- تحلیل محتوای کیفی چیست؟

تحلیل محتوای کیفی فرآیندی است برای جمع آوری، ساختاردهی و تفسیر داده های کیفی برای درک آنچه نشان دهنده آن است. داده های کیفی غیر عددی و بدون ساختار هستند. داده های کیفی عموماً به متن اشاره دارد، مانند پاسخ های باز به سؤالات نظرسنجی یا مصاحبه های کاربر، اما گاهی شامل صوت، عکس و ویدیو نیز می شود. داده های کیفی به طور کلی به داده های متنی کلمه به کلمه از منابعی مانند مصاحبه ها، بحث های گروهی، بررسی ها، شکایات، پیام های چت، تعاملات مرکز پشتیبانی، مصاحبه با مشتری، یادداشت های موردی یا نظرات رسانه های اجتماعی اشاره دارد. در مقایسه با داده های کمی که اطلاعات ساختاریافته را جمع آوری می کنند، داده های کیفی معمولا ساختاری ندارند و عمق و وسعت بیشتری دارند و می تواند به سوالات ما پاسخ دهند و به فرموله کردن فرضیه ها و ایجاد درک بیشتر ما از پدیده ها کمک کند.
روش تحلیل محتوای کیفی چیست؟
تحلیل محتوای کیفی دارای پنج مرحله اساسی است که عبارتند از : 1. جمع آوری داده های کیفی، 2. سازماندهی و اتصال به داده های کیفی، 3. کدگذاری داده های کیفی، 4. تجزیه و تحلیل داده های کیفی برای بینش، 5. گزارش در مورد بینش های به دست آمده از تحلیل داده ها.

مرحله اول، داده های کیفی را جمع آوری کنید.
تحلیل محتوای کیفی با جمع آوری داده کیفی آغاز می شود .اولین گام تحقیق کیفی، جمع آوری داده هاست. به زبان ساده، جمع آوری داده ها، جمع آوری تمام داده های شما برای تجزیه و تحلیل است. یک موقعیت رایج زمانی است که داده های کیفی در منابع مختلف پخش می شوند.
مرحله دوم، داده های کیفی را سازماندهی و منسجم کنید.
اکنون شما همه این داده های کیفی را دارید، اما یک مشکل وجود دارد، داده ها بدون ساختار هستند. قبل از اینکه بتوان بازخورد را تجزیه و تحلیل کرد و ارزشی به آن اختصاص داد، باید در یک مکان واحد سازماندهی شود. چرا این مهم است؟ داشتن ثبات! اگر همه داده ها به راحتی در یک مکان قابل دسترسی باشند و به روشی ثابت تجزیه و تحلیل شوند، زمان ساده تری برای جمع بندی و تصمیم گیری بر اساس این داده ها خواهید داشت. رویکرد دستی برای سازماندهی داده های شما: روش کلاسیک ساختار دادن به داده های کیفی این است که تمام داده هایی را که جمع آوری کرده اید در یک صفحه گسترده (spreadsheet) رسم کنید.

