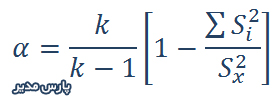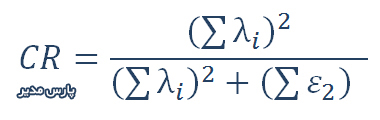...........................................................................................................................................................................................................................................................................................................................................................................
خوش آمدید این سایت دارای مجوز می باشد برای مشاهده مجوز ها پایین صفحه را مشاهده فرمائید.
پایایی ترکیبی composite reliability یک معیار ارزیابی برازش درونی مدل است و براساس میزان سازگاری سوالات مربوط به سنجش هر عامل قابل محاسبه است. این نوع پایایی شباهت زیادی به روایی همگرا دارد و از همان پارامترهای روایی همگرا برای محاسبه پایایی مرکب استفاده میشود.
مقایسه آلفای کرونباخ و پایایی ترکیبی
پایایی پرسشنامه به زبان ساده یعنی اینکه ابزار اندازهگیری در مکان دیگر یا زمان دیگر نتایج مشابهی بدست دهد. معیار سنتی محاسبه پایایی آلفای کرونباخ است. آلفای کرونباخ براساس میزان پراکنش دادهها تعیین میشود و انحراف معیار عامل اصلی سنجش پایایی است. از سوی دیگر پایایی ترکیبی براساس هماهنگی درونی سوالات هر عامل محاسبه میشود بنابراین معیار دقیق تری است.
فرمول محاسبه آلفای کرونباخ
محاسبه پایایی ترکیبی
برای محاسبه پایایی مرکب در نرم افزار لیزرل و اموس باید از فرمول پایایی ترکیبی مندرج در شکل فوق استفاده کنید. اصول محاسبه پایایی مرکب در نرم افزار PLS و تکنیک حداقل مجذورات جزیی نیز ثابت است ولی این نرم افزار برخلاف لیزرل مقدار CR را بدست میدهد و نیازی نیست با دست آن را محاسبه کنید. برای محاسبه پایایی ترکیبی در نرم افزار PLS کافی است به خروجی این نرم افزار رجوع کنید.
فرمول محاسبه پایایی ترکیبی
پایایی مرکب یا CR مخفف Composite Reliability میباشد. روایی همگرا زمانی وجود دارد که CR از ۰/۷ بزرگتر باشد. همچنین CR باید از AVE بزرگتر باشد. در اینصورت هر شرط روایی همگرا وجود خواهد داشت. بطور خلاصه داریم:
CR > 0.7 CR > AVE AVE > 0.5
با استفاده از بارهای عاملی به سادگی میتوان پایایی مرکب را در نرم افزار لیزرل محاسبه کرد. روی لینک محاسبه آنلاین پایایی ترکیبی کلیک کنید.
ضریب پایایی همگون Rho
پایایی ترکیبی با استفاده از فرمولی که توسط یورسکاگ ارائه شده نیز قابل محاسبه است. ضریب Rho نیز برای سنجش پایایی درونی سازهها است. همچنان که چین (۱۹۹۸) معتقد است ضریب Rho نسبت به آلفای کرونباخ از اطمینان بیشتری برخوردار است. به ضریب Rho گاهی ضریب دایلون-گولداشتین Dillon-Goldstein نیز گفته میشود. مقدار این ضریب باید بیش از ۰/۷ باشد. در نسخه شماره سه از نرم افزار Smart PLS این مقدار گزارش میشود.
منبع: آموزش محاسبه شاخص HTMT برای سنجش روایی گرا نوشته آرش حبیبی نشر الکترونیک پارسمدیر
هنسلر و همکاران (۲۰۱۵) شاخص جدیدی به نام Heterotrait-Monotrait Ratio یا HTMT برای ارزیابی روایی واگرا ارائه کردهاند. این شاخص در کانون تحلیل آماری پارس مدیر با عنوان نسبت روایی یگانه-دوگانه ترجمه شده است. شاخص HTMT جایگزین روش قدیمی فورنل-لارکر شده است. امکان محاسبه این معیار در نرم افزار Smart PLS 3 وجود دارد اما استفاده از روایی واگرا در همه روشهای رگرسیونی و مدل معادلات ساختاری کاربرد دارد. در این نوشتار قصد داریم تا روش محاسبه این شاخص را در نرم افزار اکسل و به صورت دستی آموزش دهیم.
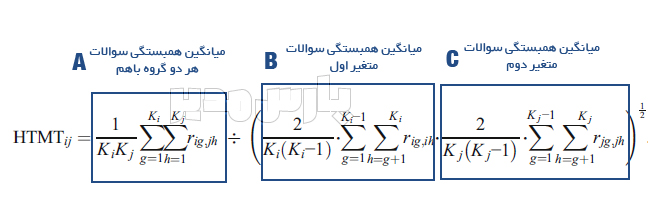
فرمول محاسبه شاخص HTMT
فرمول محاسبه شاخص HTMT به صورت زیر است:
فرمول محاسبه شاخص HTMT
اگرچه فرمول پیچیده به نظر میرسد اما من اینجا هستم تا این فرمول را برای شما ساده کنم. این فرمول از سه قسمت تشکیل شده است.
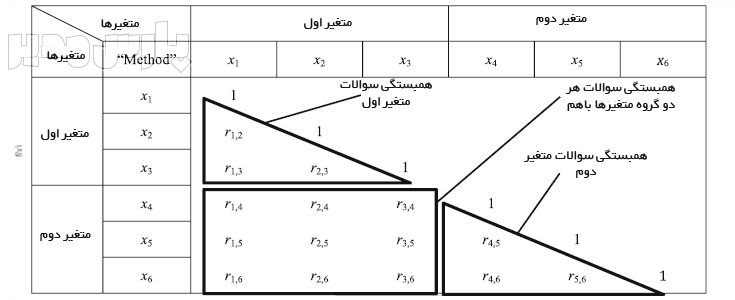
میانگین همبستگی سوالات دو متغیر باهم (A)
میانگین همبستگی سوالات متغیر اول (B)
میانگین همبستگی سوالات متغیر دوم (C)
بنابراین کافی است B را در C ضرب کنید. از عدد حاصل جذر بگیرید. سپس A را بر این عدد تقسیم کنید.
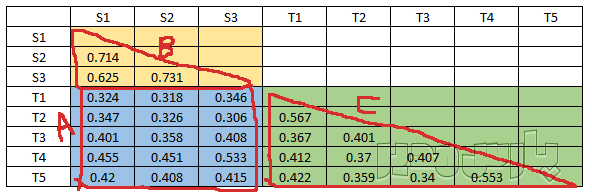
مثال عددی محاسبه HTMT
فرض کنید رابطه دو متغیر اعتماد و رضایت را با یک پرسشنامه بررسی میکنید. اعتماد دارای ۵ سوال و رضایت دارای ۳ سوال است. ضریب همبستگی سوالات این دو متغیر را محاسبه کنید.
مثال عددی محاسبه HTMT
این شکل را با شکل بالای صفحه و فرمول نوشته شده مقایسه کنید. بسیار ساده تر از آن چیزی بود که فکر میکردید.
میانگین مقادیر مثلث اول یا همبستگی سوالات متغیر اول (B) = 0/690
میانگین مقادیر مثلث اول یا همبستگی سوالات متغیر دوم (C) = 0/420
مجذور حاصلضرب میانگین دو مثلث = ۰/۵۳۸
میانگین مقادیر مربع آبی رنگ یعنی میانگین همبستگی سوالات دو متغیر باهم (A) = 0/388
مقدار HTMT روایی واگرا = ۰/۷۲۰
در نرم افزار PLS برای محاسبه شاخص HTMT کافیست رویه بوتاستراپینگ کامل را اجرا کنید. حد مجاز معیار HTMT میزان ۰/۸۵ تا ۰/۹ میباشد. اگر مقادیر این معیار کمتر از ۰/۹ باشد روایی واگرا قابل قبول است.
