...........................................................................................................................................................................................................................................................................................................................................................................
خوش آمدید این سایت دارای مجوز می باشد برای مشاهده مجوز ها پایین صفحه را مشاهده فرمائید.
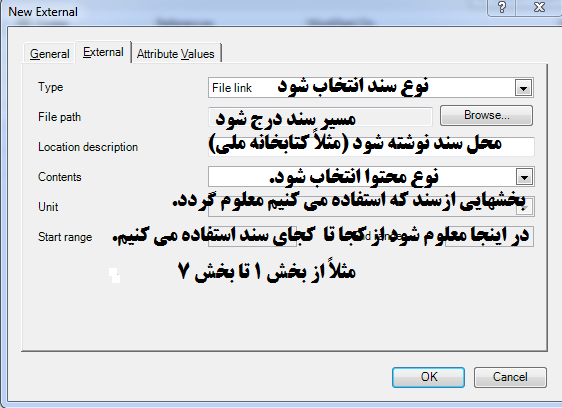
داده های بیرونی ( Externals) اسنادی یا داده هایی هستند که محقق نمی تواند آن ها را وارد نرم افزار کند و فقط می تواند برای آن ها توضیحاتی بنویسد و برای این توضیحات کدگذاری یا حاشیه نویسی کند. مثلاً اگر ما یک کتاب چاپی در اختیار داریم ولی ناشر حق عکس گرفتن، اسکن کردن، pdf گرفتن و … را به ما نمی دهد. یا اگر یک اثر باستانی هست، ولی حق انتشار عکس و… نداریم یا به عنوان مثال فیلم های آنالوگ یا پرونده و … . همچنین فایل هایی که در اختیار داریم ولی نمی توانیم آن ها را وارد نرم افزار کنیم (به عنوان مثال فایل های PowerPoint) برای خلاصه نویسی محتوای منبع ، رونویسی گفتار ، یا نوشتن هر توضیحی که در رابطه با منابع می نویسید ، می توانید از بخش خارجی استفاده کنید. برای دسترسی به این قسمت در نمای هدایتگر ، در زیر بخش دیتا روی Externals راست کلیک کنید و New External را انتخاب کنید. یا اینکه روی Extrnal کلیک کنید و در قسمت خالی نمای لیست راست کلیک کنید و گزینه New External را انتخاب کنید. بعد از انتخاب این گزینه پنجره زیر باز می شود. که در تب عمومی General باید نام و توصیفی برای سند نوشته شود و در تب Externa در قسمت type : نوع سند انتخاب شود . که می تواند یک لینک اینترنتی، یک فایل بر روی رایانه یا یک چیز دیگر باشد. سایر بخش ها را مطابق شکل زیر کامل کنید.پس از تعریف سند، در نمای لیست روی آن دوبار کلیک می کنیم . سپس در نمای جزئیات توضیحات هر فصل را می نویسیم. و در مراحل بعد این توضیحات را مورد تحلیل قرار می دهیم و آن ها را کد گذاری می کنیم.
در آمار از کواریانس و همبستگی برای بررسی ارتباط خطی دو بین دو متغیر و اندازه گیری میزان وابستگی آنها به همدیگر استفاده میکنند! ولی آیا هر دو عین هم هستند؟ خیر!
همبستگی جهت و شدت ارتباط بین دو متغیر را مشخص میکند، در حالی که کواریانس تنها جهت ارتباط بین دو متغیر را مشخص میکند.
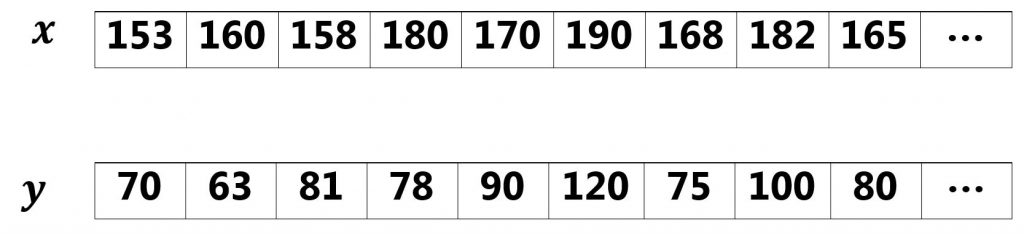
اجازه بدهید با یک مثال ساده این مسئله را بررسی کنیم، فرض کنید که در یک مطالعه ای میخواهید قد افراد در جامعه ایران را بررسی کنید و ببینید قد افراد به چه صورت توزیع شده است. برای اینکار یک تعداد افراد از جامعه را به صورت کاملا تصادفی انتخاب میکنید و قد این افراد را اندازه گیری میکنید. فرض کنید که قد افرادی که بررسی کردید به صورت زیر است.