کدگذاری در تحلیل محتوای کیفی
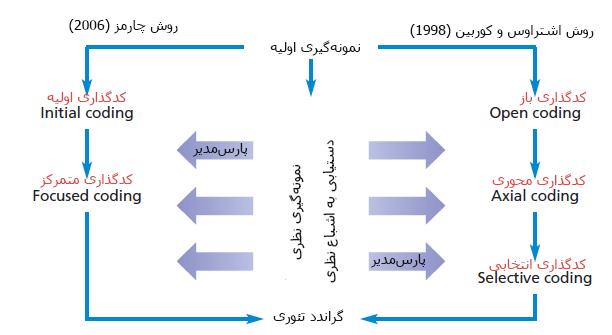
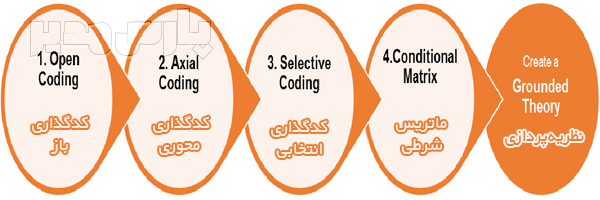
سومین مرحله تحلیل محتوای کیفی، کدگذاری داده کیفی است که یکی از مهمترین مراحل تحلیل است. کدگذاری در تحلیل محتوای کیفی فرآیند برچسب گذاری و سازماندهی داده های شماست به گونه ای که بتوانید مضامین موجود در داده ها و روابط بین این مضامین را شناسایی کنید. برای ساده سازی فرآیند کدگذاری، نمونه های کوچکی از داده های کیفی را می گیرید، مجموعه ای از کدها یا دسته بندی ها را ارائه می کنید و هر بخش از بازخورد را به طور سیستماتیک برای الگوها و معنا برچسب گذاری می کنید. سپس نمونه بزرگتری از داده ها را می گیرید، کدها را برای دقت و سازگاری بیشتر اصلاح و اصلاح می کنید. کد کردن به معنای شناسایی کلمات یا عبارات کلیدی و اختصاص دادن آنها به دسته ای از معنا است. بعنوان مثال در کدگذاری در تحلیل محتوای کیفی، “من واقعا از خدمات مشتری این شرکت نرم افزاری متنفرم” به عنوان “خدمات ضعیف به مشتریان” کدگذاری می شود.
کدگذاری در تحلیل محتوای کیفی به روش دستی
1.ابتدا کدگذاری در تحلیل محتوای کیفی باید تصمیم بگیرید که آیا از کدگذاری قیاسی یا استقرایی استفاده خواهید کرد. کدگذاری قیاسی زمانی است که فهرستی از کدهای از پیش تعریف شده ایجاد می کنید و سپس آنها را به داده های کیفی اختصاص می دهید. کدگذاری استقرایی برعکس این است، شما کدهایی را بر اساس خود داده ها ایجاد می کنید. کدها مستقیماً از داده ها به وجود می آیند و در حین حرکت آنها را برچسب گذاری می کنید. شما باید مزایا و معایب هر روش کدگذاری را بسنجید و مناسب ترین روش را انتخاب کنید.
2. داده های بازخورد را بخوانید تا درک گسترده ای از آنچه نشان می دهد به دست آورید. اکنون زمان آن رسیده است که اولین مجموعه کدهای خود را به عبارات و بخش های متن اختصاص دهید.
3. مرحله 2 را تکرار کنید، کدهای جدید اضافه کنید و توضیحات کد را هر چند وقت یکبار که لازم است بازبینی کنید. پس از کدگذاری همه چیز، دوباره همه چیز را مرور کنید تا مطمئن شوید که هیچ تناقضی وجود ندارد و هیچ چیز نادیده گرفته نشده است.
4.در کدگذاری در تحلیل محتوای کیفی یک چارچوب کد برای گروه بندی کدهای خود ایجاد کنید. چارچوب کدگذاری ساختار سازمانی همه کدهای شماست. و دو نوع قاب کدگذاری متداول وجود دارد، مسطح یا سلسله مراتبی. یک چارچوب کد سلسله مراتبی، به دست آوردن بینش از تجزیه و تحلیل خود را برای شما آسان تر می کند.
5. بر اساس تعداد دفعاتی که یک کد خاص رخ می دهد، اکنون می توانید موضوعات رایج را در داده های بازخورد خود مشاهده کنید. این بصیرت است! اگر «خدمات بد به مشتری» یک کد رایج است، وقت آن است که اقدام کنید.
تحلیل محتوای کیفی با استفاده از نرم افزار و به کمک کامپیوتر (CAQDAS)
به طور سنتی در رویکرد تحلیل دستی (اما نه همیشه)، داده های کیفی برای کدگذاری به نرم افزار CAQDAS وارد می شوند. در اوایل دهه 2000، نرم افزار CAQDAS توسط توسعه دهندگانی مانند ATLAS.ti، NVivo و MAXQDA رایج شد و مشتاقانه توسط محققان برای کمک به سازماندهی و کدگذاری داده ها استفاده شد.

مزایای استفاده از نرم افزار تحلیل داده های کیفی به کمک کامپیوتر:
• به سازماندهی داده های شما کمک می کند
• به شما این امکان را میدهد که به کاوش تفاسیر مختلف از تجزیه و تحلیل داده های خود بپردازید
• به شما امکان می دهد داده های خود را آسان تر به اشتراک بگذارید و امکان همکاری گروهی را فراهم می کند (تجزیه و تحلیل ثانویه را امکان پذیر می کند) با این حال، هنوز باید داده ها را کدگذاری کنید، موضوعات را کشف کنید و خودتان تحلیل را انجام دهید. بنابراین هنوز میتواند یک رویکرد دستی تلقی شود.
اگر می خواهید در خصوص نرم افزار Nvivo آموزش ببینید. اینجا کلیک کنید مجموع آموزش 8 ساعت و 24 دقیقه
مرحله چهارم، داده ها را برای تولید بینش های معنادار تجزیه و تحلیل کنید.
اکنون می خواهیم داده های خود را برای یافتن بینش تجزیه و تحلیل کنیم. اینجاست که ما شروع به پاسخ به سوالات تحقیق خود می کنیم. به خاطر داشته باشید که مرحله 4 و مرحله 5 دارای همپوشانی هستند. این به این دلیل است که ایجاد تجسم بخشی از تجزیه و تحلیل و گزارش است. وظیفه کشف بینش ها، جستجوی کدهایی است که از داده ها بیرون می آیند و همبستگی های معناداری را از آنها استخراج می کنند. همچنین در مورد اطمینان از متمایز بودن هر بینش و داشتن داده های کافی برای پشتیبانی از آن است.
بخشی از تجزیه و تحلیل، تعیین میزان ارتباط هر کد با مشخصات جمعیتی و مشخصات مشارکت کنندگان در تحقیق است و مشخص کردن اینکه آیا رابطه ای بین این نقاط داده وجود دارد یا خیر. برای بهبود کیفیت اطلاعات بینش، کدهای فرعی را به صورت دستی ایجاد کنید. اگر چارچوب کد شما فقط یک سطح داشته باشد، ممکن است متوجه شوید که کدهای شما بسیار گسترده هستند و قادر به استخراج بینش معنادار نیستند. اینجاست که ایجاد کدهای فرعی برای کدهای اصلی شما ارزشمند است.
مرحله پنجم، نتایج و داستان داده های خود را گزارش کنید.
آخرین مرحله از تجزیه و تحلیل داده های کیفی، گزارش دادن به آن، گفتن داستان است. در این مرحله، کدها به طور کامل توسعه یافته و تمرکز بر انتقال روایت به مخاطب است. یک طرح کلی منسجم از تحقیقات کیفی، یافته ها و بینش ها برای ذینفعان برای بحث و مناظره حیاتی است، قبل از اینکه بتوانند یک اقدام معنادار را طراحی کنند.