روایی واگرا Discriminant validity معیاری است که نشان میدهد چقدر سنجههای عوامل متفاوت واقعا باهم تفاوت دارند. در یک پرسشنامه برای سنجش عوامل مختلف سوالات متعددی مطرح میشود بنابراین لازم است که مشخص شود این سوالات از یکدیگر متمایز بوده و باهم همپوشانی ندارند.
این معیار در برابر روایی همگرا یا Convergent validity قرار میگیرد و گاهی به عنوان Divergent validity نیز در مقالههای علمی از آن یاد میشود. روایی همگرا به همبستگی سوالات یک سازه باهم اشاره دارد و روایی واگرا بر عدم همبستگی بین سوالات یک سازه با سوالات سازه دیگر دلالت دارد.
یکی از مهمترین مسائل در پژوهشها، تعیین میزان روایی و پایایی ابزار گردآوری دادههای پژوهش است. در بخش اعتبار یا روایی پرسشنامه Reliability، پژوهشگر در پی آن است که مشخص سازد آیا یافتههای بدست آمده از پژوهش را میتوان به کل جامعه یا گروههای مشابه آن تعمیم داد یا خیر؟ برخلاف پایایی یا اعتماد که مسئلهایی کمی است و اندازهگیری آن سادهتر است اعتبار پرسشنامه، مسألهای کیفی است و اندازهگیری و ارزیابی آن مشکلتر است. روایی به این سوال پاسخ میدهد که ابزار اندازهگیری تا چه حد خصیصه مورد نظر را میسنجد.
در نرم افزار Smart PLS و تکنیک حداقل مربعات جزیی سه روش برای محاسبه روایی وجود دارد:
روایی سازه
روایی همگرا
روایی واگرا
تعریف روایی واگرا
روایی واگرا نشان میدهد چقدر سوالات یک عامل با سوالات سایر عوامل تفاوت دارند. این معیار یکی از معیارهای اصلی برازش مدلهای اندازهگیری در روش PLS است و براساس بارهای عاملی مربوط به گویههای هر سازه تعیین میشود. روایی واگرا بر همبستگی پایین سنجههای یک متغیر پنهان با یک متغیر غیر مرتبط با آن (از نظر پژوهشگر) اشاره دارد. این معیار در روش حداقل مربعات جزئی از دو طریق سنجیده میشود. یکی روش بارهای عاملی متقابل است که میزان همبستگی بین شاخصهای یک سازه را با همبستگی آنها با سازههای دیگر مقایسه میکند و روش دیگر معیار پیشنهادی فورنل و لارکر Fornell & Larcker است که در این پژوهش مورد استفاده قرار گرفته است.
کلاس فورنل و دیوید لارکر
روایی واگرا یا در برابر روایی همگرا validity قرار دارد. فورنل و لارکر (۱۹۸۱) بیان کردند روایی واگرا وقتی در سطح قابل قبول است که میزان AVE برای هر سازه بیشتر از واریانس اشتراکی بین آن سازه و سازههای دیگر (یعنی مربع مقدار ضرایب همبستگی بین سازهها) در مدل باشد. بر این اساس روایی واگرای قابل قبول یک مدل اندازهگیری حاکی از آن است که یک سازه در مدل تعامل بیشتری با شاخصهای خود دارد تا با سازههای دیگر. در روش حداقل مربعات جزئی و مدلیابی معادلات ساختاری، این امر به وسیله یک ماتریس صورت میگیرد که خانههای این ماتریس حاوی مقادیر ضرایب همبستگی بین سازهها و قطر اصلی ماتریس جذر مقادیر AVE مربوط به هر سازه است.
در نرم افزار Smart PLS از قسمت Latent Variable Correlations در فایل خروجی استفاده میشود. قطر اصلی هم از مجذور AVE استفاده میشود.
روایی تشخیصی چیست؟
منظور از روایی تشخیصی همان روایی واگرا است. در زبان لاتین از دو اصطلاح Discriminant validity و Divergent validity استفاده میشود. این اصطلاح هر دو معادل هم استفاده میشوند و در مقالههای مختلف به جای هم به کار میروند. در زبان فارسی واژه Discriminant به معنای مشخصکننده یا تفکیک کننده ترجمه میشود. واژه Divergent نیز به صورت منشعب یا واگرا ترجمه میشود. بنابراین هر دو اصطلاح یکسان هستند و روایی تشخیصی چیز جدیدی نیست.
سه نگردد بریشم ار او را —– پرنیان خوانی و حریر و پرند
اگر به ابریشم بگویید پرند، پرنیان و حریر بازهم همان ابریشم است.
روایی واگرای یگانه-دوگانه HTMT
معیار Heterotrait-Monotrait Ratio یا شاخص HTMT در کانون تحلیل آماری پارس مدیر با عنوان معیار روایی یگانه-دوگانه ترجمه شده است. این معیار توسط هنسلر و همکاران (۲۰۱۵) برای ارزیابی روایی گرا ارائه شده است. معیار HTMT جایگزین روش قدیمی فورنل-لارکر شده است. حد مجاز معیار HTMT میزان ۰/۸۵ تا ۰/۹ میباشد. اگر مقادیر این معیار کمتر از ۰/۹ باشد روایی واگرا قابل قبول است. امکان محاسبه شاخص HTMT در نرم افزار Smart PLS 3 وجود دارد. برای این منظور باید رویه بوتاستراپینگ کامل را اجرا کنید.
روایی همگرا Convergent Validity یک سنجه کمی است که میزان همبستگی درونی و همسویی گویههای سنجش یک مقوله را نشان میدهد. مفهوم روایی پرسشنامه (اعتبار) به این سوال پاسخ میدهد که ابزار اندازهگیری تا چه حد خصیصه مورد نظر را میسنجد. پایایی پرسشنامه (قابلیت اعتماد) با این امر سروکار دارد که ابزار اندازهگیری در شرایط یکسان تا چه اندازه نتایج یکسانی را به دست میدهد. به عبارت دیگر همبستگی میان یک مجموعه از نمرات و مجموعه دیگری از نمرات در یک ازمون معادل که به صورت مستقل بر یک گروه آزمودنی به دست آمده است. روشهای متعددی برای محاسبه روایی وجود دارد که روایی همگرا یکی از آنها است.
هرگاه یک سازه (متغیر پنهان) براساس چند گویه (متغیر مشاهده پذیر) اندازهگیری شود همبستگی بین گویههای آن بوسیله روایی همگرا قابل بررسی است. اگر همبستگی بین بارهای عاملی گوبهها بالا باشد، پرسشنامه از نظر همگرایی معتبر میباشد. این همبستگی برای اطمینان از این که آزمون آنچه را که باید سنجیده شود میسنجد، ضروری است. برای روایی همگرا باید میانگین واریانس استخراج شده (AVE) محاسبه شود.
میانگین واریانس استخراج شده : AVE
میانگین واریانس استخراج شده یا AVE مخفف Average Variance Extracted میباشد. این شاخص توسط فورنل و لارکر به سال ۱۹۸۱ معرفی شده است. اعتبار همگرا براساس مدل بیرونی و با محاسبه میانگین واریانس استخراج (AVE) بررسی میشود. معیار AVE نشان دهنده میانگین واریانس به اشتراک گذاشته شده بین هر سازه با شاخصهای خود است. به بیان سادهتر AVE میزان همبستگی یک سازه با شاخصهای خود را نشان میدهد که هرچه این همبستگی بیشتر باشد، برازش نیز بیشتر است. فورنل و لارکرمعتقدند روایی همگرا زمانی وجود دارد که AVE از ۰/۵ بزرگتر باشد.
بطورکلی در یک پرسشنامه عوامل متعددی وجود دارد و هر عامل نیز براساس تعدادی گویه موردسنجش قرار میگیرد. در روایی محتوایی از نظر داوران برای سنجش میزان درستی و مناسب بودن گویهها استفاده میشود اما معیار AVE یک شاخص کمی برای سنجش روایی است. این معیار از بارهای عاملی مربوط به هر گویه برای سنجش آن استفاده میشود. در واقع این معیار نشان میدهد چقدر گویههای سنجش هر مقوله با هم از همبستگی کافی و بالایی برخوردار هستند.