الان شما یک مجموعهای تک متغیره دارید و اگر بخواهید این مجموعه را از لحاظ آماری بررسی کنید نیاز به محاسبه میانگین و واریانس قد افراد دارید.
میانگین
حد وسط یک داده را مشخص میکند. در این مثال میانگین قد افراد در جامعه را مشخص میکند.
واریانس
میزان تغییرات حول میانگین را مشخص می کند. واریانس کمتر به این معنی است که قد افراد جامعه خیلی شبیه هم هست ولی اگر واریانس زیاد باشد نشان میدهید که قد افراد در جامعه رنج تغییرات زیادی دارد.
خب با همین دو پارامتر میتوانیم به صورت آماری یک مجموعه تک متغیره را بررسی کنیم.
حال بیایید مثال را تغییر بدهیم، فرض کنید که میخواهید ارتباط بین وزن و قد افراد را بررسی کنید. و برای همین منظور تعدادی از افراد جامعه را به صورت کاملا تصادفی انتخاب میکنید، و وزن و قد این افراد را اندازه گیری میکنید .
در این مسئله میخواهیم بدانیم که چه ارتباط خطی بین قد و وزن افراد وجود دارد. برای مثال میخواهیم بدانیم آیا با تغییر قد افراد وزن افراد هم تغییر کرده یا نه. و اگر تغییر کرده این تغییرات به چه شکل بوده است. برای بررسی ارتباط خطی بین دو تا مجموعه تک متغیره از کواریانس و همبستگی استفاده می کنند.
کواریانس
کواریانس دو تا متغیر را میتوان طبق رابطه زیر محاسبه کرد و مقدار بدست آمده یک عددی بین [-∞ :+ ∞] است.
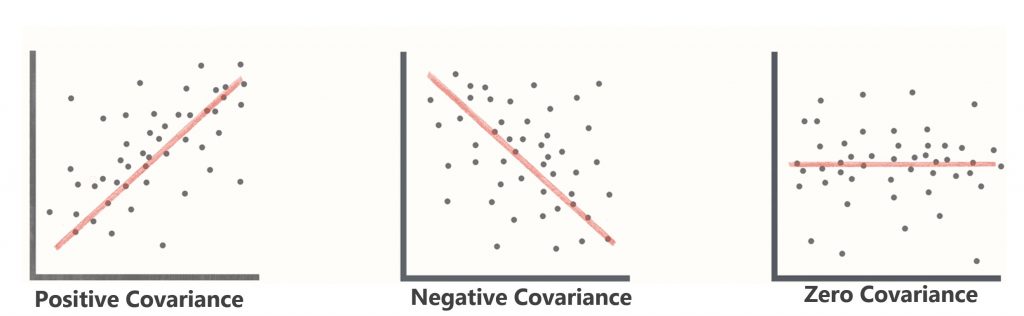
کواریانس تنها جهت(direction) ارتباط بین دو متغیر را مشخص میکند. بعنی مشخص میکند که ارتباط بین دو متغیر مثبت ، منفی و یا صفر است.
اگر کواریانس بین قد و وزن افراد مثبت باشد، یعنی با افزایش قد افراد جامعه، وزنها انها هم افزایش می یابد و یا برعکس با کاهش قد افراد، وزن افراد نیز کاهش می یابد
اگر کواریانس بین قد و وزن افراد منفی باشد، یعنی با افزایش قد افراد جامعه، وزنها افراد کاهش می یابد و یا برعکس با کاهش قد افراد، وزن افراد نیز افزایش می یابد
اگر کواریانس بین قد و وزن افراد صفر باشد، یعنی با افزایش یا کاهش قد افراد جامعه، وزنها انها تغییری نمیکند.
حال فرض کنید کواریانس بین دو تا متغیر شده عدد 15، به نظر شما این عدد چه چیزی را مشخص میکند؟ آیا میتوان گفت ارتباط خطی بین دو متغیر بسیار زیاد هست؟ نه نمیتوان گفت. ما از روی کواریانس بدست آمده تنها جهت ارتباط بین دو متغیر را میتوانیم متوجه شویم، ولی اینکه شدت ارتباط بین دو متغیر چقدر هست را نمیتوان متوجه شد!
همبستگی
همسبتگی همان کواریانس نرمال شده است و طبق رابطه زیر میتوانیم همبتسگی بین دو متغیر را بدست آوریم.
