رگرسیون در مقابل معادلات ساختاری (SEM): کدام روش تحلیل آماری برای پژوهش شما مناسبتر است؟
اگر در انتخاب بین روشهای پیشرفته آماری مانند رگرسیون و معادلات ساختاری (SEM) سردرگم هستید، این مقاله راهنمای نهایی شماست. در این مطلب جامع، به زبان ساده اما علمی، تفاوتهای کلیدی، کاربردهای عملی و نحوه انتخاب صحیح بین این دو روش قدرتمند آماری را بررسی میکنیم. پاسخ کامل سوال خود را در ادامه بیابید.
تحلیل رگرسیون: ابزار کلاسیک برای روابط خطی
رگرسیون یکی از بنیادیترین و پرکاربردترین روشهای تحلیل آماری است. این روش رابطه بین یک متغیر وابسته (پاسخ) و یک یا چند متغیر مستقل (پیشبین) را مدلسازی میکند.
انواع اصلی رگرسیون
- رگرسیون خطی ساده: بررسی رابطه بین یک متغیر مستقل و یک متغیر وابسته
- رگرسیون خطی چندگانه: بررسی همزمان اثر چند متغیر مستقل بر یک متغیر وابسته
- رگرسیون لجستیک: مناسب برای زمانی که متغیر وابسته دو حالتی یا چندحالتی است
فرضیات اساسی رگرسیون
برای استفاده صحیح از رگرسیون، باید این فرضیات را بررسی کنید:
- رابطه خطی بین متغیرها
- استقلال خطاها
- نرمال بودن توزیع خطاها
- همسانی واریانس خطاها
- عدم همخطی کامل بین متغیرهای مستقل
معادلات ساختاری (SEM): چارچوبی جامع برای مدلسازی پیچیده
معادلات ساختاری (SEM) یک رویکرد تحلیلی پیشرفته و جامع است. SEM ترکیبی از تحلیل عاملی تأییدی و تحلیل مسیر میباشد. این روش امکان آزمون مدلهای نظری پیچیده با چندین معادله را فراهم میکند.

اجزای اصلی مدلسازی معادلات ساختاری
SEM از دو بخش کلیدی تشکیل شده است:
- مدل اندازهگیری: رابطه بین سازههای پنهان و شاخصهای مشاهدهشده را بررسی میکند.
- مدل ساختاری: روابط علی بین سازههای پنهان را آزمون مینماید.