محاسبه روایی همگرا در لیزرل و اموس
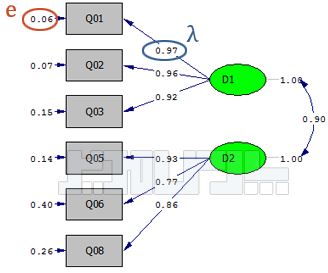
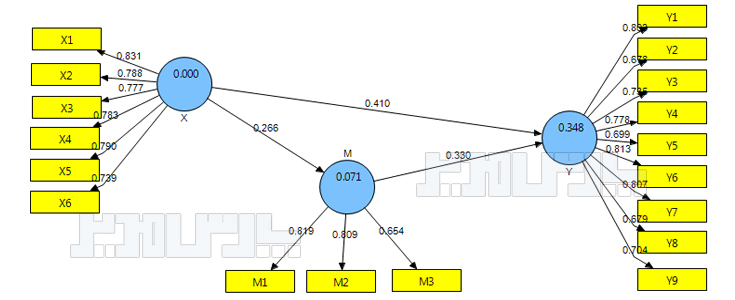
شکل زیر یک نمونه تحلیل عاملی تاییدی در نرم افزار لیزرل است. در این شکل دو عامل اصلی (متغیر پنهان) و ۶ گویه وجود دارد یعنی برای هر عامل سه گویه در نظر گرفته شده است. بارهای عاملی با λ نشان داده شده است. با توجه به فرمول مندرج در بالای صفحه کافی است تا مقادیر بارعاملی هر گویه را به توان دو برسانید و بعد میانگین آنها را حساب کنید. برای مثال برای سازه D1 روایی همگرا به صورت زیر قابل محاسبه است:
AVED1= [0.972+0.962+0.922]/3 = 0.903
محاسبه روایی همگرا
محاسبه مقدار خطا
یکی از پارامترهای جالب دیگری که میتوانید با دست حساب کنید مقدار خطا است. مقدار خطا که با حرف e در شکل فوق نشان داده است به سادگی با رابطه زیر قابل محاسبه است:
e = 1- λ۲
بنابراین مشاهده میشود که مقدار ۰/۰۶ برای گویه شماره یک با دست نیز قابل محاسبه است.
محاسبه روایی همگرا در Smart PLS
اصول محاسبه اعتبار همگرا در نرم افزار PLS و تکنیک حداقل مجذورات جزیی نیز ثابت است ولی این نرم افزار برخلاف لیزرل مقدار AVE را بدست میدهد و نیازی نیست با دست آن را محاسبه کنید. برای محاسبه روایی همگرا در نرم افزار PLS کافی است به خروجی این نرم افزار رجوع کنید.
پایایی ترکیبی CR
پایایی ترکیبی یا CR مخفف Composite Reliability میباشد. روایی همگرا زمانی وجود دارد که CR از ۰.۷ بزرگتر باشد. همچنین CR باید از AVE بزرگتر باشد. در اینصورت هم شرط روایی همگرا وجود خواهد داشت. بطور خلاصه داریم:
CR > 0.7 CR > AVE AVE > 0.5
با استفاده از بارهای عاملی به سادگی میتوان روایی همگرا را در نرم افزار لیزرل محاسبه کرد.
بوتاستراپینگ در حداقل مربعات جزئی یک شیوه خودگردان سازی یا استفاده مجدد از نمونه برای برآورد آماره تی و سنجش معناداری روابط است. به عبارت دیگر بوتاستراپینگ Bootstrapping آماره آزمون برای سنجش معناداری روابط میان متغیرها را محاسبه میکند.
حداقل مربعات جزئی فرض توزیع نرمال دادهها را ندارد به این معنی که آزمون معناداری پارامترها در تحلیل رگرسیون را نمیتوان برای آزمون اینکه آیا ضرائبی نظیر وزنها بیرونی، بارهای بیرونی و ضرائب مسیر، معنادار هستند، بکار برد. در عوض حداقل مربعات جزئی برای آزمون معناداری پارامترها بر رویه ناپارامتریک بوت استراپ تکیه کرده است.
در روش بوت استرپ تعداد زیادی زیر نمونه (نمونههای بوت استراپ) به روش جایگذاری بیرون کشیده میشود. جایگذاری به این معنا که هر زمان یک مشاهده به صورت تصادفی از جامعه نمونهگیری بیرون کشیده شد، قبل از بیرون شدن مشاهده بعدی، به جامعه نمونهگیری بر میگردد. یعنی جامعهای که مشاهدات از آن استخراج میشود، همواره حاوی عناصر مشابه است. بنابراین یک مشاهده میتواند بیش از یک مرتبه انتخاب شود یا در تمام زیرنمونهها اصلا انتخاب نشود. تعداد نمونههای بوتاسترپ باید بالا باشد اما باید حداقل برابر با تعداد مشاهدات معتبر در مجموع دادهها باشد. در نتیجه ۵۰۰۰ نمونه بوتاستراپ پیشنهاد میشود.
بوتاستراپینگ در نرم افزار PLS
اگر از توضیحات دکتر آذر در زمینه بوتاستراپینگ خیلی سر در نیاوردید من با یک مثال این روش را برای شما توضیح میدهم. بوتاستراپ Bootstrap همانطور که از نامش پیدا است به معنای تسمه پوتین و معادل آن در فارسی خودگردانسازی است. همانطور که شما تسمه پوتین را میکشید تا پوتین در پای شما جا بیفتد، رویههای مبتنی بر بوتاستراپینگ نیز کمک میکنند تا یک مقوله دشوار برای محاسبات نرمافزاری، ساده شود.
تسمه پوتین (بوتاستراپ)
کاربرد اصلی بوتاستراپ در حداقل مربعات جزئی سنجش معناداری روابط میان متغیرها است. بعد از اینکه مدل را ترسیم کردید برای اجرای بوتاستراپینگ از منوی Calculate گزینه bootstrapping را انتخاب کنید. همچنین در نوار ابزار نیز میتوانید به صورت زیر از bootstrapping استفاده کنید:
مسیر bootstrapping
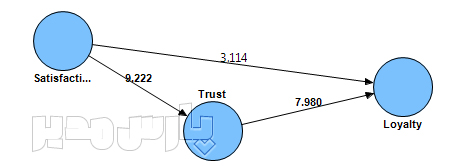
با اجرای این دستور آماره آزمون معادل آماره t-value در نرم افزار لیزرل و اموس محاسبه شده و برای تمامی روابط نمایش داده میشود. یک نمونه از خروجی دستور بوتاستراپینگ در نرم افزار حداقل مربعات جزئی به صورا زیر است:
خروجی بوتاستراپینگ در نرم افزار حداقل مربعات جزئی
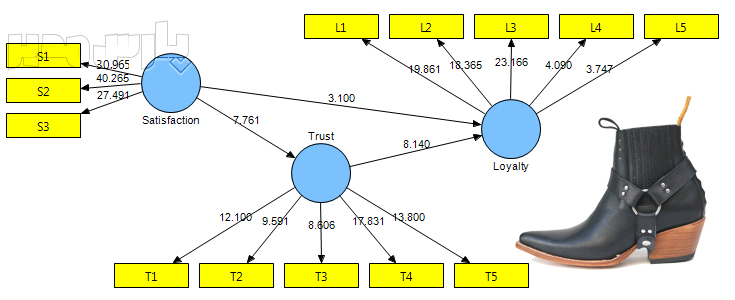
اعداد روی پیکان اتصال متغیرها به یکدیگر معادل همان آماره t میباشد. در سطح اطمینان ۹۵% چنانچه مقدار آماره آزمون از ۱/۹۶ بزرگتر باشد آن رابطه معنادار است. برای مثال آماره آزمون معناداری رابطه رضایت و وفاداری ۳/۱۱۴ بدست آمده است که از مقدار بحرانی ۱/۹۶ بزرگتر است بنابراین رابطه رضایت و وفاداری معنادار است (آرش حبیبی، پارسمدیر).
روند تحلیل بوتاستراپینگ
در بوتاستراپ لازم است توجه داشته باشید اندازه هر نمونه بوتاستراپ باید صریحاً مشخص شود. دستورالعمل پذیرفته شده این است که هر نمونه از بوتاستراپ باید تعداد مشابهی مشاهده نسبت نمونه اصلی داشته باشد. معمولا در ماژول بوت استراپ نرم افزار Smart PLS موارد بوتاستراپ نامیده میشود. برای مثال اگر نمونه اصلی دارای ۱۳۰ مشاهده معتبر باشد، هرکدام از ۵۰۰۰ نمونه بوتاستراپ باید شامل ۱۳۰ مورد باشد. در غیر اینصورت، نتایج آزمون معناداری به صورت سیستماتیک دارای اریبی هستند.
توجه داشته باشید که وقتی از جایگذاری مورد به مورد برای برخورد با مقادیر گم شده استفاده میشود، بسیار مهم است که از تعداد نهایی مشاهدات که برای برآورد مدل استفاده میشود، مطلع باشید. نمونههای بوتاستراپ برای برآورد مدل مسیری حداقل مربعات جزئی استفاده میشود. یعنی، وقتی از ۵۰۰۰ نمونه بوت استراپ استفاده میشود، ۵۰۰۰ مدل مسیری حداقل مربعات جزئی برآورد میشود.
فاصله اطمینان بوتاستراپ
تنها به جای گزارش معناداری پارامتر، گزارش فاصله اطمینان بوتاستراپ که اطلاعات بیشتری در مورد ثبات برآورد یک ضریب فراهم میکند، ارزشمند است. فاصله اطمینان، دامنهای است که در آن پارامتر واقعی جامعه با فرض سطح معینی از اطمینان (برای مثال ۹۵%) در آن قرار میگیرد.
در زمینه حداقل مربعات جزئی نیز درباره فاصله اطمینان بوتاستراپ صحبت میشود زیرا ساخت فاصله، براساس خطاهای معیار بدست آمده از رویه بوتاستراپینگ است. بسط این رویکرد، آزمون معناداری شامل فاصله اطمینان بوتاستراپینگ اصلاح شده هنسلر و همکاران میباشد. از آنجاییکه فواصل اطمیان بوتاستراپ و فواصل بوتاستراپ اصلاح شده اریبی معمولاً زیاد متفاوت نیستند، مقاله هنسلر و همکاران پیشنهاد میشود.
تحلیل مسیر (path analysis) روشی آماری مبتنی بر تحلیل رگرسیون چند متغیرى است که برای سنجش روابط متغیرها در یک مدل علّی استفاده میشود. در این روش از ضریب بتای استاندارد رگرسیون جهت تعیین جهت و شدت روابط میان متغیرها استفاده میشود. مقدار آماره تی نیز معناداری روابط را نشان میدهد.
هدف تحلیل مسیر به دست آوردن برآوردهاى کمى روابط على ( همکنشی یکجانبه یا کواریته) بین مجموعه اى از متغیرهاست. ساختن یک مدل علی لزوماً به معنای وجود روابط علی در بین متغیرهای مدل نیست بلکه این علیت بر اساس مفروضات همبستگی و نظر و پیشینه تحقیق استوار است. برای انجام محاسبات مربوط به تحلیل مسیر میتوان از نرمافزار SPSS استفاده کرد.
تحلیل مسیر جهت و شدت روابط متغیرهای تحقیق را نشان میدهد. مقادیری که جهت و میزان تاثیر میان متغیرها را نشان میدهند ضریب مسیر نامیده میشوند و با به صورت قراردادی با حرف بتای لاتین β نمایش داده میشوند. ضرایب مسیر همان ضریب استاندارد شده رگرسیون هستند. بنابراین برای تحلیل مسیر باید از رگرسیون خطی ساده استفاده شود. تحلیل مسیر تنها بر روی متغیرهای قابل مشاهده انجام پذیر است و اگر بخواهید بین ابعاد تحلیل مسیر را اجرا کنید باید میانگین سوالات هر بعد را حساب کنید تا متغیر پنهان به یک متغیر قابل مشاهده تبدیل شود.
پیشفرضهای تحلیل مسیر
برای انجام این محاسبات باید پیشفرضهایی در نظر گرفته شود که مهمترین آنها عبارتند از:
به ازای هر متغیر در مدل بین ۱۰ تا ۲۰ نمونه لازم است.
از متغیرهای نسبی و فاصلهای استفاده شود.
وجود رابطه خطی بین متغیرهای پیش بین با متغیر وابسته (Residual plot in regression Scatterplots)
استقلال خطاها یا غیر همبسته بودن جملات خطای متغیرها (آزمون دوربین-واتسون)
نرمال بودن دادهها و مشخص کردن آن با آزمون (Komogorov-Smirnov statistic)
عدم وجود همخطی چندگانه (Multicollinearity)
همخطی بودن چندگانه زمان بروز مییابد که بین حداقل دو متغیر مستقل همبستگی بالایی وجود داشته باشد.
یک سویه بودن جهت مدل (Recursive)
منظور از یک سیوه بودن این است که اگر A بر B تاثیر داشته باشد و B بر C اثر داشته باشد C بر A نمی تواند تاثیر داشته باشد. همچنین در بیشتر مطالعه مدیریت و علوم اجتماعی از طیف لیکرت استفاده میشود. این مقیاس رتبهای است لیکن بسیاری از پژوهشگران با کمی تسامح مقیاس لیکرت را مقیاس فاصلهای در نظر میگیرند.
اصول ترسیم نمودار مسیر
۱- عدم وجود حلقه
۲- عدم وجود مسیر رفت و برگشت بین متغیرها
۳- حداکثر تعداد همبستگیهای مجاز بین متغیرهای درونزا برابر با تعداد مسیرها
خطاهای ترسیم مدل در تحلیل مسیر
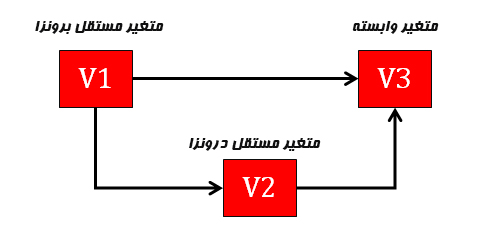
متغیرهای درونزا و برونزا
متغیرهای یک مدل میتوانند درونزا (Endogenous) یا برونزا (Exogenous) باشند بنابراین سه نوع متغیر قابل تمایز است:
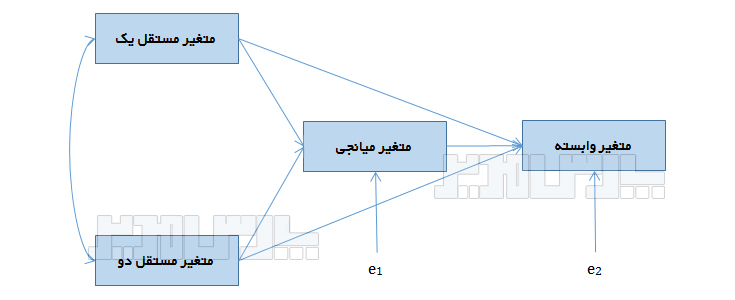
متغیر مستقل برونزا : متغیری که از هیچ متغیر دیگری تاثیر نمی گیرد اما بر همه یا برخی متغیرهای مدل تاثیر دارد. مقدار متغیر برونزا توسط سایر متغیرهای درون مدل تعیین نمی شود بلکه مقدار آن درخارج مدل تعیین میشود. متغیر برونزا متغیری است که هیچ اثری از سایر متغیرهای الگو و مدل طراحی شده نمی پذیرد.
متغیر مستقل درونزا (میانجی) : متغیری که از برخی متغیرها تاثیر میگیرد و برخی متغیرها تاثیر میگذارد.
متغیر وابسته : متغیری است که بر هیچ متغیری تاثیری ندارد اما از همه یا برخی متغیرهای مدل تاثیر میپذیرد.
از نظر نموداری متغیر برونزا متغیری است که هیچ فلشی به آن وارد نمی شود در حالیکه متغیر درونزا متغیری است که حداقل یک فلش به آن وارد میشود.
