش تحقیق، پایان نامه ها و انواع پژوهشهای آماری در رشتههای علوم اجتماعی و روانشناسی، کشاورزی و صنایع مورد استقبال ویژهای قرار میگیرد.
در آخر باید گفت با توجه به وسیع بودن امکانات نرم افزارSPSS و یادگیری آسان آن میشود این نرم افزار را جایگزین دیگر نرم افزارها در امور تحلیل آماری کرد البته اگر فرصت کافی برای یادگیری را نداشته و میخواهید هر چه سریعتر دست به کار شوید.
ما در این سایت پرسشنامه های استاندارد (دارای روایی، پایایی، روش دقیق نمره گذاری ، منبع داخل و پایان متن ) ارائه می کنیم و همچنین تحلیل آماری کمی و کیفی رابا قیمت بسیار مناسب و کیفیت عالی و تجربه بیش از 17 سال انجام می دهیم. برای تماس به ما به شماره 09143444846 در شبکه های اجتماعی پیام بفرستید. ایمیلabazizi1392@gmail.com
تمامی حقوق مادی و معنوی این سایت متعلق به لنسرسرا و محفوظ است.
این سایت دارای مجوز می باشد
Statcounter




 با تجربهی بیش از 17 سال و ارائهی بهترین خدمات
با تجربهی بیش از 17 سال و ارائهی بهترین خدمات



 تماس: 09143444846 (پیامک، ایتا، واتساپ، تلگرام)
تماس: 09143444846 (پیامک، ایتا، واتساپ، تلگرام)  کانال تلگرام:
کانال تلگرام: 



 با ما در ارتباط باشید:
با ما در ارتباط باشید: