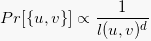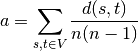...........................................................................................................................................................................................................................................................................................................................................................................
خوش آمدید این سایت دارای مجوز می باشد برای مشاهده مجوز ها پایین صفحه را مشاهده فرمائید.
نشریات و مجلات معتبر بین المللی (ISI) در حوزه ارتباطات
لیست مجلات معتبر ISI اختصاصی برای گرایش های مختلف حوزه ارتباطات
یکی از شایع ترین اشتباهاتی که بسیاری از دانشجویان و اساتید دانشگاهی در انتخاب مجلات و نشریات برای ارسال مقاله خود مرتکب می شوند این است که به نوع مجلات توجهی نمی کنند و یا اینکه آشنایی کافی با مجلات معتبر دنیا ندارند. با توجه به اینکه مجلات و نشریات منتشر شده در سراسر دنیا، در زمینه های علمی و اجتماعی هر ساله توسط پایگاه اطلاعاتی Web of Science مورد ارزیابی قرار گرفته و رتبه مجلات با عنوان گزارش استنادی مجلات یا Journal Citation report) JCR) توسط موسسه اطلاعاتی علمی تامسون نمایه می شود. با این حال بسیاری از دانشجویان در یافتن مجلاتی که منحصرا برای رشته آنها باشد، و اینکه جز لیست مجلات نامعتبر نبوده و ضریب تاثیر (IF) خوبی هم داشته باشد، دچار سردرگمی می شوند. بنابر این، برای سهولت دسترسی دانشجویان و اساتید، نشریات و مجلات معتبر ISI بر اساس رشته های تحصیلی مختلف، دسته بندی شده اند.
در این بخش لیست مجلات و نشریات ISI مربوط به رشته امور مالی تجارت برای استفاده اساتید و دانشجویانی که در این زمینه تحصیل می کنند، قرار داده شده است.
نشریات و مجلات معتبر بین المللی (ISI) در حوزه اخلاق
لیست مجلات معتبر ISI اختصاصی برای گرایش های مختلف حوزه اخلاق
یکی از شایع ترین اشتباهاتی که بسیاری از دانشجویان و اساتید دانشگاهی در انتخاب مجلات و نشریات برای ارسال مقاله خود مرتکب می شوند این است که به نوع مجلات توجهی نمی کنند و یا اینکه آشنایی کافی با مجلات معتبر دنیا ندارند. با توجه به اینکه مجلات و نشریات منتشر شده در سراسر دنیا، در زمینه های علمی و اجتماعی هر ساله توسط پایگاه اطلاعاتی Web of Science مورد ارزیابی قرار گرفته و رتبه مجلات با عنوان گزارش استنادی مجلات یا Journal Citation report) JCR) توسط موسسه اطلاعاتی علمی تامسون نمایه می شود. با این حال بسیاری از دانشجویان در یافتن مجلاتی که منحصرا برای رشته آنها باشد، و اینکه جز لیست مجلات نامعتبر نبوده و ضریب تاثیر (IF) خوبی هم داشته باشد، دچار سردرگمی می شوند. بنابر این، برای سهولت دسترسی دانشجویان و اساتید، نشریات و مجلات معتبر ISI بر اساس رشته های تحصیلی مختلف، دسته بندی شده اند.
در این بخش لیست مجلات و نشریات ISI مربوط به رشته اخلاق برای استفاده اساتید و دانشجویانی که در این زمینه تحصیل می کنند، قرار داده شده است.
تحلیل شبکه های اجتماعی (Social Network Analysis) — به زبان ساده و جامع
«شبکه اجتماعی» (Social Network)، ساختاری اجتماعی متشکل از بازیگران شبکه (برای مثال اشخاص یا سازمانها) و روابط میان آنها است. در واقع باید گفت شبکههای اجتماعی از «گرهها» (Nodes) و «یالها» (Edges) تشکیل شدهاند. از گرهها با عنوان راس نیز یاد میشود. شاید بتوان گفت قدمت شبکههای اجتماعی به شکلگیری اولین اجتماعات انسانی باز میگردد. پژوهشها در این حوزه نیز عمری طویل داشته و از سال ۱۸۲۰ با تلاشهای «دیوید امیل دورکیم» (David Émile Durkheim) و «فردیناند تونیس» (Ferdinand Tönnies) به طور جدی آغاز شدند.
جنس دیگری از شبکههای اجتماعی با ظهور وب ۲.۰ پا به عرصه وجود گذاشت که به آنها «شبکههای اجتماعی برخط» (Online Social Networks | OSN) گفته میشود. چنین شبکههای اجتماعی بر پایه وب بنا شدهاند و از جمله آنها میتوان به «آیدنتیکا» (identi.ca)، «توییتر» (Twitter)، «گوگل پلاس» (+Google)، «فیسبوک» (Facebook)، «لینکدین» (LinkedIn)، «یوتیوب» (Youtube)، «اینستاگرام» (Instagram) و «ساوندکلاود» (SoundCloud) اشاره کرد.
این شبکههای اجتماعی جهان واقعی با دادههای مربوط به انسانها – که معمولا توسط ایشان تولید میشوند – و اغلب در برگیرنده مشخصههای اجتماعی آنها هستند توسعه پیدا میکنند. تحلیل شبکههای اجتماعی (Social Network Analysis | SNA) فرآیند تحقیق و بررسی ساختارهای اجتماعی با استفاده از «نظریه شبکه» (Network Theory) و «نظریه گراف» (Graph Theory) است.
به عنوان مثالی از تحلیل شبکههای اجتماعی میتوان به بررسی الگوهای موجود در گراف شبکه اشاره کرد که براساس آن میتوان به دانشی پیرامون الگوهای رفتاری انسانها و در نتیجه اطلاعات ارزشمند قابل تحلیل و کاوش درباره نوع بشر دست پیدا کرد. نتایج حاصل از تحلیل شبکههای اجتماعی در برگیرنده ارزش و قدرتی است که توسط بسیاری از سازمانها و شرکتهای (کوچک، متوسط و بزرگ) دولتی و خصوصی برای بیشینهسازی بازده مورد استفاده قرار میگیرد.
اغلب انسانها از «رسانههای اجتماعی» (Social Media) به منظور یافتن شغل، بیان دیدگاهها، دوستیابی، در ارتباط بودن با دیگران، بازی کردن و بسیاری از اهداف دیگر استفاده میکنند. همچنین، دامنه کاربردهای سایتهای اجتماعی به این موارد محدود نشده و چنین شبکههایی در حال حاضر به شدت تصمیمگیریهای کسبوکارها برای بازاریابی و فروش، مدیریت زنجیره تامین و تبلیغات را با دانش تحلیل شبکه تحت تاثیر قرار دادهاند.
شبکههای اجتماعی برخط شبکههای تصادفی نیستند که گرهها (بازیگران) در آنها به طور تصادفی اضافه شوند، بلکه دارای ویژگیهای خاص و بعضا منحصر به فردی هستند. پرسشی که در این وهله مطرح میشود این است که این ویژگیها چه هستند؟ در ادامه به این ویژگیها و چگونگی تحلیل شبکههای اجتماعی برخط با استفاده از آنها پرداخته میشود.