متغیرهای درونزا و برونزا
مسیر
مسیر در مدل علّی نشان دهنده اثر یک متغیر بر متغیر دیگر است. در تحلیل مسیر معمولا مسیر را با یک فلش جهت دار یک طرفه که ازمتغیر برونزا به متغیر مربوطه درونزا رسم شده است نمایش میدهند. میزان تاثیر متغیر i بر متغیر j با نماد βij نمایش داده میشود. اگر این مقدار منفی باشد یعنی رابطه معکوس است و اگر مثبت باشد این رابطه مستقیم است. مقدار ضریب بتا بین [۱ و ۱-] است و هر چه قدر مطلق این مقدار از ۰/۳ بیشتر باشد نشان میدهد تاثیر قوی تر است. اگر مقدار آماره t از ۱/۹۶ بزرگتر باشد رابطه معنادار است.
جملات خطا
جمله خطا یا error term نشان دهنده میزانی از واریانس متغیر درونزا است که از سوی متغیرهای موثر بر آن تبیین میگردد. بنابر این در یک مدل علّی به تعداد متغیرهای درونزا، جمله خطا وجود دارد. جمله خطا را معمولا با حرف e یا d نمایش میدهند. به میزان خطای باقیمانده residual نیز گویند و در یک مدل مسیر با استفاده از جذر ۱-R2 محاسبه میشود. منظور از R2 ضریب تشخیص (ضریب تعیین) است که مجذور ضریب بتای استاندارد میباشد.
طراحی مدل مسیر
برای طراحی مسیر ابتدا متغیرهای مدل را مشخص کنید. سپس براساس فرضیههای تحقیق جهت روابط را تعیین کنید. بری آزمون فرضیههای تحقیق نیز از رگرسیون خطی ساده استفاده کنید. ضرایب بتا و مقادیر خطا را به مدل منتقل کنید. دقت کنید میزان همبستگی متغیرهای مستقل برونزا را با روش پیرسون تعیین کنید. بین متغیرهای مستقل برونزا یک فلش دو جهته وجود دارد که همان ضریب همبستگی پیرسون است.
یک مدل مسیر میتواند دارای متغیر میانجی (Mediator) باشد و حتی نقش متغیرهای تعدیلگر (Moderator) نیز میتواند بررسی شود.
خروجی این مرحله ممکن است مجموعهای از فرضیههای مرتبط و یکپارچه باشد که معمولا از طریق ترسیمی و یا ریاضی بیان میشود.
در تحقیقات علوم اجتماعی مدلهای مفهومی معمولا به روش ترسیمی و نموداری بیان میشوند.
برای آزمون مدل مفهومی میتوان از رگرسیون در نرم افزار spss استفاده نمود.
انواع روابط بین متغیرها در نمودار تحلیل مسیر
۱- اثر مستقیم: بیانگر یک اثر مستقیم متغیر x بر روی متغیر y است.
۲- اثر غیر مستقیم: یک اثر غیرمستقیم متغیر x بر روی y از طریق یک متغیر پیشبینیکننده دیگر.رابطه بین X و Y وقتى غیر مستقیم است که X علت Z است و Z نیز به نوبه خود در Y اثر دارد.
بسیاری از پژوهشگران مایلند اثر کلی یک متغیر را بر متغیر دیگر محاسبه کنند این کار از طریق جمع اثر مستقیم با مجموع آثار غیرمستقیم آن به دست میآید. آثار غیرمستقیم از طریق حاصلضرب ضرائب هر مسیر محاسبه میشود:
۳- اثر کاذب: رابطه بین X و Y وقتى کاذب (Spurious) است که Z علت هر دو متغیر X و Y باشد.
۴- اثرات تحلیل نشده: رابطه بین دو متغیر وقتى تحلیل نشده است که هر دوى آنها برونزا (exogenous) بوده و بنابراین تبیین تغییر پذیرى بین آنها توسط مدل امکان پذیر نباشد.
خلاصه و جمعبندی
برای اعتبارسنجی الگوی روابط علی میان یک مجموعه از متغیرها میتوانید از تحلیل مسیر استفاده کنید. در این روش با استفاده از محاسبه ضریب بتای رگرسیون جهت و شدت روابط میان متغیرهای مدل قابل تبیین است. همچنین برای سنجش معناداری روابط میتوانید از آماره تی استفاده کرده یا به مقدار معناداری مشاهده شده استناد کنید. برای انجام این روش باید پیشفرضهایی نیز لحاظ شود که در مقاله فوق اشاره گردید. در نهایت در مقایسه این روش با مدل معادلات ساختاری باید گفت مدلهای ساختاری از اعتبار بیشتری برخوردار هستند.
آموزش حداقل مربعات جزئی : Partial Least Squares, PLS
حداقل مربعات جزئی یا Partial Least Squares یک روش ناپارامتریک است که جانشین مناسبی برای مدل معادلات ساختاری میباشد. روش حداقل مربعات جزئی به حجم نمونه حساسیت کمتری دارد و نیازی به نرمال بودن دادهها ندارد. بنابراین در موارد زیر جانشین مدلسازی معادلات ساختاری میشود:
زمانیکه حجم نمونه کوچک باشد
زمانیکه دادهها نرمال نباشد
دقت کنید اگر دادهها نرمال باشد یا نمونه بزرگ باشد هم میتوان از حداقل مجذورات جزیی استفاده کرد.
نرم افزارهای متعددی برای حداقل مجذورات جزئی وجود دارد که مهمترین آنها عبارتند از:
نرم افزار Visual PLS
نرم افزار Smart PLS
یکی از عمدهترین دلایل گرایش دانشجویان به استفاده از تکنیک حداقل مربعات جزئی این است که این تکنیک به فرض نرمال بودن جامعه و همچنین حجم نمونه متکی نیست. این در حالی است که برای انجام تکنیک معادلات ساختاری و نرمافزار لیزرل به حجم انبوهی از دادهها نیاز است. برای حل مسائل حداقل مربعات جزئی یا PLS میتوانید از نرم افزار SmartPLS استفاده کنید. نرم افزار smartpls یک نرم افزار رایگان است که دریافت آن کمی دردسر دارد ولی در وب سایت پارس مدیر نحوه دانلود آن تشریح شده است.
طراحی مدل حداقل مربعات جزیی
مانند مدل معادلات ساختاری در اینجا نیز باید با دو مفهوم متغیر پنهان و متغیر مشاهده پذیر آشنا باشد. متغیرهای پنهان همان عاملهای اصلی یا سازهها هستند که در شکل زیر با دایره نمایش داده شده اند. این متغیرها میتوانند مستقل یا وابسته باشند. متغیرهای مشاهده پذیر همان گویهها یا سوالات پرسشنامه هستند که در شکل زیر با مستطیل نمایش داده شده اند.
ساختار مدل حداقل مجذورات جزیی
مدل درونی و مدل بیرونی
مدل حداقل مجذورات جزئی به دو دو مدل بیرونی و مدل درونی قابل تفکیک است.
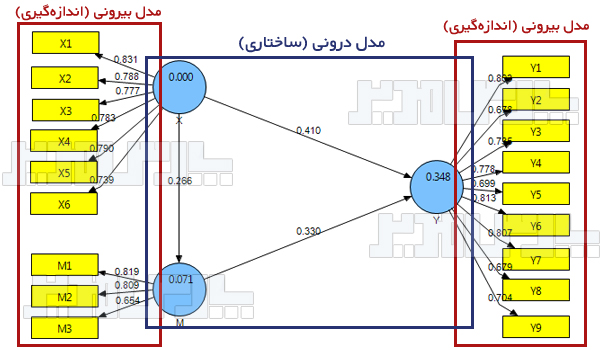
مدل بیرونی : مدل بیرونی یا Outer Model روابط گویهها (سوالات پرسشنامه) با عاملها (متغیرهای پنهان) را نشان میدهد و معادل تحلیل عاملی تاییدی یا مدل اندازهگیری در نرم افزار لیزرل و اموس میباشد.
مدل درونی : مدل درونی یا Inner Model مشابه تحلیل مسیر و بخش ساختاری یک مدل معادلات ساختاری است. پس از آزمون مدل بیرونی لازم است تا مدل درونی که نشانگر ارتباط بین متغیرهای پنهان است، ارایه شود. با استفاده از مدل درونی میتوان به بررسی فرضیههای پژوهش مدل پرداخت.