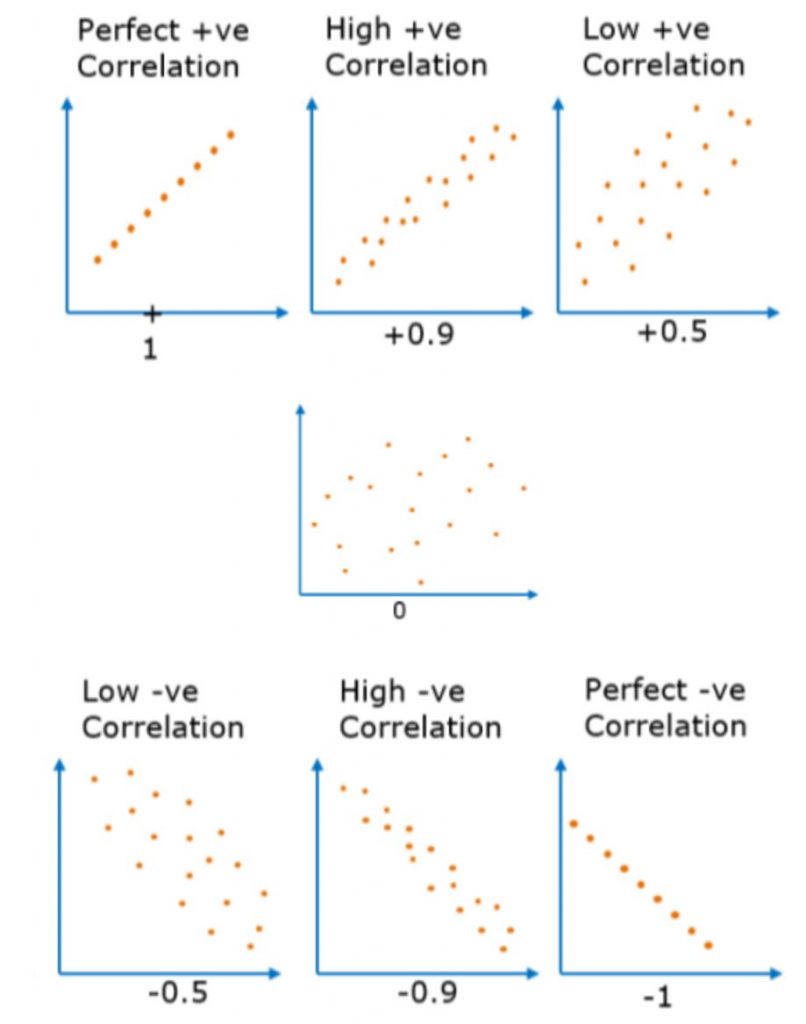
همسبتگی یک عدد بین [-1:+1] هست و جهت(direction) و شدت-میزان (strength) ارتباط خطی بین دو متغیر را مشخص میکند.
هر چقدر همبستگی به عدد +1 نزدیک باشد، به معنی است که بین دو متغیر خطی ارتباط خطی مثبت زیادی وجود دارد. یعنی با افزایش قد افراد، وزن افراد هم افزایش پیدا میکند و برعکس. یک ارتباط مستقیم بین دو متغیر وجود دارد.
هر چقدر همبستگی به عدد -1 نزدیک باشد، به معنی است که بین دو متغیر خطی ارتباط خطی منفی زیادی وجود دارد. یعنی با افزایش قد افراد، وزن افراد کاهش پیدا میکند و برعکس. یک ارتباط عکس بین دو متغیر وجود دارد.
اگر همبستگی دو متغیر نزدیک به عدد 0 باشد معنیش این است که با تغییرات مقدار یک متغیر، تغییر در مقدار متغیر دوم اتفاق نمی افتد!
نسبت به بیشعوری خود تعصب دارند و با توجیه و دلیل تراشی در بیشعوری شان ثابت قدم اند.
6- وقاحت
هرگز در صف نمی ایستند. هرگز خواهش نمی کنند. همواره دستور می دهند. هرگز تحقیق نمی کنند. نیشدار و یا با دادزدن صحبت می کنند. دوست دارند کار دیگران را به اسم خودشان تمام کنند.
7- تسلط بر دیگران
اکثر بیشعوران به دنبال حداکثر بهره کشی از دیگران و تغییر دائم قوانین بر اساس منافع خودشان هستند.
8- عدم شادی و شوخ طبعی
به هیچ وجه ظرفیت ندارند که با آنان شوخی کنید. به دنبال شاد کردن شما هم نیستند. به جای آن، تمسخر کردن، پوزحند زدن و به بدبختی دیگران خندیدن را دوست دارند.