اتصال
آیا گرافهای اجتماعی بزرگ مقیاس و جهان واقعی متصل (connected) هستند؟ بلی، حتی اگر این گرافها به طور کامل نیز متصل نباشند احتمال وجود مواردی که متصل نیستند بسیار کم است. برای درک بهتر مفهوم متصل بودن گراف شبکههای اجتماعی، شرایطی را میتوان در نظر گرفت که ۵۰ دانشآموز یک کلاس هر یک ۳ دوست دارند. احتمال آنکه گراف حاصل از نمونه بیان شده غیر متصل باشد چقدر است؟
راهکار: برای سادگی، فرض میشود که کلاس به دو گروه m و n تقسیم شده. (P(E) = 1/(m*n. این رویداد با P(E(m=25,n=25)) = 0.0016 بسیار غیر محتمل است.
این مثال از یک کلاس کوچک بود، تصور کنید که این محاسبات برای یک شبکه بسیار بزرگ انجام شود. اگر به ریاضیات نهفته در پس این گرافها نگاه شود امکان دارد غیر متصل باشند، اما وقوع چنین مسالهای برای شبکههای جهان واقعی بسیار غیر محتمل است. ویژگی «اتصال» (Connectedness) را میتوان با توجه به مساله مطرح شده در ادامه تحلیل کرد. n گره (از یک گراف) داده شده است، حداقل تعداد یالهایی که باید به گراف کاملا غیر متصل اضافه شوند تا گراف ذاتا متصل شود چندتا است؟
پرسش دیگر آن است که آیا زمانی که یک گراف هیچ راس (vertex) ایزولهای ندارد، یالهای موجود به طور یکنواخت و تصادفی قرار گرفتهاند؟ اگر مساله مطرح شده با «تحلیل احتمالات» (Probabilistic Analysis) حل شود، نتیجه به شرح زیر است: اگر (n*log(n یال قرار داده شود، احتمال آنکه این گراف غیر متصل باشد (1/n)2(1/�)2 است. مقدار n در شبکههای جهان واقعی بسیار بزرگ و در نتیجه وقوع غیر متصل بودن غیرمحتمل است. اما مفهوم واقعی ویژگی اتصال (Connectedness) چیست؟
مفهوم ویژگی اتصال
بسیاری از افراد این روزها نام «کمبریج آنالیتیکا» (Cambridge Analytica) را شنیدهاند. در مارس ۲۰۱۸، «نیویورک تایمز» (The New York Times) و «آبزرور» (The Observer) گزارشی مبنی بر اینکه شرکت سهامی خاص کمبریج آنالیتیکا بدون کسب اجازه از اطلاعات شخصی افرادی که با اهداف آکادمیک گردآوری شده بود در کمپینهای سیاسی استفاده کرده ارائه دادند.
اما کمبریج آنالیتیکا واقعا چه کرده بود؟ جریان از این قرار بود که «الکساندر کوگان» (Aleksandr Kogan)، از اساتید روانشناسی «دانشگاه کمبریج» (University of Cambridge) به منظور انجام یک پژوهش آکادمیک در سال ۲۰۱۴، یک برنامه تست شخصیت در فیسبوک طراحی میکند و بالغ بر ۲۷۰ هزار کاربر آمریکایی فیسبوک به صورت داوطلبانه از آن استفاده میکنند.
کوگان با بهرهگیری از این دادهها و ویژگیهای مربوط به تحلیل شبکههای اجتماعی موفق به گردآوری دادههای مربوط به دوستان افراد شرکتکننده در تست نظرسنجی نیز میشود و بدین شکل حجم زیادی از دادهها پیرامون جمعیت بالایی از کاربران فراهم میشود. کوگان در نهایت این دادهها را به شرکت کمبریج آنالیتیکا میفروشد و آنها از این دادهها در کمپینهای تبلیغاتی سیاسی انتخابات سال ۲۰۱۶ آمریکا بهره بردند. اما کوگان و کمبریج آنالیتیکا چگونه توانستند از دادههای شرکتکنندگان در نظرسنجی به دادههای دوستان آنها دست یابند؟https://beta.kaprila.com/a//templates_ver2/templates.php?ref=blog.faradars&id=string-1&t=string&w=760&h=140&cid=2994503,2994001,2993970&wr=special,smart,brother&pid=54
با توجه به فرض مطرح شده که شبکه دوستی ایالات متحده آمریکا در فیسبوک متصل است، با بهرهگیری از یک «حفره» (loophole) در «رابط کاربردی برنامهنویسی» (Application Programming Interface) آنها توانسته بودند به اطلاعات خام ۸۷ میلیون نفر با تحلیل اطلاعات دوستانشان که در آزمون کوگان شرکت کرده بودند دست پیدا کنند.
صرفا برای اینکه مقیاس تاثیر این جریان شفاف شود، باید گفت در این آزمون ۲۷۰۰۰۰ کاربر شرکت کرده بودند که موجب شد کمبریج آنالیتیکا بتواند به ۳۲۲ برابر اطلاعات افراد دست پیدا کند. ویژگی که منجر به دستیابی به اطلاعات دوستانِ دوستان و زنجیره انسانی موجود در شبکههای اجتماعی شد. این یعنی آنالیتیکا توانسته بود به اطلاعات ۲۷٪ از جمعیت آمریکا تنها با یک آزمون ساده دست پیدا کند. اکنون میتوان دادههایی که غولهای فناوری در اختیار دارند و قدرتی که با تحلیل دادههای شبکههای اجتماعی به دست میآورند را متصور شد.
در ادامه نگاهی اجمالی به این بحث و تحلیلهای مربوط به آن انداخته خواهد شد. این دادهها به چه شکل یا فرمی وجود دارند؟ همانطور که پیشتر بیان شد، دادههای شبکههای اجتماعی به صورت گرافهایی با گرهها و یالها ذخیره و مصورسازی میشوند و هر یک از آنها ویژگیهای خاصی را از خود بروز میدهد. اکنون، اشکال گوناگونی که این دادهها ارائه میشوند مورد بررسی قرار خواهد گرفت.
مجموعه دادههای گراف
در ادامه فرمتهای گوناگونی که مجموعه دادههای شبکههای اجتماعی برای تحلیل موجود هستند مورد بررسی قرار میگیرد.
فرمت CSV: دادهها به صورت «فهرست یال» (Edgelist) یا «فهرست همسایگی» (Adjacency List) ارائه میشوند. فرمت Edgelist شامل دو/سه مقدار در هر خط است ([To, From, [Weight). گرهها اطلاعاتی پیرامون یالهایی که در گراف وجود دارند با هر وزنی که به آنها داده شده به دست میدهند. در این فرمت، اولین مقدار در یک سطر گره منبع و در ادامه گرههایی هستند که یالها به آنها متصل میشوند، برای مثال [… ,Source, Node1, Node2].
فرمت GML: یکی از متداولترین فرمتهایی است که انعطافپذیری بالایی برای ذخیرهسازی اطلاعات دارد. GML یک زبان مدلسازی برای ذخیرهسازی اطلاعات پیرامون گرهها، یالها، برچسبها، خصیصهها (ویژگیها) و دیگر موارد است.
مثالی از GML با ویژگیهای گراف، ویژگیهای گره و برچسبهای یالها.