مدل درونی و مدل بیرونی
تفسیر مدل حداقل مربعات جزئی
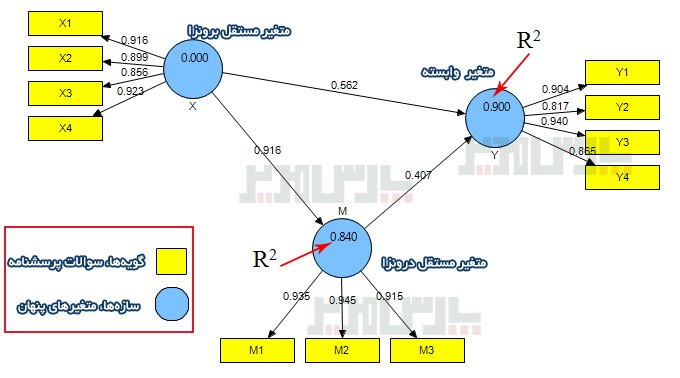
برای شناسایی قدرت و جهت روابط میان عناصر از تخمین استاندارد استفاده میشود. این مقادیر که در شکل فوق نیز قابل مشاهده است باید بالای ۰/۳ باشند. هرچه میزان بارعاملی بیشتر باشد قدرت روابط بیشتر است.
برای بررسی معناداری باید آماره t برآورد شود. برای این منظور از خودگردان سازی (بوت استراپینگ) یا برش جک-نایف استفاده میشود. اگر مقادیر آماره تی بالای ۱/۹۶ باشد رابطه معنادار است.
شاخصهای برازش مدل
در تکنیک حداقل مجذورات جزئی بر خلاف مدل معادلات ساختاری شاخصهای زیادی برای برازش وجود ندارد.
عمده ترین شاخصهای برازش مدل اندازهگیری عبارتند از:
بحث تعیین حجم نمونه PLS یکی از مباحث مهم حداقل مجذورات جزئی است. حوزه دیگری که در آن مدلسازی معادلات ساختاری مبتنی بر کوواریانس پیشنهاد میشود، شرایطی است که در آن سایز نمونه کوچک است، برای این رویکرد حداقل سایز نمونه باید ۱۰۰ باشد (بدون توجه به خصوصیات سایر داده ها) تا بتوان از راهکارهای مشکل ساز پرهیز کرد و به سطح پذیرش قابل قبولی دست یافت. حتی بسیاری از پژوهشگران، حداقل سایز نمونه را ۲۰۰ پیشنهاد میکنند تا از نتایجی که قابل تفسیر نیستند( مانند واریانس منفی و یا همبستگی بالای ۱) پرهیز شود.
حداقل مربعات جزئی در شرایطی که نمونه بسیار کوچک است نیز میتواند مورد استفاده قرار بگیرد. اگرچه این گونه شرایط فقط برای تحلیل قدرت آماری میتواند بکار برده شود. مونت کارلو نشان داد که این رویکرد میتواند برای حجم نمونه کمتر از ۵۰ نیز بکار رود، اچ. ولد با استفاده از ۲۷ متغیر، دو سازه پنهان و مجموعه داده هایی متشکل از ۱۰ نمونه دست به تحلیل زد. با این حال با در نظر گرفتن مشکل پایداری در مقیاس بزرگ، هنوز این مدل با محدودیت هایی روبروست.
جمع بندی بحث حداقل مربعات جزئی
حداقل مربعات جزئی راهکاری برای آزمون فرضیهها است و زمانی بکار میرود که حجم نمونه محدود باشد یا دادهها نرمال نباشند. بدون اینکه فرض هایی مانند فرضهای توزیع، و یا مقیاسهای اسمی، ترتیبی، و فاصلهای برای متغیرها، وجود داشته باشند، نتایج کار قابل استفاده میباشد. البته باید این نکته را نیز در ذهن داشت که حداقل مربعات جزئی هم همانند تمامی تکنیکهای آماری، نیازمند فرضهای خاصی است. مهمترین فرضیه، تشخیص “پیشبینی کننده” است. این الزام عنوان میکند که باید بخش سیستماتیک رگرسیون خطی را از روی انتظارات موقعیتی از متغیر وابسته تعریف کرد تا بتوان بر اساس رگرسیون نتیجهگیری کرد. با این حال، مشکل ثبات و پایداری در مقیاس بزرگ همچنان وجود دارد.
با توجه به مشکل سازگاری در نمونههای بزرگ، میتوان در مورد مناسب بودن حداقل مربعات جزئی دچار تردید شد و پرسید که چرا این تکنیک نمیتواند یکی از خصوصیتهای کلیدی یک مدل آماری (پایداری برآوردکننده ) را تضمین کند. پاسخ این است که این رویکرد با اصول خودش وارد وضعیتهای مختلف میشود .هدف از مدلسازی معادلات ساختاری مبتنی بر کوواریانس، تعیین ماتریس پارامترهای مدل Φ است که ماتریس کوواریانس پیشبینی شده توسط مدل نظری Σ(Φ)احتمال بسیار نزدیکی به ماتریس کوواریانس نمونه S دارد. برای این منظور باید تابع F(S, Σ) تعریف شود. وقتی S=Σ است، این تابع ارزش صفر را به خود اختصاص میدهد سایر موارد که ارزش تابع مثبت است، تفاوت بین Σ و S افزایش مییابد. با توجه به اینکه ماتریس کوواریانس نمونه، مبتنی بر احتمال شاخص اندازهگیری شده است، تابعی که بسیار در این خصوص استفاده میشود، تابع حداکثر کردن نرمال نظری است.
تکنیک Partial Least Squares یا حداقل مربعات جزئی یکی از موضوعاتی است که برای دانشجویان مدیریت و مهندسی صنایع بسیار ناشناخته است. برتری لیزرل که مطمئناً شناخته شده ترین ابزار برای انجام این گونه تحلیلهاست، ناشی از این مسأله است که تمامی محققین از تکنیکهای جایگزین مدلسازی معادلات ساختاری از جمله؛ حداقل مربعات جزئی آگاه نیستند.
یکی از عمدهترین دلایل گرایش دانشجویان به استفاده از تکنیک حداقل مربعات جزئی این است که این تکنیک به فرض نرمال بودن جامعه و همچنین حجم نمونه متکی نیست. این در حالی است که برای انجام تکنیک معادلات ساختاری و نرمافزار لیزرل به حجم انبوهی از دادهها نیاز است. برای حل مسائل حداقل مربعات جزئی یا PLS می توانید از نرم افزار SmartPLS استفاده کنید. نرم افزار smartpls یک نرم افزار رایگان است .
بطور کلی دو نوع رویکرد برای برآورد پارامترهای یک مدل معادلات ساختاری وجود دارد که عبارتند از: رویکرد مبتنی بر کوواریانس و رویکرد مبتنی بر واریانس. رویکرد اول در تلاش است تا اختلاف بین کوواریانسهای نمونه و آنچه که مدل نظری پیشبینی کرده است را حداقل کند. بخاطر شهرت فراوان مدلسازی معادلات ساختاری مبتنی بر کوواریانس، مطالعات متعددی وجود دارند که از این تکنیک تعریفی ارائه کرده اند. برخلاف رویکرد اول، رویکرد حداقل مربعات جزئی در ابتدا توسط اچ. ولد تحت عنوان حداقل مربعات جزئی تکراری غیرخطی معرفی شد که هدف از آن حداکثرکردن واریانس متغیرهای وابستهای است که توسط متغیرهای مستقل تعریف می شوند. همانند سایر مدلهای معادلات ساختاری، مدل حداقل مربعات جزئی نیز دارای بخش ساختاری است که منعکس کننده ارتباط بین متغیرهای پنهان (مکنون) و یک جزء اندازه گیری است.