9- انکار
بیشعورها انکار را نوعی هنر می دانند. معتقدند هرگز اشتباه نمی کنند و منکِر تمام مشکلاتی می شوند که آنها به وجود آورده اند.
سعی می کنند با ترساندن و اسارت فکری دیگران، آنان را برده ی خود کنند.
11- عشق صرفا به خود
یک بیشعور صرفا عاشق موقعیت، مقام، ثروت و نظرات خودش است. تنها عاشق خود است و بس.
12- بی معنی بودن فداکاری
در قاموس بیشعور فداکاری معنایی ندارد.
13- در ارتباط با دیگران
عیب جو و به شدت دروغگو هستند.
14- شنونده های خوب
بیشعورها خوب به شما گوش میدهند تا نقاط ضعف شما را شناسایی و در زمان مناسب از آن سوء استفاده کنند.
15- غیر قابل اعتماد بودن
دروغگویی و دسیسه کار آنهاست و هرگز نمیتوان به آنان اعتماد کرد.
16- خشم
بیشعورها پُر از خشم اند. اعتقاد دارند خشم بهترین ابزار برای پیشبرد اهدافشان است. هنگام بیدار شدن، وقتی از آنان طلب وام میکنید یا طلبتان را تقاضا می کنید، هوا بارانی باشد، قهوه شان سرد شود ….در بسیاری از این مواقع خشم خود را نشان می دهند.
17- غُر زدن
در بسیاری از موارد حتی اگر چیزی به نظر همه بدون اشکال و پسندیده باشد، باز غر میزنند.
18- شراکت
فقط شما را در بدبختی و تقصیرهایشان شریک می کنند نه در موفقیت و پول و مقام شان.
۱۹- استهلاک
گذر زمان آنان را خسته و فرسوده می کند و رفته رفته متقاعد می شوند شاید راه بهتری برای ادامه زندگی شان وجود داشته باشد.
گاهی اوقات ممکن است شخصی بخواهد اطلاعات تلفن همراه خود را بداند، اما به اینترنت دسترسی ندارد تا درباره آنها جستجو کند، راههایی وجود دارد که میتوانبدون اینترنت نیز درباره ویژگیهای گوشیهای هوشمند اطلاعات کسب کرد. گاهی از اوقات نیز ممکن است استفاده از برخی عملکردها در تلفن یا دسترسی به برخی از اطلاعات مهم مانند دادههای دستگاه یا ویژگیهای دیگر آن گیج کننده باشد. با این حال، واقعیت این است که تقریباً در همه برندهای اصلی تلفن همراه کدهای مخفی وجود دارد که از طریق آنها میتوان کل دستگاه را کنترل کرد.
یکی از مهمترین موضوعات در دنیای علم و فناوری، دسترسی به منابع علمی معتبر با درجه کیفیت بالا است. با طبقه بندی مقاله ها به انواع گوناگون، هر کدام زبان و مخاطب خود را یافته اند. بنابراین مقاله ها را می توان بر اساس هدف، موضوع، زبان، چگونگی ارسال (نوع نشریه) و مخاطب به انواع گوناگونی طبقه بندی کرد. دلیل این تنوع را می توان در این مهم دانست که اساس ارتباط بین محققان، پژوهشگران، دانشجویان، اساتید ومخاطبان در دنیای علمی امروز، مقاله های علمی است. لذا با توجه به اینکه مجلات علمی، تازه ترین و جدیدترین اطلاعات را درباره زمینه های علمی تخصصی ارائه می دهند، دانشجویان باید با چارچوب یک مقاله علمی آشنا باشند؛ چرا که این آشنایی، آنها را در زمینه های زیر یاری خواهد رساند:
می توانند اطلاعات مختلف ارائه شده در مقاله را بدون مطالعه کل مقاله، شناسایی و استخراج نمایند؛
قادر خواهد بود بخشهای ضروری تر یک مقاله را نسبت به بخشهای کم اهمیت تر تشخیص دهند؛
قادر خواهند بود یک مقاله را از لحاظ سازماندهی و ارایه اطلاعات ارزیابی کنند.
مهم تر این که آشنا بودن با چهارچوب یک مقاله علمی، به دانشجویان کمک خواهد کرد که نتایج پژوهش های خود را در قالب مقالات علمی، گزارش و ارائه نمایند.
انواع مقاله علمی از لحاظ نوع نوشتار
مقاله ی تحقیقی یا مقاله ی پژوهشی
مقالات مروری
کیس ریپورت
مقاله ی تحقیقی یا مقاله ی پژوهشی
رایج ترین نوع مقاله اند که برگرفته از انجام یک تحقیق یا انجام پایان نامه و یا حداقل یک نوآوری منحصر به فرد و بدیع بوده که به صورت رایج در ژورنال ها و کنفرانس ها منتشر می گردد. (برای آشنایی با بهترین ژورنال های جهان مقالاتی که قبلا در سایت ایران مشاور قرار داده شده است را مطالعه فرمایید). ارزش علمی مقاله ی تحقیقی رابطه ی نزدیک و مستقیمی با نوآوری دارد. معمولا غالب پژوهشگران مقاله نویسی را با مقاله تحقیقی آغاز می کنند.
ساختار یک مقاله ی پژوهشی:
عنوان
چکیده
مقدمه
بیان مساله
مبانی نظری(چارچوب)
فرضیه ها یا پرسش
روش شناسی
یافته ها و نتایج
بحث و نتیجه گیری
منابع
مقالات مروری
هدف از نوشتن این مقالات مرور، بررسی، دسته بندی و آسیب شناسی کارهای مشابه قبلی است. نویسنده در این گردآوری، یک فرض و خط علمی معین و نظریه خاص را دنبال می کند. اساسا در این نوع مقالات، نویسنده باید تسلط کامل به موضوع داشته و چند مقاله پژوهشی در مورد موضوع مقالات مرور شده را منتشر نماید. در نوشتن این مقالات بایستی چند نکته را در نظر داشت.
چنانچه مرور مشابهی در سال های اخیر انجام شده، انجام مرور مجدد شاید چندان جالب و علمی نباشد.
تعداد مقالات مرور شده، عدد مشخصی ندارد، اما حداقل باید حدود ۵۰ عنوان مقاله معتبر باشد. (تعداد کلمات در این نوع مقالات می تواند تا ۵۰۰۰ کلمه باشد).
این مقالات نیاری به پیشنهاد اصلی و نوآوری علمی ندارند، بلکه نیاز به نوآوری نوشتاری و برجسته سازی مفاهیم مطرح شده در متون مرور شده دارند.
معمولا نگارش چنین مقالاتی توسط ژورنال ها، از نویسندگان و پژوهشگرانی که در یک زمینه خاص تعداد قابل ملاحظه ای مقاله معتبر منتشر کرده اند، درخواست میشود. توضیحات کامل تر این نوع مقالات را در بخش مقاله مروری مطالعه فرمایید.
مقاله های مروری به دو دسته تقسیم می شوند:
استدلالی- انتقادی
فراتحلیلی
مقاله های مروری استدلالی-انتقادی
در این نوع مقالات که گاهی به آن ها مقاله های غیرنظامند (Non-systematic) و یا مرور روایتی (Narrative review) نیز گفته می شود، نویسنده یا نویسندگان مساله یا پرسش هایی را طرح می کنند و با یک روش کتابخانه ای یا اسنادی به جستجو و کنکاش ادبیات مربوط می پردازند و آنگاه با تلفیق و جمع بندی داده ها و اطلاعات بدست آمده و استدلال های خود به نتیجه گیری می رسند. بنابراین در این نوع مقاله، آنچه که مهم به نظر می آید طرح مساله، بیان حکم و رسیدن به نتایج مستدل بر اساس یک روش مطالعاتی نظاممند است. این نوع مقاله ها بر اساس هدفشان می توانند به دو صورت نوشته شوند
مروری نظری
مروری انتقادی
مقاله های مروری نظری
در این نوع مقاله های نویسنده یک موضوع نظری را طرح می نماید. پس از طرح مسئله اصلی، حکم خود را ذکر می کند و آنگاه روش شناسی و یا روش مطالعه خود را بیان می دارد. سپس مفهوم های خود را تعریف نموده و در راستای کار خود مبانی نظری را مرور می نماید و آنگاه بر اساس مبانی نظری و استدلال های خود به بحث و نتیجه گیری می پردازد و در پایان نیز منابع خود را ذکر می کند.
ساختار یک مقاله ی مروری نظری:
عنوان
چکیده
مقدمه
بیان مسئله
حکم
تعریف مفهوم ها
روش شناسی
مبانی نظری
نتیجه گیری از مبانی نظری
بحث و نتیجه گیری
منابع
مقاله های مروری انتقادی
در این نوع مقالات، نویسنده یک رویکرد ارزیابانه و انتقادی به یک منبع خاص و یا شرایط و … اتخاذ می کند. بسیاری بر این باورند که نقد به معنی مخالفت با دیدگاه های طرف مقابل است. در حالیکه نقد می تواند مثبت، منفی، و یا متضمن وجود هر دو ویژگی-مثبت و منفی- باشد. پس آنچه که در نقد نویسی و به ویژه مقاله های انتقادی اهمیت دارد سوگیری استدلالی منتقد یا نقدنویس است که در قالب حکم مطرح می گردد.