فرمت Pajek Net: این فرمت از افزونه NET. استفاده میکند. دو ستون در این فرمت ارائه شدهاند، یکی راسها که برچسب گرهها را تعیین میکند و دیگری یالهای بین گرهها را نشان میدهد. اگر گرهها هیچ برچسبی نداشتند، ورودیهای سطرها زیر ستون راسها قابل چشمپوشی است. همچنین، مقدار یک خصیصه در صورت نیاز قابل اضافه شدن است.
زیر ستون vertices برچسب ویژگیها و زیر ستون arcs یالهای میان راسها مشخص شده است.
۴. فرمت GraphML: از ساختار تگ XML برای ذخیرهسازی اطلاعات پیرامون گرافها استفاده میکند و پسوند آن graphml. است. در اینجا، تگ graphml «فراداده»هایی (metadata) پیرامون گراف، تگ graph ویژگیهایی در رابطه با گراف، تگ nodes همه مشخصات مربوط به گرهها و در نهایت تگ edge مشخصههای یالها را تعیین میکند. همچنین، یک تگ کلیدی اختیاری نیز وجود دارد که میتوان از آن برای تخصیص وزن به یالها و ویژگی به گرهها استفاده کرد.
فرمت Graph XML با تگ کلیدی برای فراهم آوردن توصیفی پیرامون گرهها و یالها.
۵. فرمت GEXF :GEXF سرنامی برای عبارت «Graph Exchange XML» و توسعه داده شده توسط سازمان Gephi است. این فرمت شباهت زیادی به فرمت graphXML دارد. GEXF زبانی برای توصیف ساختارهای شبکه پیچیده، دادههای اختصاص یافته به آنها و دینامیکهای شبکه محسوب میشود. ابزار Gelphi همچنین برای بصریسازی آسان گرافهای شبکه مورد استفاده قرار میگیرد.
فرمت GEXF با فرادادهها، گرهها و ویژگیهای یالها و توصیفگرها.
مجموعه دادههای بالا را میتوان از مخازنی مانند SNAP ،(+) Konect ،(+) UCI (+) و دیگر وبسایتهایی که به ارائه مجموعه دادههای عمومی میپردازند دانلود کرد. برای تحلیل این مجموعه دادهها، استفاده از کتابخانههای محبوب پایتون شامل networkx و MatplotLib گزینه بسیار خوبی محسوب میشود. در ادامه، برای شروع یک مثال ارائه شده است.
# Draws circular plot of the network
import matplotlib.pyplot as plt
import networkx as nx
G = nx.karate_club_graph() # data can be read from above specified formats. Refer documentation
print("Node Degree")
for v in G:
print (v, G.degree(v))
nx.draw_circular(G, with_labels=True)
plt.show()
کپی
استفاده از کتابخانه NetworkX
مثالی را در نظر بگیرید که طی آن، در یک باشگاه کاراته معروف که با عنوان Zachary karate club شناخته شده، دو استاد دارای کشمکش هستند و سعی دارند اعضای گروه دیگری را جذب کنند. آشکار است که در پایان این جدال دو گروه باقی خواهند ماند. آیا میتوان با توجه به مشخصههای گراف پیشبینی کرد آن گروهها چه هستند و چه کسی سمت کدام استاد را گرفته است؟
نکته قابل توجه در این وهله آن است که یالهای میان جامعهای دارای «میانی» (betweenness) بالایی هستند. منظور از میانی تعداد کوتاهترین مسیرها بین دو گره است. اینها یالهایی هستند که گراف را متصل نگه داشته و در نقش پل عمل میکنند. کاری که میتوان انجام داد آن است که این یالها تا حد امنی حذف شوند و جوامع باقیمانده از جهت غیر متصل بودن در آن نقطه مورد بررسی قرار بگیرند.https://beta.kaprila.com/a//templates_ver2/templates.php?ref=blog.faradars&id=string-2&t=related&col=4&title=%D8%A2%D9%85%D9%88%D8%B2%D8%B4%E2%80%8C%D9%87%D8%A7%DB%8C%20%D9%BE%DB%8C%D8%B4%D9%86%D9%87%D8%A7%D8%AF%DB%8C&w=800&h=285&cid=2994503,2993973,2993986,2993996&wr=special,brother,brother,brother&pid=58
import networkx as nx # Python 2.x, NetworkX 2.0
import networkx as nx
def edge_to_remove(G): # high betweenness edges are removed first
dic1 = nx.edge_betweenness_centrality(G)
list_tuples = dic1.items()
list_tuples.sort(key =lambda x:x[1], reverse = True)
return list_tuples[0][0] #(a,b)
def girvan(G): # returns number of connected components
c = nx.connected_component_subgraphs(G)
i=0
while(i<11): # you can experiment with different values
G.remove_edge(*edge_to_remove(G))
return c
G = nx.karate_club_graph() # imports popular zachary karate club
c = girvan(G) # After enough edge removal, groups printed
for i in c:
print 'Group Nodes: ', i.nodes()
print 'Number Of Nodes: ', i.number_of_nodes()
Output :
Group Nodes: [0, 1, 3, 4, 5, 6, 7, 10, 11, 12, 13, 16, 17, 19, 21]
Number Of Nodes: 15
Group Nodes: [32, 33, 2, 8, 9, 14, 15, 18, 20, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31]
Number Of Nodes: 19
کپی
اکنون، ویژگی اتصال (connectedness) همراه با جزئیات بیشتر و اطلاعات جالبی که با اعمال ساختارهای اجتماعی بر آن قابل اشتقاق است مورد بررسی قرار میگیرد. از چه اطلاعات بیشتری میتوان پردهبرداری کرد؟ مثالی مفروض است که در آن شخصی اهل دهلی (Daman) قصد داشت در سال ۱۹۷۰ با یک سرویس پست یا ایمیل به Lana در لوس آنجلس متصل شود.
اکنون، منصفانه است که فرض شود همه جوامع در زمان خودشان متصل بودهاند، اما آیا گراف آشنایی جهان متصل است؟ برپایه استدلالی که در بالا اشاره شد، منصفانه است که گفته شود جهان متصل به حساب میآید. پرسش دیگر آن است که به منظور انتقال پیام به طور میانگین چند رابطه مورد نیاز است؟ پاسخگویی به این سوال با استفاده از نظریه «شش درجه جدایی» (Six Degrees of Separation) امکانپذیر خواهد بود.
شش درجه جدایی
در پاسخ به پرسش بالا باید گفت، به طور میانگین تنها شش رابطه برای انتقال چنین پیامی مورد نیاز محسوب میشود. اما چرا تعداد رابطهها انقدر کم است؟ پاسخ این پرسش «هموفیلی» (homophily) (گرههای مشابه متصل میشوند و جوامعی را با ضریب همبستگی بالا شکل میدهند) و «روابط ضعیف» (Weak Ties) است.
هر دو این موارد در مثال Zachary club که در بالا مطرح شد، با دو جامعه حاصل شده به دلیل هموفیلی دو گره مشابه که متصل میشوند و یالهای دارای میانی بالا و روابط ضعیفی که در آن دوستان یک فرد حتی ممکن است در گروه رقیب باشند تشریح شد.
در شبکههای جهان واقعی، این مساله با یک توصیف تصادفی قابل درک است که بر مبنای آن احتمال کمتری برای شکل دادن روابط طولانی در مقایسه با روابط کوتاه وجود دارد. دلیل این امر میتواند جغرافیایی باشد، مانند مساله بالا که منجر به داشتن همپوشانی همسایگی کمتری شده است.