برای آزمون مدل مفهومی پژوهش می توان از PLS که یک فن مدل سازی مسیر واریانس محور است، استفاده کرد. این تکنیک امکان بررسی روابط متغیرهای پنهان و سنجه ها (متغیرهای قابل مشاهده) را بصورت همزنان فراهم می سازد. از این روش زمانی که حجم نمونه کوچک بوده و یا توزیع متغیرها نرمال نباشد استفاده می شود. در مدل های PLS دو مدل آزمون می شود: مدلهای بیرونی و مدل های درونی. مدل بیرونی یا Outer Model مشابه اندازه گیری (CFA) و مدل درونی یا Inner Model مشابه تحلیل مسیر در مدل های معادلات ساختاری است . پس از آزمون مدل بیرونی لازم است تا مدل درونی که نشانگر ارتباط بین متغیرهای مکنون پژوهش است، ارایه شود. با استفاده از مدل درونی می توان به بررسی فرضیه های پژوهش مدل پرداخت.
مدل معادلات ساختاری = تحلیل عامل تائیدی + تحلیل مسیر
حداقل مربعات جزئی= مدل درونی + مدل بیرونی
ابزار مدل سازی معادلات ساختاری SEM
در مطالعات حوزه ي علوم انساني و اجتماعي، تجزيه و تحليل داده هاي پژوهش طبق فرآيندي با قالب کلي مشخص و يکسان صورت مي پذيرد که مرتبط با آن روش تحليل آماري متعددي تا به حال معرفي شده است. در اين ميان، مدل سازي معادلات ساختاري (SEM) که در اواخر دهه شصت ميلادي معرفي شد، ابزاري در دست محققين جهت بررسي ارتباط ميان چندين متغير در يک مدل را فراهم مي ساخت. قدرت اين تکنيک در توسعه نظريه ها باعث کاربرد وسيع آن در علوم مختلف از قبيل بازاريابي، مديريت منابع انساني، مديريت استراتژيک و سيستم اطلاعاتي شده است.
دلایل استفاده از SEM
يکي از مهمترين دلايل استفاده زياد پژوهشگران از SEM، قابليت آزمودن تئوري ها در قالب معادلات ميان متغيرهاست. دليل ديگر لحاظ نمودن خطاي اندازه گيري توسط اين روش است که به محقق اجازه مي دهد تا تجزيه و تحليل داده هاي خود را با احتساب خطاي اندازه گيري گزارش دهد.
دو نسل از مدل سازی معادلات ساختاری
مدل سازي معادلات ساختاري تا اين زمان، با دو نسل روش هاي تجزيه و تحليل داده ها معرفي شده است. نسل اول روش هاي مدل سازي معادلات ساختاري روش هاي کوواريانس محور هستند که هدف اصلي اين روش ها تاييد مدل بوده و براي کار به نمونه هايي با حجم بالا نياز دارند. نرم افزارهاي LISREL، AMOS، EQS و MPLUS چهار عدد از پرکاربردترين نرم افزارهاي اين نسل هستند.
چند سال پس از معرفي روش کوواريانس محور، به دليل نقاط ضعفي که در اين روش وجود داشت، نسل دوم روش هاي معادلات ساختاري که مولفه محور بودند، معرفي شدند. روش هاي مولفه محور که بعدا به روش حداقل مربعات جزئي تغيير نام دادند، براي تحليل داده ها روش هاي متفاوتي نسبت به نسل اول ارائه دادند.
پس از معرفي روش حداقل مربعات جزئي، اين روش از علاقه مندان بسياري برخوردار شد و پژوهشگران متعددي تمايل به استفاده از اين روش پيدا کردند. مهمترين نرم افزار براي اين روش Smart PLS مي باشد.
دلايل استفاده از روش pls و SmartPls در پایان نامه ها
محققين دلايل متعددي را براي استفاده از روش پي ال اس (PLS) ذکر نموده اند. مهمترين دليل، برتري اين روش براي نمونه هاي کوچک ذکر شده است. دليل بعدي داده هاي غيرنرمال است که محققين و پژوهشگران در برخي پژوهش ها با آن سر و کار دارند در نهايت دليل آخر استفاده از روش پي ال اس (PLS)، روبرون شدن با مدل هاي اندازه گيري سازنده است.
دلايل استفاده از روش معادلات ساختاري پي ال اس (PLS – SEM) به شرح زير است:
حجم کم نمونه
داده هاي غير نرمال
مدلهاي اندازه گيري از نوع سازنده
قدرت پيش بيني مناسب
پيچيدگي مدل ( تعداد زياد سازه ها و شاخص ها)
تحقيق اکتشافي
توسعه تئوري و نظريه
استفاده از متغيرهاي طبقه بندي شده
بررسي همگرايي
آزمودن تئوري و فرضيه
آزمودن فرضيات شامل متغيرهاي تعديلگر
بهترين دليل استفاده از PLS
با توجه به موارد بالا، حجم نمونه اندک بهترين دليل استفاده از PLS است. روش هاي نسل اول مدل سازي معادلات ساختاري که با نرم افزارهايي نظير LISREL، EQS و AMOS اجرا مي شدند، نياز به تعداد نمونه زياد دارند، در حالي که PLS (پي ال اس) توان اجراي مدل با تعداد نمونه خيلي کم را دارا مي باشد.
حداقل مربعات جزئی
حداقل مربعات جزئی راهکاری برای آزمون فرضیه ها است و زمانی بکار میرود که حجم نمونه محدود باشد یا داده ها نرمال نباشند. بدون اینکه فرض هایی مانند فرضهای توزیع، و یا مقیاسهای اسمی، ترتیبی، و فاصلهای برای متغیرها، وجود داشته باشند، نتایج کار قابل استفاده میباشد. البته باید این نکته را نیز در ذهن داشت که حداقل مربعات جزئی هم همانند تمامی تکنیکهای آماری، نیازمند فرضهای خاصی است. مهمترین فرضیه، تشخیص “پیش بینی کننده” است. این الزام عنوان میکند که باید بخش سیستماتیک رگرسیون خطی را از روی انتظارات موقعیتی از متغیر وابسته تعریف کرد تا بتوان بر اساس رگرسیون نتیجه گیری کرد. با این حال، مشکل ثبات و پایداری در مقیاس بزرگ همچنان وجود دارد.
با توجه به مشکل سازگاری در نمونه های بزرگ، میتوان در مورد مناسب بودن حداقل مربعات جزئی دچار تردید شد و پرسید که چرا این تکنیک نمیتواند یکی از خصوصیت های کلیدی یک مدل آماری (پایداری برآوردکننده ) را تضمین کند. پاسخ این است که این رویکرد با اصول خودش وارد وضعیتهای مختلف میشود .هدف از مدلسازی معادلات ساختاری مبتنی بر کوواریانس ، تعیین ماتریس پارامترهای مدل Φ است که ماتریس کوواریانس پیش بینی شده توسط مدل نظری Σ(Φ)احتمال بسیار نزدیکی به ماتریس کوواریانس نمونه S دارد. برای این منظور باید تابع F(S, Σ) تعریف شود. وقتی S=Σ است، این تابع ارزش صفر را به خود اختصاص میدهد سایر موارد که ارزش تابع مثبت است، تفاوت بین Σ و S افزایش مییابد. با توجه به اینکه ماتریس کوواریانس نمونه، مبتنی بر احتمال شاخص اندازهگیری شده است، تابعی که بسیار در این خصوص استفاده می شود، تابع حداکثر کردن نرمال نظری است.
علت انجام تحلیل آماری با استفاده از SmartPLS
اصلی ترین دلایل استفاده از نرم افزار Smartpls به شرح زیر است :
1- حجم نمونه کم باشد.
2- داده ها نرمال نباشند.
در صورتی که حجم دیتاها زیاد و یا داده ها نرمال باشند نیز میتوان از این روش استفاده کرد.
ویژگی های تحلیل آماری با نرم افزار SmartPLS
1-روش معادلات ساختاری مبتنی بر واریانس بر پیش بینی عوامل تمرکز دارد.
2-روش معادلات ساختاری مبتنی بر واریانس برای اکتشاف تئوری کاربرد دارد.
3-با حجم نمونه کوچک نیز قابل انجام است.
4-برای مدل های انعکاسی و تکوینی کاربرد دارد.
5-از عوامل با یک گویه پشتیبانی می کند.