نمونه تحلیل محتوای کیفی
یکی از روش های بسیار خوب برای یادگیری تحلیل محتوای کیفی و نحوه گزارش کردن نتایج آن، خواندن مقالات منتشر شده با این رویکرد می باشد. گرچه تحلیل در مطالعات کیفی مختلف از نظر سطح انتزاع و دقت با یکدیگر متفاوت می باشد، ولی محققین با مطالعه انواع مختلف مقالات کیفی که منتشر شده است و مراحل داوری همتایان را پشت سر گذاشته اند، می توانند تا حدود زیادی الگو بگیرند و مسیر پژوهش خود را به راحتی دنبال کنند. در زیر سه نمونه از مقالات کیفی منتشر شده، جهت مطالعه آورده شده است که میتواند راهگشا باشد. مقاله اول به دنبال کشف موانع برنامه های سلامت جنسی از دیدگاه سیاست گذاران حوزه سلامت بوده که بر اساس پایان نامه دکترا با همین مضمون منتشر شده است. مقاله دوم با هدف کشف و واکاوی شرایط زمینه ساز تک فرزندی در زنان و مردان ساکن تهران که دارای یک فرزند بودند انجام شده است و منتج از یک طرح پژوهشی در تهران بوده و مقاله سوم با هدف واکاوی جامعه پذیری جنسی در ایران می باشد که بر اساس یک پایان نامه دکترا می باشد.
سه نمونه از مقالات تحلیل محتوای موضوعی را در زیر مطالعه کنید:
Perceived Barriers to Implementing Sexual Health Programs from the Viewpoint of Health Policymakers in Iran: A Qualitative Study
https://qualitativestudies.com/wp-content/uploads/2022/05/sexual-health-programs.pdf
واکاوی شرایط زمینه ساز قصد و رفتار تک فرزندی در تهران
https://qualitativestudies.com/wp-content/uploads/2022/05/only-child.pdf
درک زنان از جامعه پذیری جنسی در ایران: یک مطالعه کیفی
https://qualitativestudies.com/wp-content/uploads/2022/05/sexual-socialization.pdf
اگر می خواهید در خصوص نرم افزار Nvivo آموزش ببینید. اینجا کلیک کنید مجموع آموزش 8 ساعت و 24 دقیقه
برگرفته از آکادمی پژوهش کیفی – دکتر فریده فراهانی
نوشته
کمبود ویتامین E چه عوارضی دارد؟
نوشته
نوشته
ارزش ویژه برند (Brand Equity) چیست؟
نوشته
چرا بعد از کار اینقدر خسته میشوم؟ چه باید کرد؟
خدمات تخصصی پژوهش و تحلیل داده های آماری با مناسبترین قیمت و کیفیت برتر!
🌟با تجربهی بیش از 17 سال و ارائهی بهترین خدمات
مشاوره نگارش: تحلیل داده های آماری
ارائه و طراحی پرسشنامه های استاندارد
📊تحلیل داده های آماری با نرم افزارهای کمی و کیفی
-
🔍 نرم افزار های کمی SPSS- PLS – Amos
-
🔍نرم افزار های کیفی: Maxquda & Nvivo
-
📏تعیین حجم نمونه با:Spss samplepower
- همچنین برای نوشتن فصل سوم پایان نامه یا بخش روش تحقیق مقاله می توانید با ما در تماس باشید.
-
🔗 با ما در ارتباط باشید:
📞 تماس: 09143444846 (پیامک، ایتا، واتساپ، تلگرام)
🌐 کانال تلگرام: عضو شوید
🌐 وبلاگ
💼کیفیت بالا، قیمت مناسب و خدماتی که به نیازهای شما پاسخ میدهند!
💼با ما همراه باشید و پروژهی خود را به یک تجربهی موفق تبدیل کنید.