احتمال تخریب dاُمین توان از ابعاد فضا
چگونه میتوان این مساله را در مجموعه داده یک شبکه تشخیص داد؟ تنها کافی است طول میانگین کوتاهترین مسیری که به ۶ نزدیکتر و یا به شدت در مقایسه با اندازه شبکه کوچک است تحلیل شود. این بدین معنا است که گراف/شبکه پدیده «جهان کوچک» (small world) را از خود نشان میدهد.
در این فرمول v یک مجموعه از گرهها در G است. (d(s,t کوتاهترین مسیر از s تا t و n تعداد گرهها در G است.
ابتدا گراف مورد نظر (هر گراف دلخواهی) در هر فرمتی که کاربر با آن راحت است باید از ورودی خوانده شود. سپس، تابع زیر قابل اعمال روی آن است.
# Networkx Examples
G =nx.karate_club_graph() # Can be applied on different graphs
print(nx.average_shortest_path_length(G))
G = nx.florentine_families_graph()
print(nx.average_shortest_path_length(G))
G = nx.davis_southern_women_graph()
print(nx.average_shortest_path_length(G))
کپی
اکنون زمان آن رسیده که این کد روی مجموعه دادههای جهان واقعی اعمال شود. در اینجا یک مجموعه داده فیسبوک که با SNAP ترکیب شده مورد استفاده قرار گرفته که شامل دادههایی از همه ego-netها در قالب edgelist است. در ادامه سعی بر آن است که بررسی موردی انجام شده توسط کمبریج آنالیتیکا شبیهسازی شود، چگونگی اتصال کاربران به یکدیگر مورد بررسی قرار بگیرد و در نهایت خروجی حاصل با استفاده از کتابخانه matplotlib بصریسازی شود.
G = nx.read_edgelist('Desktop/facebook_combined.txt')
print(nx.average_shortest_path_length(G)) # Takes 4 mins approx.
[Output]: 3.6925068497 # Confirms our statement above.
کپی
مساله مهم دیگری که در این وهله مطرح میشود آن است که تفسیر این نتایج چگونه انجام میشود؟ نتیجه حاصل یک گراف بسیار بزرگ با ویژگی میانگین کوتاهترین مسیر بسیار کوچک است. این یعنی روابط بین هر دو گرهای در زمان ثابت (O(k قابل محاسبه است. مساله عنوان شده با عنوان «جستوجوی غیر متمرکز» (Decentralized Search) نیز شناخته شده است.
نتیجهگیری
تحلیل شبکههای اجتماعی بزرگ جهان واقعی با توجه به ویژگیهای این شبکهها (و با بهرهگیری از قابلیتهای دادهکاوی) مزایای متعددی را به دنبال دارد و پژوهشگران با آگاهی از این ویژگیها و مزایا به این حوزه گرایش قابل توجهی پیدا کردهاند. علاوه بر اتصال، ویژگیهای مهم دیگری نیز برای اکتشاف در شبکههای اجتماعی وجود دارد که از آن جمله میتوان به Power Law، «اثر آبشاری» (Cascading Effect)، «پیشبینی لینک» (Link Prediction)، سازماندهی فضایی و اجتماعی، Pseudo coreها و شبکههای تکاملی اشاره کرد که هر یک نیازمند بحث تخصصی خود هستند. داشتن دانش پیرامون این مباحث به سادهسازی مسائل تحلیل شبکه و کاهش زمان و تلاش مورد نیاز برای تحلیل مجموعه دادههای بزرگ کمک قابل توجهی میکند.
یک «شبکه اجتماعی» (Social Network)، ساختار اجتماعی تشکیل شده از افراد (یا سازمانها) است. تحلیل شبکههای اجتماعی، رویکردی است که در آن شبکه را به صورت مجموعهای از «گرهها» (Nodes) و روابط میان آن ها در نظر میگیرند. گرهها، اشخاص و در واقع بازیگران درون شبکه هستند و روابط میان آنها به صورت اتصالاتی بین گرهها نمایش داده میشود. ساختار شبکههای اجتماعی که ساختارهایی مبتنی بر گراف است، معمولا بسیار پیچیدهاند. انواع گوناگونی از روابط مانند دوستی، همکاری، خویشاوندی، علاقمندی و مبادلات مالی ممکن است بین گرهها وجود داشته باشد. در واقع «تحلیل شبکههای اجتماعی» (Social Network Analysis | SNA) یک استراتژی برای بررسی ساختارهای اجتماعی با استفاده از نظریههای شبکه و گراف است.
پژوهشهای انجام شده در حوزه تحلیل شبکههای اجتماعی نشان میدهد که شبکهها میتوانند در سطوح مختلفی از جمله شبکههای اجتماعی خانوادگی، همکاری و دوستی شکل بگیرند. این شبکهها نقش بسیار مهم و حیاتی در مسائل جهان واقعی دارند. بورگاتی در تعریف چیستی تحلیل شبکههای اجتماعی میگوید: «تحلیل شبکههای اجتماعی نگاشت و سنجش روابط و جریانهای میان افراد، گروهها، سازمانها، رایانهها یا دیگر موجودیتها است». در تحلیل شبکههای اجتماعی، ساختارهای شبکه شده با اصطلاحات گرهها (بازیگران، افراد، راسها یا موارد درون شبکه) و «یالها» (Edges) (روابط یا تعاملها) که گرهها را به یکدیگر متصل میکنند مشخصهسازی میشوند.
برای مثالی از ساختارهای اجتماعی که توسط شبکههای اجتماعی ارائه میشوند میتوان از شبکههای دوستی، آشنایی، خویشاوندی و شبکه سرایت بیماریها نام برد. این شبکهها معمولا با استفاده از Sociogramها که در آنها، گرهها به عنوان نقاط و روابط به صورت خطوط بین گرهها هستند نمایش داده میشوند. تحلیل شبکههای اجتماعی به عنوان یک روش کلیدی در جامعهشناسی مدرن مطرح است و پژوهشگران متعددی در حوزههای مردمشناسی، زیستشناسی، مطالعات ارتباطات، اقتصاد، جغرافیا، تاریخ، علم اطلاعات، مطالعات سازمانی، علوم سیاسی، روانشناسی اجتماعی، مطالعات توسعه و زبانشناسی اجتماعی به آن پرداختهاند.
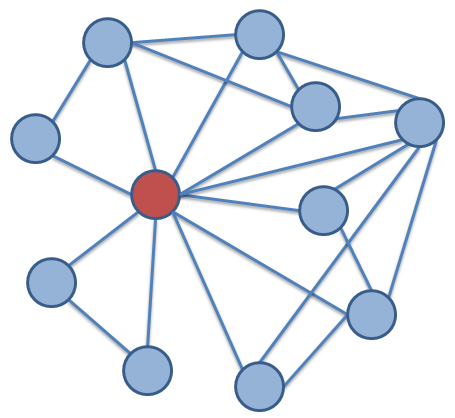
دو شکل اصلی از تحلیل شبکههای اجتماعی عبارتند از تحلیلهای شبکههای «اِگو» (Ego) و شبکه جهانی. در مطالعات اگو، شبکه یک فرد تحلیل میشود. شبکه اگو شامل یک گره کانونی با عنوان اگو، گرههایی که به طور مستقیم به این گره کانونی متصل شده و آلتر نامیده میشوند و گرههای بین آلترها است. لازم به ذکر است هر آلتر در یک شبکه اگو، خود دارای شبکه اگو است. در تحلیل شبکه جهانی سعی بر یافتن همه روابط بین مشارکتکنندگان در شبکه است. شکل زیر شبکه الگو گره قرمز رنگ را نشان میدهد.