در مقاله ی مروری انتقادی، در ابتدا نویسنده با یک مطالعه ی نظاممند واقعیت ها، نکته ها، یا عقاید اصلی منبع مورد نقد را شناسایی و درک می کند و آنگاه مقاله آغاز می گردد. در این نوع مقاله آنچه که معمولا در مقدمه لحاظ می گردد این است که منبع مورد نقد در آن به صورت کامل معرفی می گردد و آنگاه هدف مطالعه مطرح می شود. قضاوت درمورد موضوع، منبع، شرایط، و مساله ی مورد نقد به صورت حکمی نوشته می شود و بعد از هدف ها آورده میشود. آنگاه روش مطالعه یا رویکرد مطالعاتی مطرح و بعد پیکره ی اصلی نقد که شامل خلاصه منابع، وضعیت، شرایط یا مساله و نیز مرور موضوع بر حسب قضاوت است نوشته می شود و در پایان بر اساس حکم و پیکره ی نقد نتیجه گیری نهایی مطرح میشود و منابع ذکر می گردد.
ساختار مقاله مروری انتقادی:
عنوان
چکیده
مقدمه
حکم
روش یا رویکرد مطالعاتی
پیکره ی نقد
نتیجه گیری
منابع
مقاله ی مروری فراتحلیلی
فراتحلیل نوعی تحلیل داده ها است که در آن نتایج چند مطالعه با هم جمع می گردند و به عنوان یک مطالعه ی بزرگ و جامع تر مورد تجزیه و تحلیل قرار می گیرند. همان گونه که مشخص است، در فراتحلیل ما با نتایج و یافته های چند منبع سروکار داریم که با هم ترکیب می شوند. بنابراین، در مقاله های مروری فراتحلیلی می بایست به این منابع و نحوه ی ترکیب آن پرداخته شود. در عین حال، در فراتحلیل می بایست مقیاس های مختلف منابع گوناگون به یک مقیاس واحد تبدیل شوند. پس لازم است نحوه این تبدیل نیز مدنظر قرار گیرد. در بخش یافته ها و نتایج نیز ابتدا باید یافته ها و نتایج این مطالعه ها در قالب جدول های قابل کنترل و دقیق گزارش شوند و آنگاه یافته های تبدیل شده مطرح گردند. و سپس نتیجه گیری بیان شود و معنی داری واقعی را با کمک ادبیات پژوهش و استدلال های منطقی مطرح شود.
به طور کلی ساختار یک مقاله ی مروری فراتحلیلی به این گونه است که ابتدا نویسنده مقدمه ای را در مورد مطالعه ی خود مطرح و بعد مساله ی خود را طرح می نماید. آنگاه هدف های مطالعاتی یا پژوهشی خود را ذکر می کند و مفهوم های خود را تعریف می نماید. بعد از تعریف ها می بایست روش شناسی یا روش مطالعاتی مطرح شود که در این بخش نویسنده به ویژه بر نحوه ی تبدیل رویه های آماری گوناگون به یک رویه ی واحد و یکسان سازی تاکید می نماید. در بخش بعد، منابع مورد بررسی در فراتحلیل معرفی می گردند و به ویژه روش شناسی این منابع ذکر می گردد.
پس از معرفی منابع، نتایج حاصل از این منابع در قالب جدول های مرتب شده و قابل کنترل گزارش می شود و آنگاه نتایج فراتحلیلی ارائه و تفسیر آماری صورت می گیرد. پس از بخش یافته ها و نتایج، نویسنده اقدام به تفسیر نتایج فراتحلیلی خود با کمک ادبیات پژوهش می کند و معنی داری واقعی را بیان می دارد و راهکارها و راهبرد ها را نیز ارائه می دهد. در پایان منابع به کار رفته در مقاله ذکر می شود.
اجزا و ترتیب قرار گرفتن در یک مقاله مروری فرا تحلیل:
عنوان
چکیده
مقاله
بیان مساله
بیان هدف(ها)
تعریف مفهوم ها
روش شناسی با تاکید بر راهبرد ترکیب و یکسان سازی
معرفی منابع فراتحلیلی
یافته ها و نتایج
نتیجه گیری
منابع
کیس ریپورت
مقاله ای حاصل از یافته های بسیار مهم از تحقیق انجام شده که ایرادات وارد شده به یک اصلاثبات شده یا سیاست کلان را در بر می گیرد. چنین مقالاتی دارای ارزش علمی بالایی بوده و معمولا نویسندگان آن، افراد مشهور و معتبری هستند و ژورنال ها رسیدگی به این نوع مقالات را در اولویت خود قرار می دهد.