6-مشکلی برای برازش داده ای که دارای مقادیر گم شده است، ندارد.
7-از داده های دارای چند-همخطی پشتیبانی می کند.
جدول تفاوت نرم افزار SmartPLS و AMOS و Lisrel
Lisrel, Amos, Eqs, Mplus
SmartPLS, PLS Graph
تئوری
قوی
پیچیده
توزیع
نرمال چندمتغیره
ناپارامتریک
تعداد نمونه
بزرگ (حداقل 200 نمونه)
کوچک (بین 30-100)
تمرکز تحلیل
تایید روابط فرض شده در تئوری
پیش بینی و شناسایی روابط میان عوامل
تعداد نشان گرها در هر شاخص
به صورت ایده آل بیشتر از 4
یک یا بیشتر
نشانگرهای هر شاخص
در اصل انعکاسی
انعکاسی و تکوینی
نوع اندازه گیری
فاصله ای یا نسبتی
داده های رسته ای، نسبتی
مراحل تحلیل آماری با SmartPLS
رسم مدل و براورد ضرایب رگرسیون
اندازه گیری مقادیر آماره تی-استودنت و مقایسه آن با عدد 1.96
بررسی پایایی(آلفای کرونباخ و ضریب پایایی ترکیبی) مدل معادلات ساختاری
بررسی روایی همگرا مدل(شاخص AVE)
بررسی روایی افتراقی(شاخص فورنل-لارکر)
بررسی شاخص های نیکویی برازش مدل معادلات ساختاری
بررسی شاخص استون-گیسر جهت تایید تناسب پیش بین مدل معادلات ساختاری
تحليل عاملي اکتشافي (efa) و تحليل عاملي تاييدي (cfa)
تحليل عاملي ميتواند دو صورت اکتشافي و تاييدي داشته باشد. اينکه کدام يک از اين دو روش بايد در تحليل عاملي به کار رود مبتني بر هدف تحليل داده هاست.
در تحليل اکتشافي(Exploratory factor analysis) پژوهشگر به دنبال بررسي دادههاي تجربي به منظور کشف و شناسايي شاخصها و نيز روابط بين آنهاست و اين کار را بدون تحميل هر گونه مدل معيني انجام ميدهد. به بيان ديگرتحليل اکتشافي(Exploratory factor analysis) علاوه بر آنکه ارزش تجسسي يا پيشنهادي دارد ميتواند ساختارساز، مدل ساز يا فرضيه ساز باشد.
تحليل اکتشافي وقتي به کار ميرود که پژوهشگر شواهد کافي قبلي و پيش تجربي براي تشکيل فرضيه درباره تعداد عاملهاي زيربنايي دادهها نداشته و به واقع مايل باشد درباره تعيين تعداد يا ماهيت عاملهايي که همپراشي بين متغيرها را توجيه ميکنند دادهها را بکاود. بنابر اين تحليل اکتشافي بيشتر به عنوان يک روش تدوين و توليد تئوري و نه يک روش آزمون تئوري در نظر گرفته ميشود.
تحليل عاملي اکتشافي روشي است که اغلب براي کشف و اندازه گيري منابع مکنون پراش و همپراش در اندازه گيريهاي مشاهده شده به کار ميرود. پژوهشگران به اين واقعيت پي برده اند که تحليل عاملي اکتشافي ميتواند در مراحل اوليه تجربه يا پرورش تستها کاملا مفيد باشد. توانشهاي ذهني نخستين ترستون ، ساختار هوش گيلفورد نمونههاي خوبي براي اين مطلب ميباشد. اما هر چه دانش بيشتري درباره طبيعت اندازه گيريهاي رواني و اجتماعي به دست آيد ممکن است کمتر به عنوان يک ابزار مفيد به کار رود و حتي ممکن است بازدارنده نيز باشد.
از سوي ديگر بيشتر مطالعات ممکن است تا حدي هم اکتشافي و هم تاييدي باشند زيرا شامل متغير معلوم و تعدادي متغير مجهولاند. متغيرهاي معلوم را بايد با دقت زيادي انتخاب کرد تا حتي الامکان درباره متغيرهاي نامعلومي که استخراج ميشود اطلاعات بيشتري فراهم ايد. مطلوب آن است که فرضيه اي که از طريق روشهاي تحليل اکتشافي تدوين ميشود از طريق قرار گرفتن در معرض روشهاي آماري دقيقتر تاييد يا رد شود. تحليل اکتشافي نيازمند نمونههايي با حجم بسيار زياد ميباشد.
در تحليل عاملي تاييدي(Confirmatory factor analysis) ، پژوهشگر به دنبال تهيه مدلي است که فرض ميشود دادههاي تجربي را بر پايه چند پارامتر نسبتا اندک، توصيف تبيين يا توجيه ميکند. اين مدل مبتني بر اطلاعات پيش تجربي درباره ساختار داده هاست که ميتواند به شکل: 1) يک تئوري يا فرضيه 2) يک طرح طبقه بندي کننده معين براي گويهها يا پاره تستها در انطباق با ويژگيهاي عيني شکل و محتوا ، 3)شرايط معلوم تجربي و يا 4) دانش حاصل از مطالعات قبلي درباره دادههاي وسيع باشد.
تمايز مهم روشهاي تحليل اکتشافي و تاييدي در اين است که روش اکتشافي با صرفهترين روش تبيين واريانس مشترک زيربنايي يک ماتريس همبستگي را مشخص ميکند. در حالي که روشهاي تاييدي (آزمون فرضيه) تعيين ميکنند که دادهها با يک ساختار عاملي معين (که در فرضيه آمده) هماهنگ اند يا نه.
تحليل عاملي اکتشافي (efa) و تحليل عاملي تاييدي (cfa)
محدوديت هاي تحليل مسير تحليل مسير نمي تواند ساختار علي زير بنايي را تاييد كند يعني بيان مي كند كه نقش نسبي متغييرها چيست اما ساختار علي مورد نظر محقق را بيان نمي سازد. با توجه به اين كه علت داراي تقدم زماني نسبت به معلول است بايد ترتيب زماني وقوع قبل از معلول وجود داشته باشد. براي ترتيب احتمالي متغييرها در دنياي واقعي ناگزيريم به مفاهيم نظري و شعور عادي خود متكي باشيم. در ادامه فهرستي از اين محدوديت ها ارائه مي شود:
تحليل مسير مي تواند فرضيه هاي علي را ارزشيابي كند و در برخي از موارد نيز دو يا چند فرضيه ي علي را بيازمايد اما هرگز نمي تواند جهت عليت محقق را مشخص كند یعنی نمی تواند گفت X علت Y است و یا برعکس.
2. تحليل مسير زماني مفيد است كه فرضيه هاي روشني براي آزمون يا تعداد كمي فرضيه كه همه آنها را بتوان در يك نمودار واحد نشان داد در دست باشد. یعنی برای تعداد کمی از رابطه ها مناسب است.
3. تحليل مسير را نمي توان به منظور اهداف اكتشاف (تحلیل اکتشافی) استفاده كرد.
4. اين تحليل را نمي توان براي موقعيت هايي كه حلقه هاي بازخورد در فرضيه ها گنجانده شده است استفاده نمود.
5. همه ي متغييرهاي مداخله گر بايد در تحليل رگرسيون چند متغييري به عنوان متغييرهاي وابسته عمل كنند. بنابراين همه آنها بايد داراي مقياس فاصله اي باشند. اندازه هاي طبقه اي يا ترتيبي تحليل مسير را نا ممكن مي سازند.
ما در این سایت پرسشنامه های استاندارد (دارای روایی، پایایی، روش دقیق نمره گذاری ، منبع داخل و پایان متن ) ارائه می کنیم و همچنین تحلیل آماری کمی و کیفی رابا قیمت بسیار مناسب و کیفیت عالی و تجربه بیش از 17 سال انجام می دهیم. برای تماس به ما به شماره 09143444846 در شبکه های اجتماعی پیام بفرستید. ایمیلabazizi1392@gmail.com
تمامی حقوق مادی و معنوی این سایت متعلق به لنسرسرا و محفوظ است.
این سایت دارای مجوز می باشد