تاریخچه تحلیل شبکههای اجتماعی
تحلیل شبکههای اجتماعی ریشههای نظری در کارهای جامعهشناسان اولیه مانند «گئورگ زیمل» (Georg Simmel) و «امیل دورکیم» (Émile Durkheim) که در رابطه با اهمیت مطالعه الگوهای روابطی که بازیگران اجتماعی را به یکدیگر متصل میکند آثار مکتوبی منتشر کردهاند دارد. دانشمندان اجتماعی مفهوم «شبکههای اجتماعی» را از اوایل قرن بیستم به منظور اشاره ضمنی به مجموعههای پیچیده از روابط بین اعضای سیستمهای اجتماعی در همه مقیاسها از بینشخصی گرفته تا بینالمللی استفاده کردند. در سال۱۹۳۰ میلادی، «جاکوب مورنو» (Jacob L. Moreno) و «هلن جنگینز» (Helen Jennings)، روشهای تحلیلی پایهای را برای شبکههای اجتماعی معرفی کردند.
در سال ۱۹۵۴، «جیای بارنز» (John Arundel Barnes)، از اصطلاحات گروههای محدود (مانند قبایل و خانوادهها) و دستههای اجتماعی (مانند جنسیت و قومیت) استفاده کرد. پژوهشگرانی مانند «رونالد برت» (Ronald Burt)، «کاتلین کارلی» (Kathleen Carley)، «مارک گرانوتر» (Mark Granovetter)، «دیوید کراکخاردت» (David Krackhardt)، «ادوارد لوامان» (Edward Laumann)، «آناتول راپوپورت» (Anatol Rapoport)، «بری ولمن» (Barry Wellman)، «داگلاس آروایت» (Douglas R. White) و «هریسون وایت» (Harrison Whit)، استفاده از تحلیلهای سیستماتیک شبکههای اجتماعی را گسترش دادند. امروزه تحلیلهای شبکههای اجتماعی در رشتههای آکادمیک گوناگون کاربرد پیدا کرده است.
سنجهها
در تحلیل شبکههای اجتماعی برخط، مفاهیم، اصطلاحات و سنجههایی وجود دارد که در پژوهشهای گوناگون و توسط دانشمندان این حوزه استفاده شدهاند. سه دسته اصلی از این سنجهها، «ارتباطات» (Connections)، «توزیعها» (Distributions) و «بخشبندی» (Segmentation) هستند.
از این سنجهها برای اندازهگیری مسائل گوناگونی که در گراف ساختاری مربوط به شبکههای اجتماعی برخط به وقوع میپیوندد بهره میبرند. آشنایی با این مفاهیم به منظور تحلیل شبکههای اجتماعی الزامی است. در ادامه هر یک از این دستهها توضیح داده شده است.
ارتباطات: این دسته از سنجهها به مفاهیم و اصطلاحات مربوط به ویژگیهای ارتباطات میان بازیگران در یک شبکه اجتماعی برخط میپردازند. «هوموفیلی» (Homophily)، رابطه متقابل، Multiplexity، بسته بودن شبکه و قرابت از این جمله هستند. اینکه بازیگران تا چه میزان با دیگر بازیگران شبیه یا غیرشبیه خود رابطه ایجاد میکنند را هوموفیلی گویند.
مشابهت میتواند از منظر جنسیت، نژاد، سن، شغل، پیشرفت تحصیلی، موقعیت، ارزشها یا مشخصههای برجسته دیگر تعریف شود. هوموفیلی، Assortativity نیز نامیده میشود. وجود انواع متعدد از فرمهای رابطه میان دو نفر را Multiplexity گویند. بهعنوان مثالی از Multiplexity میتوان به دو بازیگر که علاوه بر رابطه دوستی، رابطه همکاری نیز دارند اشاره کرد.
Multiplexity با قدرت روابط میان افراد ارتباط دارد. رابطه متقابل از دیگر اصطلاحهایی است که در تحلیل شبکههای اجتماعی به کار میرود و مفهوم آن این است که دو بازیگر به طور متقابل دوستان یا تعاملهای دیگری نیز دارند. بسته بودن شبکه، سنجهای برای کامل بودن سهتاییهای روابط میان افراد است. به رابطهای که طی آن شخصی که با یک بازیگر رابطه دارد، با بازیگری که بازیگر دوم با آن ارتباط دارد رابطه داشته باشد تعدی گویند. تمایل بازیگران به داشتن روابط بیشتر با بازیگرانی در فواصل جغرافیایی کمتر را «قرابت» (Propinquity) گویند.https://beta.kaprila.com/a//templates_ver2/templates.php?ref=blog.faradars&id=string-1&t=string&w=760&h=140&cid=2994503,2993970,2993985&wr=special,brother,brother&pid=54
توزیعها: سنجههای مربوط به پراکندگی بازیگران و ارتباطات میان آنها در شبکه در بحث توزیع مورد بررسی قرار میگیرد. «پل» (Bridge)، «مرکزیت» (Centrality)، «چگالی» (Density) شبکه، «چاله ساختاری» (Structural holes) و گراف همکاری از جمله تعاریف مربوط به توزیع در شبکه هستند. به فردی که روابط ضعیف او یک چاله ساختاری را با فراهم کردن تنها پیوند بین دو فرد یا خوشه پر میکند پل میگویند. پلها نقش مهمی در تحلیلهای ساختاری شبکههای اجتماعی دارند. پل، هنگامی که مسیرهای طولانی به دلیل ریسک بالای اعوجاج یا شکست در تحویل مناسب نیستند کوتاهترین مسیری است که انتخاب میشود.
مرکزیت به گروهی از سنجهها گفته میشود که هدف آنها تعیین کمیت «اهمیت» یا «نفوذ» یک گره مشخص (یا گروه) درون شبکه است. برخی از روشهای معمول اندازهگیری «مرکزیت» شامل «مرکزیت میانی» (betweenness centrality)، «مرکزیت نزدیکی» (closeness centrality)، «ویژهبردار مرکزیت» (eigenvector centrality)، «مرکزیت آلفا» (alpha centrality) و «مرکزیت درجه» (degree centrality) است.
نسبت روابط مستقیم موجود در یک شبکه به کل عدد ممکن را چگالی شبکه گویند. کمترین میزان روابط مورد نیاز برای ارتباط دو بازیگر مشخص را «فاصله» (Distance) گویند. در رابطه با فاصله بازیگران، «نظریه شش درجه جدایی» (six degrees of separation) توسط «استنلی میلگرام« (Stanley Milgram) مطرح شد که از طریق آن اثبات میشود هر دو شخص دلخواه روی کره زمین با شش واسطه یا کمتر به هم مربوط میشوند. این نظریه، مقدمه نظریه دیگری به نام «دنیای کوچک» (small world) است که مفهومی مشابه دارد. مفهوم شش درجه جدائی این نیست که به طور الزامی هر دو نفر حتما با پنج یا شش واسطه به یکدیگر مرتبط میشوند، بلکه گروه کوچکی از انسانها هستند که همچون پیوندی تمام آدمهایی را که در شبکههای مختلف قرار دارند به یکدیگر متصل میکنند، این افراد اتصالگر نامیده میشوند.