مزایای منحصربهفرد SEM
- توانایی کار با متغیرهای پنهان (سازههای نظری)
- کنترل خطای اندازهگیری
- آزمون همزمان روابط مستقیم و غیرمستقیم
- ارزیابی برازش کلی مدل با شاخصهای معتبر
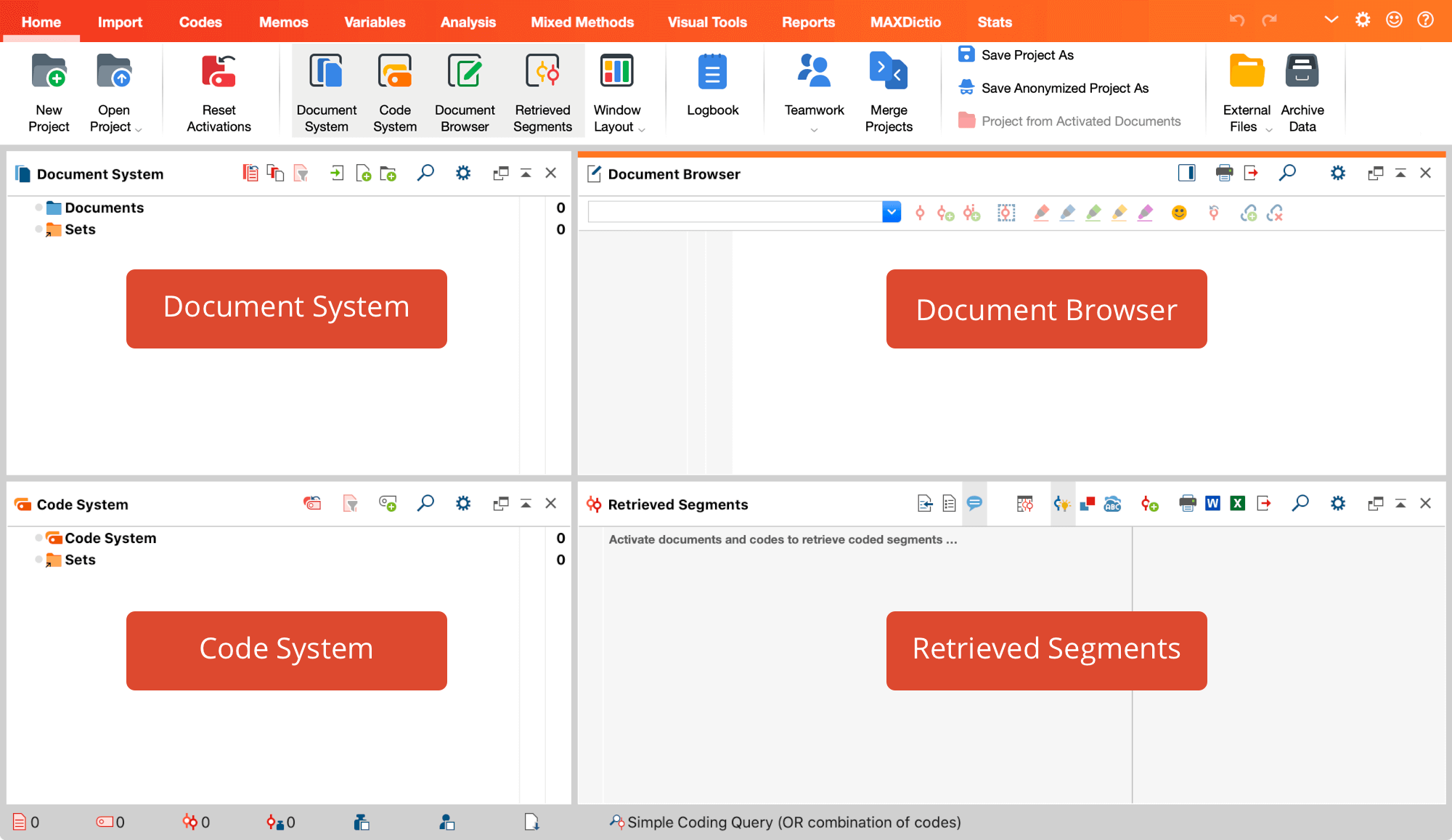
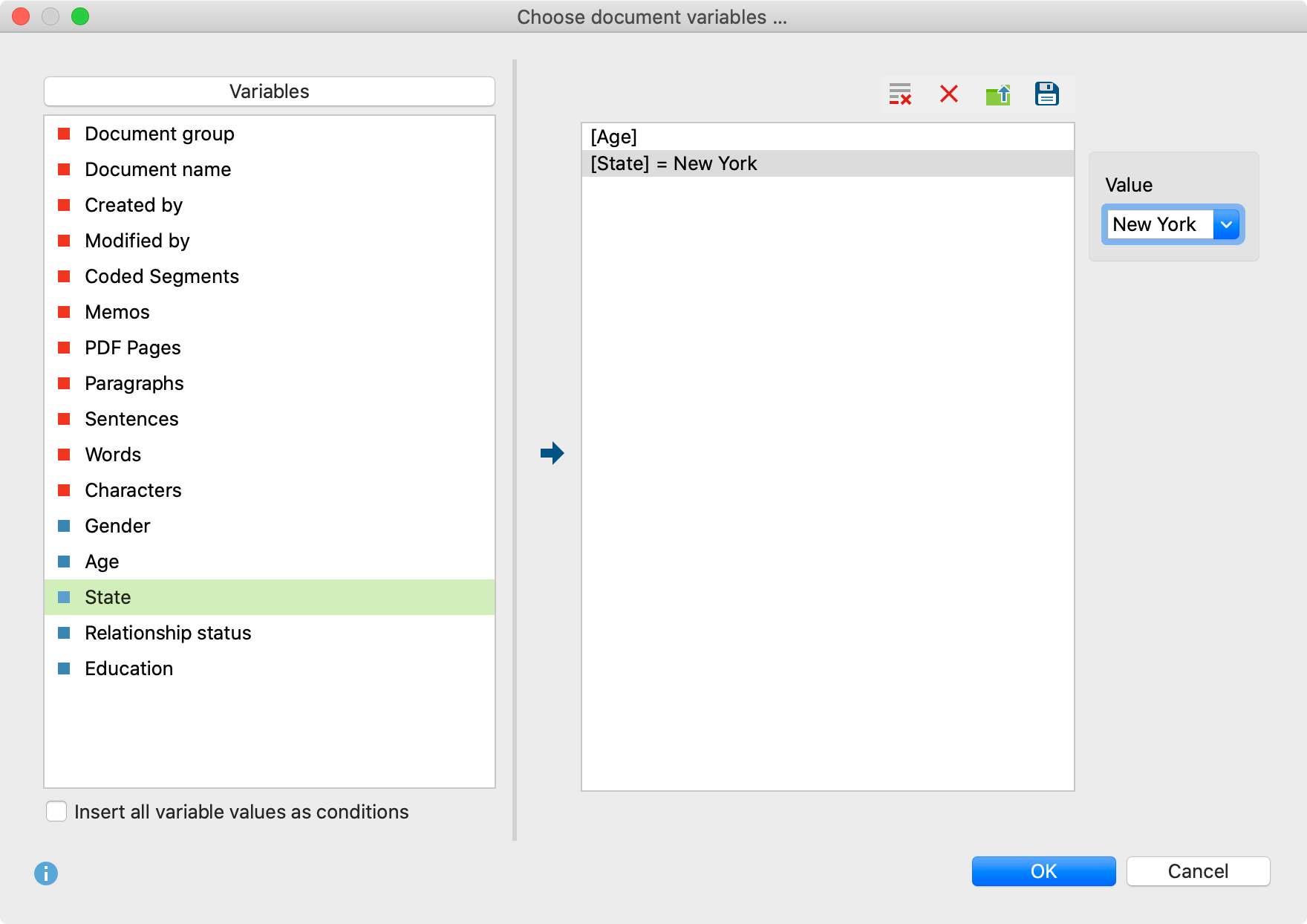
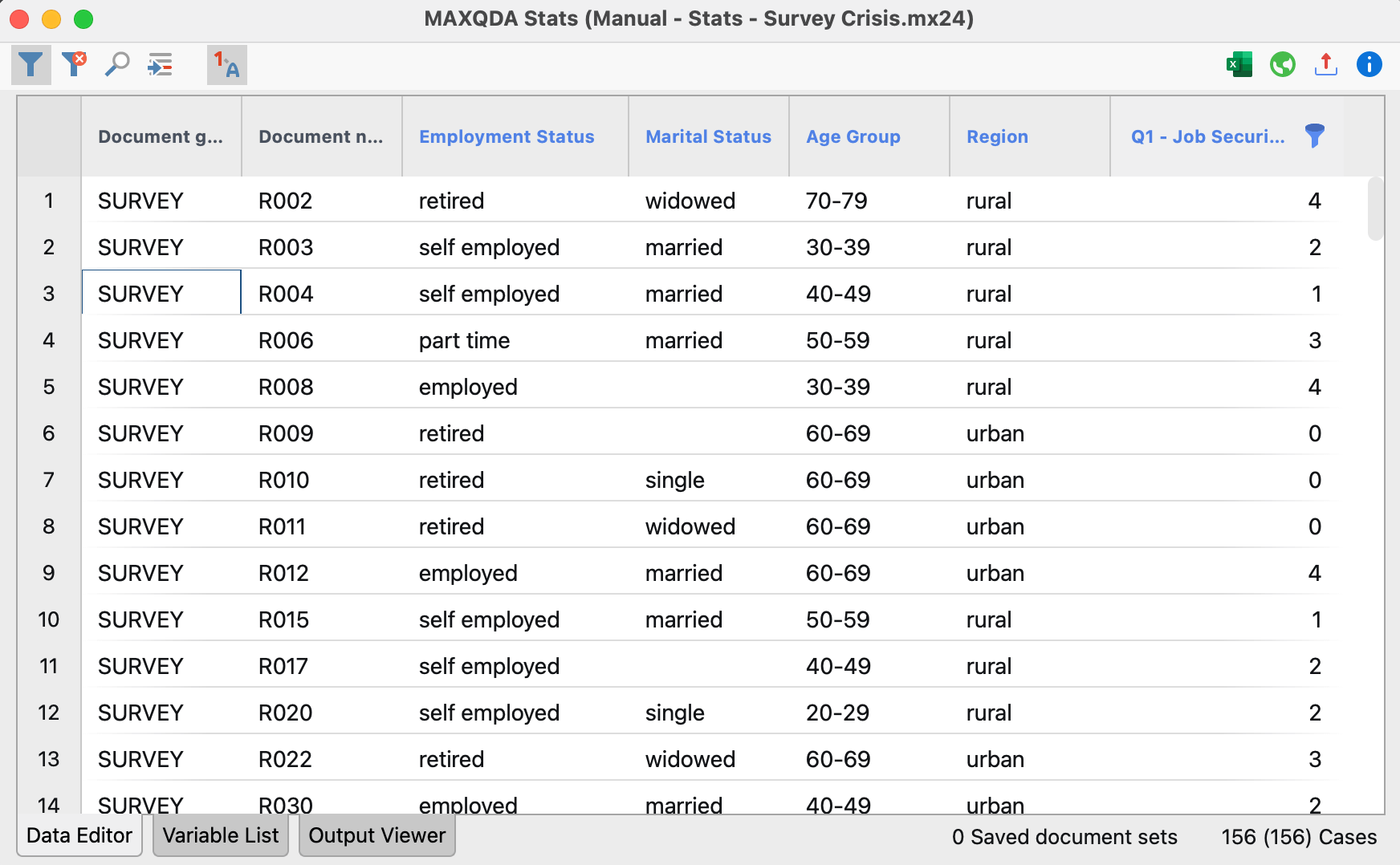
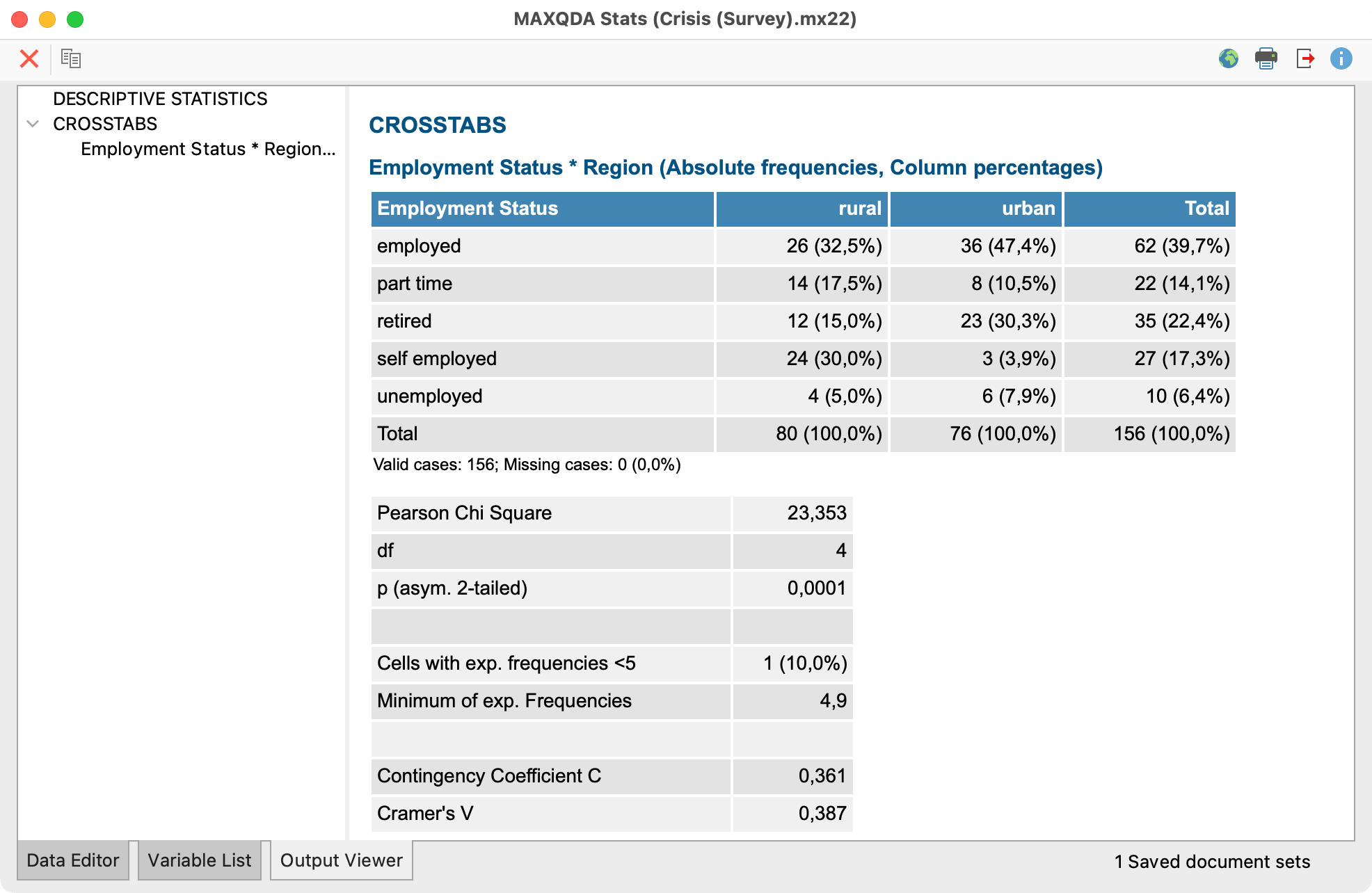
جدول مقایسهای: رگرسیون در مقابل معادلات ساختاری
| جنبه مقایسه | رگرسیون | معادلات ساختاری (SEM) | نرمافزارهای متداول |
|---|---|---|---|
| هدف اصلی | پیشبینی یا تبیین تغییرات | آزمون و تأیید مدلهای نظری کامل | رگرسیون: SPSS, R, Python SEM: Mplus, AMOS, lavaan |
| سطح تحلیل | متغیرهای مشاهدهشده | متغیرهای پنهان و مشاهدهشده | رگرسیون: تحلیل سادهتر SEM: تحلیل چندسطحی |
| نوع متغیرها | متغیرهای مشاهدهشده مستقیم | ترکیب متغیرهای پنهان و مشاهدهشده | رگرسیون: دادههای اولیه SEM: دادههای پیچیده |
| خطای اندازهگیری | نادیده گرفته میشود | مستقیماً برآورد و کنترل میشود | رگرسیون: خطای ساده SEM: خطای پیچیده |
| پیچیدگی روابط | روابط مستقیم و ساده | روابط مستقیم، غیرمستقیم، واسطهای | رگرسیون: مسیرهای خطی SEM: شبکههای علی |
| ارزیابی مدل | R²، معناداری ضرایب | شاخصهای برازش (CFI, RMSEA, TLI) | رگرسیون: معیارهای محدود SEM: معیارهای جامع |
| حجم نمونه مورد نیاز | نسبتاً کوچک | بزرگتر (معمولاً >200) | رگرسیون: انعطاف بیشتر SEM: نیاز نمونه بزرگ |
| پیشنیاز نظری | کمتر ساختاریافته | بسیار ساختاریافته و نظری | رگرسیون: اکتشافی SEM: تأییدی |
راهنمای انتخاب روش: کدام تکنیک برای پژوهش شما مناسبتر است؟
چه زمانی از رگرسیون استفاده کنیم؟
- اهداف ساده دارید: فقط نیاز به پیشبینی یا تبیین روابط ساده دارید.
- متغیرهای مشاهدهشده دارید: همه متغیرهای شما مستقیم قابل اندازهگیری هستند.
- حجم نمونه کوچک است: کمتر از 100 مورد در اختیار دارید.
- در مرحله اکتشافی هستید: پژوهش اولیه و توسعه فرضیهها را انجام میدهید.
- منابع محدودی دارید: زمان و تخصص کافی برای روشهای پیچیدهتر ندارید.
چه زمانی از SEM استفاده کنیم؟
- آزمون نظریه پیچیده دارید: مدلهای نظری چندبعدی را باید آزمون کنید.
- با متغیرهای پنهان سروکار دارید: سازههای نظری مانند هوش، رضایت یا اضطراب را بررسی میکنید.
- روابط پیچیده بررسی میکنید: اثرات مستقیم، غیرمستقیم و واسطهای در مدل وجود دارد.
- نیاز به کنترل خطا دارید: خطای اندازهگیری میتواند نتایج شما را مخدوش کند.