خود پنداره به عنوان یکی از ویژگی های شخصیتی انسان، کیفیتی منحصر به نوع آدمی است . در تمدن های باستان دراین باره نظرات و مطالب گسترده ای مطرح شده است. خود پنداره آموختنی است و این موضوع هم برای فرد و هم برای کسانی که مسئول پرورش او در کودکی هستند دارای اهمیت فراوانی می باشد. هیچ فردی با خود پنداره به دنیا نمی آید بلکه خود پنداره به تدریج ظهور و بروز می یابد و درعین حال دارای فرایندی پویا و ساختارمند می باشد .این فرایند از عوامل متعددی تأثیر می پذیرد که از مهمترین این عوامل می توان به رابطه با دیگران اشاره کرد(مصطفی باش و شاکردولق،1398).
این مقیاس جهت سنجش میزان خود پنداره کودکان و نوجوانان طرح ریزی شده است و در جهت نگرش احساس فرد نسبت به خودش خلاصه می شود. این مقیاس جهت کمک به تفسیرهای کلینیکی، شش دسته مقیاس را شامل می شود که عبارتند از رفتار؛ وضعیت مدرسه و وضعیت شناختی و ذهنی؛ ظاهر و ویژگیهای فیزیکی؛ اضطراب؛ محبوبیت؛ شادی و رضایت مندی. تمام خوشه ها در جهت خود پنداره مثبت، نمره گذاری میشوند؛ به طوریکه نمره بالا در مقیاس کل و هرکدام از خوشه ها نشان دهنده سطح بالای خود پنداره است . این پرسشنامه شامل 80 سؤال است. سؤالات این مقیاس هم در جهت مثبت و هم در جهت منفی و در بعد خود سنجی نمره گذاری شده است. نمره بالا در این مقیاس نشان دهنده خود سنجی مثبت و نمره پایین نشان دهنده خود سنجی منفی است. هر عبارت پرسشنامه به صورت دو بخشی بلی یا خیر طرح ریزی شده است.
همراه 2 مقاله رایگان
برای مشاهده لیست همه ی پرسشنامه های استاندارد لطفا همین جا روی پرسشنامه استانداردکلیک فرمایید.
تحلیل داده های آماری برای پایان نامه و مقاله نویسی تحلیل داده های آماری شما با نرم افزارهای کمی و کیفی ،مناسب ترین قیمت و کیفیت عالی انجام می گیرد.
استفاده از نرم افزار های رایانه ای در تحلیل داده های پژوهشی، پدیده ای رو به رشد است.ساده ترین تعریف پژوهش های کیفی ، پژوهش هایی است که ارائه یافته های آن از طریق روش های آماری و یا سایر ابزار های کمی ساز به دست نیامده باشد. اﻣﺮوزه اﺳﺘﻔﺎده از فناوری های نو به ویژه نرم افزار های مختلف رایانه ای در پژوهش، به منظور تسریع و تسهیل امور گوناگون امری اجتناب ناپذیر است.متخصصان نرم افزار های تحلیل داده های کیفی را گاه نرم افزار های مهندسی تحقیق می نامند چرا که انواع مسائل و مشکلات موجود در جریان تحقیق را حل می کنند. در این مطلب به معرفی نرم افزار های کیفی و کاربردی ترین نرم افزارهای انجام تجزیه و تحلیل آماری و آزمون فرضیات تحقیق که در همه جای دنیا توسط پژوهشگران و دانشجویان استفاده می شود، می پردازیم.
تفاوتهای نرم افزار های تحلیل داده های کمی و کیفی
نرم افزار های تحلیل داده های کیفی متفاوت از نرم افزار های کمی مانند ,SAS, SPSS, MATLA و… هستند و اصول و قواعد یکسانی پیروی نمی کنند.زمانی که داده های خام وارد یک نرم افزار تحلیل داده های کمی می شوند.تمامی فرایند تحلیل، تعرف شده و بر اساس اصول و قواعد ریاضی و آماری و به عبارت دیگر از پیش تعیین شده صورت می پذیرد.نرم افزار های تحلیل داده های کیفی فرایند تحلیل را پس از ورود اطلاعات توسط محقق منحصرا خودشان انجام نمی دهند. این نرم افزار ها می توانند بطور سیستماتیک و منطقی به جستجو و سازماندهی داده ها و اطلاعات بپردازند و بر اساس الگوریتم های موجود تنها به برجسته نمودن برخی اطلاعات مبادرت(با پتانسیل و اهمیت بیشتر) نمایند. ماکسول بیان می کند که پژوهش کیفی بیشتر بر کلمات تاکید دارد تا اعداد.