فقدان رابطه بین دو بخش از یک شبکه را چاله ساختاری گویند که مفهوم آن توسط «رونالد برت» (Ronald Burt)، جامعهشناس، ایجاد شده است. یافتن چالههای ساختاری و استفاده از آنها میتواند مزیت رقابتی ایجاد کند. قدرت روابط میان افراد بر اساس شدت عواطف، صمیمیت و روابط متقابل آنها سنجیده میشود. رابطه قوی به هوموفیلی، قرابت و تعدی وابسته است، در حالیکه روابط ضعیف به پلها مربوط میشوند. گراف همکاری برای نمایش روابط خوب و بد بین افراد شبکه، قابل استفاده است. یک یال مثبت بین دو گره حاکی از یک رابطه مثبت (دوستی، اتحاد) و یک یال منفی بین دو گره حاکی از یک رابطه منفی (نفرت، خشم) است.
گرافهای اجتماعی علامتدار برای پیشبینی سیر تکاملی گراف در آینده، استفاده میشوند. در شبکههای اجتماعی علامتدار، مفهوم حلقههای «متوازن» (balanced) و «نامتوازن» (unbalanced) وجود دارد. یک حلقه متوازن به عنوان حلقهای معرفی میشود که همه علامتها در آن مثبت هستند. گرافهای متوازن نشانگر گروهی از افراد هستند که احتمال تغییر ایده آنها درباره دیگر افراد داخل گروه وجود ندارد. چرخه نامتوازن نشانگر گروهی از افراد است که احتمال تغییر عقیده آنها درباره دیگر افراد حاضر در گروه زیاد است.
به عنوان مثال، یک گروه متشکل از سه فرد B ،A و C در صورتی که A و B رابطه مثبتی داشته باشند و B و C نیز رابطه مثبتی داشته باشند، اما A و C دارای رابطه منفی باشند، یک حلقه نامتوازن است. این گروه گرایش زیادی به تغییر آهسته به سوی یک حلقه متوازن دارند. با استفاده از مفهوم حلقههای متوازن و نامتوازن، تکامل گرافهای شبکههای اجتماعی قابل پیشبینی است.
بخشبندی: از این دسته سنجهها میتوان برای یافتن بخشهای گوناگون در ساختار شبکههای اجتماعی استفاده کرد. این بخشها ویژگیهای خاصی داشته و وجود آنها میتواند معنای خاصی در شبکه داشته باشد و در واقع توپولوژیهای مختلف قابل کشف در شبکه هستند. گروههکها یا به اصطلاح دار و دستهها، هنگامی ایجاد میشوند که یک فرد بهطور مستقیم با هر فرد دیگری ارتباط داشته باشد. در صورتیکه تاکیدی بر وجود رابطه مستقیم میان هر دو بازیگر وجود نداشته باشد، از مفهوم حلقههای اجتماعی استفاده میشود. احتمال ناهنجار بودن حلقههای اجتماعی نسبت به گروهکها کمتر است.
به احتمال رابطه داشتن دو بازیگر مرتبط با یک گره، ضریب خوشهبندی گویند. یک ضریب خوشهبندی بالا حاکی از وجود یک گروهک بزرگ است. گروهکها معمولا به عنوان ناهنجاری در شبکه محسوب میشوند. درجه اتصال مستقیم بازیگران به یکدیگر را انسجام گویند. میزان انسجام ساختاری بستگی به تعداد اعضایی دارد که اگر از گروه حذف شوند، اتصال کل گروه از بین میرود.
مدلسازی و بصریسازی شبکه
یکی از چالشهای مهم در تحلیل شبکههای اجتماعی برخط ارائه مدلی است که قادر به توصیف ساختار، رویدادها و نگاشتهایی باشد که در شبکههای اجتماعی به وقوع میپیوندد. مدلهای مختلفی با این منظور ارائه شدهاند که مدلهای ساختاری و مدلهای فضایی-زمانی از شاخصترین آنها هستند.https://beta.kaprila.com/a//templates_ver2/templates.php?ref=blog.faradars&id=string-2&t=related&col=4&title=%D8%A2%D9%85%D9%88%D8%B2%D8%B4%E2%80%8C%D9%87%D8%A7%DB%8C%20%D9%BE%DB%8C%D8%B4%D9%86%D9%87%D8%A7%D8%AF%DB%8C&w=800&h=285&cid=2994503,2993973,2993988,2993999&wr=special,brother,brother,brother&pid=58
در مدل ساختاری به جای داشتن مقادیر دودویی، هر یال بین کاربران در گراف اجتماعی به عنوان تابع فراوانی تعاملات بین آنها در نظر گرفته میشود. مدلسازی ساختاری در شبکههای اجتماعی با استفاده از نظریه گراف انجام میشود. اگرچه گرافها ارائه مناسبی برای تحلیل ویژگیهای فضایی شبکههای اجتماعی برخط هستند، گاه نیاز است جنبه زمانی شبکه نیز برای ارائه فرآیند نگاشت در شبکه در نظر گرفته شود، لذا از مدلهای فضایی-زمانی استفاده میشود.
جنبه زمانی شبکههای اجتماعی برخط دارای پیچیدگیهای زیادی است اما میتواند منبع ارزشمندی از اطلاعات شبکه باشد. ارائه بصری از شبکه مدل شده برای درک دادههای شبکه حائز اهمیت است و بسیاری از نرمافزارهای تحلیل شبکههای اجتماعی، ماژولهایی برای بصریسازی شبکه دارند.
نظریه گراف در مدلسازی شبکه
«نظریه گراف» (Graph Theory)، شاخهای از ریاضیات است که مباحث مربوط به گرافها را مورد بررسی قرار میدهد و در واقع شاخهای از توپولوژی است که با جبر و نظریه ماتریسها مرتبط است. گراف، مجموعهای از راسها است که به وسیله مجموعهای از زوجهای مرتب (یالها) به یکدیگر متصل میشوند. روشهای محاسبات و مفاهیم خاصی در حوزه گرافها وجود دارند.
از نظریه گراف، برای مصورسازی شبکههای اجتماعی استفاده میشود. بازیگران در شبکههای اجتماعی همان راسهای گراف و روابط میان آنها یالهای گراف است. گراف شبکه میتواند بدون جهت، یک جهتی، دو جهتی و یا وزندار باشد. توپولوژی شبکه که بهوسیله گراف ترسیم شده است، میتواند اطلاعات مهم و قابل توجهی از آنچه در شبکه به وقوع پیوسته و میپیوندد ارائه کند.