- برازش کلی مدل مهم است: میخواهید بدانید کل مدل پیشنهادی چقدر با دادهها سازگار است.
نرمافزارهای تخصصی هر روش
نرمافزارهای برتر برای تحلیل رگرسیون
- SPSS: بهترین انتخاب برای مبتدیان و تحلیلهای استاندارد
- R: ایدهآل برای متخصصان با نیازهای سفارشی
- Python: مناسب برای پروژههای علم داده یکپارچه
- Stata: گزینهای عالی برای اقتصادسنجی و دادههای پنلی
- SAS: استاندارد صنعتی برای سازمانهای بزرگ
نرمافزارهای حرفهای برای SEM
- Mplus: استاندارد طلایی برای تحلیلهای پیشرفته SEM
- AMOS: بهترین گزینه برای شروع با رابط کاربری گرافیکی
- lavaan (در R): انتخاب ایدهآل برای کاربران R
- SmartPLS: مناسب برای مدلهای پیچیده با حجم نمونه کوچک
- LISREL: اولین و همچنان قدرتمند در تحلیلهای پایه
۷ نکته طلایی برای انتخاب روش آماری مناسب
- سوال پژوهش را مشخص کنید: روش آماری ابزار است، نه هدف. سوال پژوهش روش را تعیین میکند.
- نوع دادهها را بررسی کنید: دادههای شما چه ویژگیهایی دارند؟
- فرضیات روشها را بشناسید: هر روش فرضیات خاص خود را دارد.
- منابع خود را ارزیابی کنید: زمان، بودجه و تخصص شما چقدر است؟
- از مشاوره استفاده کنید: در شک، با یک متخصص آمار مشورت نمایید.
- پایلوت مطالعه انجام دهید: یک آزمون مقدماتی با دادههای کوچک انجام دهید.
- انعطافپذیر باشید: گاهی ترکیبی از روشها بهترین راهحل است.
اشتباهات رایج در انتخاب روش آماری
- استفاده از SEM با حجم نمونه ناکافی
- انتخاب رگرسیون برای دادههایی که نیاز به SEM دارند
- نادیده گرفتن فرضیات روشهای آماری
- تمرکز بیش از حد بر نرمافزار و غفلت از مبانی نظری
- کپیکردن روش سایر پژوهشها بدون درک منطق آن
جمعبندی و سخن پایانی
انتخاب بین رگرسیون و معادلات ساختاری یک تصمیم استراتژیک در طراحی پژوهش است. رگرسیون مانند یک چکش قابل اعتماد برای کارهای ساده است. SEM مانند یک جعبه ابزار جراحی برای کارهای پیچیده و دقیق طراحی شده است.
به یاد داشته باشید: هیچ روشی ذاتاً برتر نیست. بهترین روش، روشی است که بهترین پاسخ را به سوال پژوهش شما بدهد. ترکیب این دو روش نیز در بسیاری از پژوهشهای پیشرفته دیده میشود.
نظر شما چیست؟ آیا در پژوهش خود با چالشی در انتخاب روش آماری مواجه شدهاید؟ چه تجربهای در استفاده از رگرسیون یا SEM دارید؟ دیدگاههای خود را با ما و دیگر خوانندگان در بخش نظرات به اشتراک بگذارید.
خواهشمند است، نظر خودتان را در پایان نوشته در سایت https://rava20.ir مرقوم نمایید. همین نظرات و پیشنهاد های شما باعث پیشرفت سایت می گردد. با تشکر
پیشنهاد می شود مطالب زیر را هم در سایت روا 20 مطالعه نمایید:
پرسشنامه تلفیقی نگرش دانشجویان به يادگيري
پرسشنامه ساختار ادراک شده کلاس درس میگلی و همکاران (1988)
چه تفاوتی بین تحلیل مضمون آتراید استرلینگ و سایر روشهای تحلیل دادههای کیفی وجود دارد؟
در طراحی و تدوین پرسشنامه رعایت چه نکاتی ضروری است.
روش های انتخاب افراد نمونه در پژوهش
آدرسهای مرتبط:
- آدرس وب سایت: https://rava20.ir
- آدرس کانال تلگرام: https://t.me/RAVA2020
- آدرس کانال آموزشی آپارات: https://www.aparat.com/amoozeh20
- آدرس وبلاگ: http://abazizi.parsiblog.com/