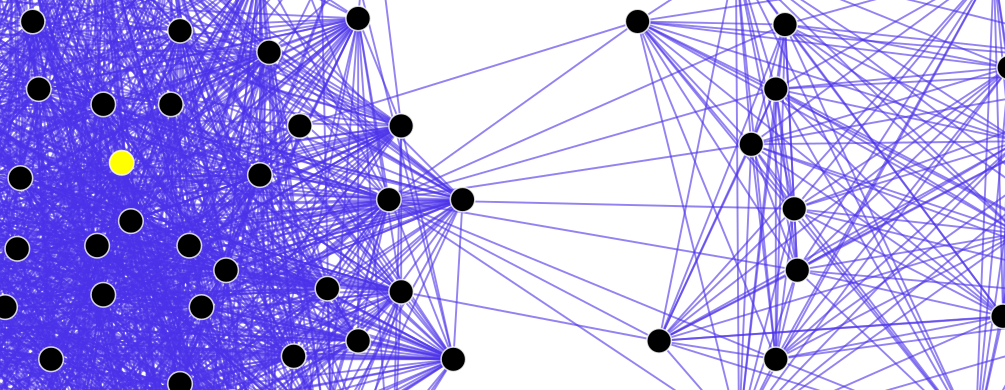
در شکل زیر گراف یک شبکه اجتماعی خیالی با ۱۶۵ گره و ۱۸۵۱ یال که به وسیله نظریه گراف مدلسازی شده نشان داده شده است. گره با بالاترین درجه مرکزیت در شکل به رنگ زرد نمایش داده شده است.
چرایی و کاربردهای تحلیل
توجه به شبکههای اجتماعی برخط توسط رسانهها، کسبوکارها و عموم مردم، انگیزه بسیار خوبی برای پژوهش در این حوزه است. دلایل قابل توجه دیگری برای علاقمندی پژوهشگران به این مبحث نیز وجود دارد که در ادامه آمدهاند. همه روزه حجم انبوهی از دادهها در شبکههای اجتماعی برخط تولید میشوند که بخشی از آن ها به صورت رایگان در دسترس پژوهشگران هستند. در دسترس بودن دادهها و سهولت دستیابی به دادههای اغلب شبکههای اجتماعی برخط، یکی از دلایل اصلی گرایش به پژوهش در این حوزه است. محتوای متنی تولید شده در شبکههای اجتماعی منابع تالیفی متفاوتی دارد، به این خصوصیت چندمولفهای بودن میگویند. این ویژگی، تنوع دادههای گردآوری شده و اطلاعات تولید شده را افزایش میدهد لذا شبکههای اجتماعی برخط به عنوان مخزنی غنی از متن برای پردازش زبان طبیعی هستند.
هر کاربر منحصر به فرد که در شبکه مشارکت دارد عاملی محسوب میشود که قادر به تصمیمگیری و تعامل با دیگر کاربران است. تعامل کاربران و پویایی تعاملهای پیچیده منجر به وقایع ناشناختهای میشود که توجه پژوهشگران متعددی را به خود جلب کرده است. تولید مداوم دادهها در شبکههای اجتماعی و به عبارتی پویایی زمانی آن این امکان را فراهم میکند که تحلیل فرآیندهای فضایی-زمانی و تحولاتی مانند تکامل موضوع و بسیج جمعی انجام شود.
در کنار تولید مستمر، دادهها در شبکههای اجتماعی به صورت آنی و در لحظه تولید میشوند و کاربران شبکه در زمان واقعی، هم به محرکهای داخلی و هم به محرکهای خارجی پاسخ میدهند. به دنبال توسعه فناوری، که منجر به افزایش دسترسی مردم به وسایل ارتباطی و اطلاعاتی شده، محتوای شبکههای اجتماعی برخط به صورت مجازی در هر لحظه و هر زمان قابل تولید هستند. دسترسیپذیری بالا و امکان تعیین منطقه جغرافیایی ارسال دادهها که یکی از ویژگیهای موجود در بسیاری از شبکههای اجتماعی است، امکانات جالب توجه و جدیدی را برای تحلیل فراهم میکند.
تحلیل شبکههای اجتماعی به طور گسترده در پهنه وسیعی از کاربردها و رشتهها استفاده میشود. برخی از کاربردهای تحلیل شبکه شامل مدلسازی انتشار شبکه، مدلسازی شبکه و نمونهبرداری، تحلیل خصیصهها و رفتار کاربران، پشتیبانی منابع، تحلیلهای تعاملات مبتنی بر موقعیت، اشتراکگذاری اجتماعی، توسعه «سیستمهای توصیهگر» (recommender systems) و پیشبینی پیوند میشود.
در بخش خصوصی و کسبوکارها از تحلیل شبکههای اجتماعی برای فعالیتهای پشتیبانی مانند تحلیل مشتریان و تعاملات آنها، توسعه سیستمهای اطلاعاتی، بازاریابی و هوش تجاری استفاده میکنند. از تحلیلهای شبکههای اجتماعی همچنین در سازمانهای ضدجاسوسی و فعالیتهای اجرای قانون استفاده میشود. این تحلیلها به پژوهشگران امکان میدهد که سازمانهای مخفی مانند حلقههای جاسوسی، جرایم سازمانیافته خانوادگی یا باندهای خیابانی را شناسایی کنند.
نشریات و مجلات معتبر بین المللی (ISI) در حوزه حقوق
لیست مجلات معتبر ISI اختصاصی برای گرایش های مختلف حوزه حقوق
یکی از شایع ترین اشتباهاتی که بسیاری از دانشجویان و اساتید دانشگاهی در انتخاب مجلات و نشریات برای ارسال مقاله خود مرتکب می شوند این است که به نوع مجلات توجهی نمی کنند و یا اینکه آشنایی کافی با مجلات معتبر دنیا ندارند. با توجه به اینکه مجلات و نشریات منتشر شده در سراسر دنیا، در زمینه های علمی و اجتماعی هر ساله توسط پایگاه اطلاعاتی Web of Science مورد ارزیابی قرار گرفته و رتبه مجلات با عنوان گزارش استنادی مجلات یا Journal Citation report) JCR) توسط موسسه اطلاعاتی علمی تامسون نمایه می شود. با این حال بسیاری از دانشجویان در یافتن مجلاتی که منحصرا برای رشته آنها باشد، و اینکه جز لیست مجلات نامعتبر نبوده و ضریب تاثیر (IF) خوبی هم داشته باشد، دچار سردرگمی می شوند. بنابر این، برای سهولت دسترسی دانشجویان و اساتید، نشریات و مجلات معتبر ISI بر اساس رشته های تحصیلی مختلف، دسته بندی شده اند.
در این بخش لیست مجلات و نشریات ISI مربوط به رشته حقوق برای استفاده اساتید و دانشجویانی که در این زمینه تحصیل می کنند، قرار داده شده است.
نشریات و مجلات معتبر بین المللی (ISI) در حوزه ارگونومی
لیست مجلات معتبر ISI اختصاصی برای گرایش های مختلف حوزه ارگونومی
یکی از شایع ترین اشتباهاتی که بسیاری از دانشجویان و اساتید دانشگاهی در انتخاب مجلات و نشریات برای ارسال مقاله خود مرتکب می شوند این است که به نوع مجلات توجهی نمی کنند و یا اینکه آشنایی کافی با مجلات معتبر دنیا ندارند. با توجه به اینکه مجلات و نشریات منتشر شده در سراسر دنیا، در زمینه های علمی و اجتماعی هر ساله توسط پایگاه اطلاعاتی Web of Science مورد ارزیابی قرار گرفته و رتبه مجلات با عنوان گزارش استنادی مجلات یا Journal Citation report) JCR) توسط موسسه اطلاعاتی علمی تامسون نمایه می شود. با این حال بسیاری از دانشجویان در یافتن مجلاتی که منحصرا برای رشته آنها باشد، و اینکه جز لیست مجلات نامعتبر نبوده و ضریب تاثیر (IF) خوبی هم داشته باشد، دچار سردرگمی می شوند. بنابر این، برای سهولت دسترسی دانشجویان و اساتید، نشریات و مجلات معتبر ISI بر اساس رشته های تحصیلی مختلف، دسته بندی شده اند.
در این بخش لیست مجلات و نشریات ISI مربوط به رشته ارگونومی برای استفاده اساتید و دانشجویانی که در این زمینه تحصیل می کنند، قرار داده شده است.
جدیدترین مجلات بلک لیست و جعلی دانشگاه آزاد اعلام شد
: سایت “دفتر گسترش تولید علم دانشگاه آزاد اسلامی” آخرین بلک لیست مجلات جعلی دانشگاه آزاد را در دی ماه 96 منتشر کرد.
به گزارش سایت خبری ساعد نیوز، آخرین بلک لیست مجلات و نشریات جعلی دانشگاه آزاد از سوی دفتر گسترش تولید علم دانشگاه آزاد اسلامی منتشر شد که فایل دانلود آن به منظور دسترسی و استفاده اساتید، دانشجویان و موسسات پژوهشی در ادامه مطلب قرار داده شده است.
دانشجویان و اساتید محترم بایستی توجه داشته باشند که با انتشار بلاک لیست جدید، لیست اعلام شده ی قبلی باطل می شود و لازم است تا بر اساس بلاک لیست جدید اقدام نمایند.
لازم به ذکر است که تمامی مجلات و نشریات در یک تاریخ و زمان مشخصی وارد بلاک نیست نمی شوند. ممکن است مجله یا نشریه ای سال ها اعتبار داشته و مورد تایید وزارت علوم و دانشگاه آزاد بوده اما در لیست جدید منتشر شده، جزء مجلات نامعتبر قرار گرفته است. در نتیجه توصیه اکید می شود که حتما قبل از اقدام به ارسال مقالات خود به نشریات و مجلات حتما بلاک لیست فوق را مطالعه نمایید تا با مشکلی مواجه نشوید.
نشریات و مجلات معتبر بین المللی (ISI) در حوزه مدیریت
لیست مجلات معتبر ISI اختصاصی برای گرایش های مختلف حوزه مدیریت
یکی از شایع ترین اشتباهاتی که بسیاری از دانشجویان و اساتید دانشگاهی در انتخاب مجلات و نشریات برای ارسال مقاله خود مرتکب می شوند این است که به نوع مجلات توجهی نمی کنند و یا اینکه آشنایی کافی با مجلات معتبر دنیا ندارند. با توجه به اینکه مجلات و نشریات منتشر شده در سراسر دنیا، در زمینه های علمی و اجتماعی هر ساله توسط پایگاه اطلاعاتی Web of Science مورد ارزیابی قرار گرفته و رتبه مجلات با عنوان گزارش استنادی مجلات یا Journal Citation report) JCR) توسط موسسه اطلاعاتی علمی تامسون نمایه می شود. با این حال بسیاری از دانشجویان در یافتن مجلاتی که منحصرا برای رشته آنها باشد، و اینکه جز لیست مجلات نامعتبر نبوده و ضریب تاثیر (IF) خوبی هم داشته باشد، دچار سردرگمی می شوند. بنابر این، برای سهولت دسترسی دانشجویان و اساتید، نشریات و مجلات معتبر ISI بر اساس رشته های تحصیلی مختلف، دسته بندی شده اند.
در این بخش لیست مجلات و نشریات ISI مربوط به رشته ارگونومی برای استفاده اساتید و دانشجویانی که در این زمینه تحصیل می کنند، قرار داده شده است.
نشریات و مجلات معتبر بین المللی (ISI) در حوزه آموزش و پژوهش آموزشی
لیست مجلات معتبر ISI اختصاصی برای گرایش های مختلف حوزه آموزش و پژوهش آموزشی
یکی از شایع ترین اشتباهاتی که بسیاری از دانشجویان و اساتید دانشگاهی در انتخاب مجلات و نشریات برای ارسال مقاله خود مرتکب می شوند این است که به نوع مجلات توجهی نمی کنند و یا اینکه آشنایی کافی با مجلات معتبر دنیا ندارند. با توجه به اینکه مجلات و نشریات منتشر شده در سراسر دنیا، در زمینه های علمی و اجتماعی هر ساله توسط پایگاه اطلاعاتی Web of Science مورد ارزیابی قرار گرفته و رتبه مجلات با عنوان گزارش استنادی مجلات یا Journal Citation report) JCR) توسط موسسه اطلاعاتی علمی تامسون نمایه می شود. با این حال بسیاری از دانشجویان در یافتن مجلاتی که منحصرا برای رشته آنها باشد، و اینکه جز لیست مجلات نامعتبر نبوده و ضریب تاثیر (IF) خوبی هم داشته باشد، دچار سردرگمی می شوند. بنابر این، برای سهولت دسترسی دانشجویان و اساتید، نشریات و مجلات معتبر ISI بر اساس رشته های تحصیلی مختلف، دسته بندی شده اند.
در این بخش لیست مجلات و نشریات ISI مربوط به رشته ارگونومی برای استفاده اساتید و دانشجویانی که در این زمینه تحصیل می کنند، قرار داده شده است.
نشریات و مجلات معتبر بین المللی (ISI) در حوزه انسان شناسی
لیست مجلات معتبر ISI اختصاصی برای گرایش های مختلف حوزه انسان شناسی
یکی از شایع ترین اشتباهاتی که بسیاری از دانشجویان و اساتید دانشگاهی در انتخاب مجلات و نشریات برای ارسال مقاله خود مرتکب می شوند این است که به نوع مجلات توجهی نمی کنند و یا اینکه آشنایی کافی با مجلات معتبر دنیا ندارند. با توجه به اینکه مجلات و نشریات منتشر شده در سراسر دنیا، در زمینه های علمی و اجتماعی هر ساله توسط پایگاه اطلاعاتی Web of Science مورد ارزیابی قرار گرفته و رتبه مجلات با عنوان گزارش استنادی مجلات یا Journal Citation report) JCR) توسط موسسه اطلاعاتی علمی تامسون نمایه می شود. با این حال بسیاری از دانشجویان در یافتن مجلاتی که منحصرا برای رشته آنها باشد، و اینکه جز لیست مجلات نامعتبر نبوده و ضریب تاثیر (IF) خوبی هم داشته باشد، دچار سردرگمی می شوند. بنابر این، برای سهولت دسترسی دانشجویان و اساتید، نشریات و مجلات معتبر ISI بر اساس رشته های تحصیلی مختلف، دسته بندی شده اند.
در این بخش لیست مجلات و نشریات ISI مربوط به رشته ارگونومی برای استفاده اساتید و دانشجویانی که در این زمینه تحصیل می کنند، قرار داده شده است.
ما در این سایت پرسشنامه های استاندارد (دارای روایی، پایایی، روش دقیق نمره گذاری ، منبع داخل و پایان متن ) ارائه می کنیم و همچنین تحلیل آماری کمی و کیفی رابا قیمت بسیار مناسب و کیفیت عالی و تجربه بیش از 17 سال انجام می دهیم. برای تماس به ما به شماره 09143444846 در شبکه های اجتماعی پیام بفرستید. ایمیلabazizi1392@gmail.com
تمامی حقوق مادی و معنوی این سایت متعلق به لنسرسرا و محفوظ است.
این سایت دارای مجوز می باشد