نرم افزار های کیفی تمام پروسه تحقیق را به صورت الکترونیکی در اختیار پژوهشگر قرار می دهد به عبارت دیگر نرم افزار های تحلیل کیفی به صورت بالقوه باعث تسهیل انجام کلیت پژوهش از سوی محقق میشود درحالی که نرم افزار های تحلیل کمی، داده های وارد شده را طی فرایند کاملا تعریف شدخ به نتایج نهایی مبدل می سازد.
تفاوتهای بین تحقیق کمی و کیفی:
کمی
کیفی
آزمون فرضیاتی که محقق با آنها شروع به تحقیق میکند.
تسخیر و کشف معنای دادهها هنگامی که محقق در آنها غوطه ور شده است.
مفاهیم به شکل متغیرهای متمایز و مشخص از همدیگرند.
مفاهیم به صورت تمها، مضامین و مشترکات با معنا هستند.
سنجهها به صور منظم قبل از گردآوری دادهها ساخته و استاندارد میشوند.
سنجهها در حالت کلی ساخته میشوند و غالباً نسبت به محیط تحقیق خاص ویژه هستند.
دادهها به شکل اعداد و برگرفته از سنجش و اندازهگیری دقیق هستند.
دادهها به شکل کلمات و برگرفته از اسناد، مشاهدات ودست نوشتهها هستند.
نظریه اساساً علی و قیاسی است.
نظریه میتواند علی و غیر علی باشد که غالباً استقرائی است.
فرآیندهای تحقیق استاندارد است و تکرار آن مسلم فرض میشود.
فرایندهای تحقیق خاص هستند و تکرار آن بسیار نادر است.
تحلیل با به کارگیری آمارها، جداول یا نمودارها انجام میشود و این موارد با فرضیات مرتبط میشود.
تحلیل با استنباط تم ها با مشترکات با معنا و گرفته از شواهد به سازماندهی آنها برای ارایه یک تصویر منسجم و با معنا از واقعیت ادامه مییابد.
نرم افزار اطلس AtlasTi
از نرم افزار اطلس تی جهت کار با داده ها در نظریه مبنایی استفاده می شود. ابزاری در جهت توسعه نرم افزاری علم است، که به روش هایی خلاقانه، منعطف و در عین حال سیستمیک؛ ابزارهایی را، برای مدیریت، استخراج، مقایسه، کشف، و بازسازی دوباره بخش های معنی دار انبوه داده ها، ارائه می کند.
این نرم افزار مجموعه ای است از تعداد ۱۰۶۷ دیاگرام فازی فلزی دوتایی و ۳۰۰ دیاگرام فازی سه تایی که از کتاب ASM Metals Handbook Vol. 3 تهیه شده است و امکانات استخراج داده از دیاگرام های فازی و محاسبات درصد جرمی و حجمی فازها ،محاسبه ضریب توزیع در سیستم های انجماد دوتایی در آن موجود است. بعلاوه می توان داده های نرم افزار را به صفحه گسترده Excel نیز export کرد.
اصول اصلی فلسفه Atlas-ti عبارتند از؛ تجسمVisualization، یکپارچه سازی Integration، قلاب اندازیSerendipity و اکتشاف Exploration، که با نام اختصاری (VISE ) ذکر می شوند . این نرم افزار ابزارهای متنوعی را، برای ایفای وظایف مربوط به نوعی رویکرد نظاممند به داده های بی ساخت، ارائه می کند. برای مثال: داده هایی که نمی توانند بطورکاملاً معنادار توسط رویکردهای آماری و رسمی تحلیل شوند.
Atlas-ti محیط کاری قدرتمندی برای تجزیه و تحلیل های کیفی بخصوص گروه های بزرگی از داده های متنی، گرافیکی، صوتی و ویدویی است. تاکید آن بجای تحلیل های کمی بر تحلیل های کیفی است. یعنی تعیین عناصری که داده های اولیه را شامل شده وتفسیر معنی آنها. در ضمن تجزیه تحلیل کیفی، Atlas-ti به کشف پدیده های پیچیده در پشت داده های بی ساخت کمک می کند.
محاسباتی که توسط این محصول انجام می شود:
۱- محاسبات قانون اهرم را در ناحیه دو فازی مشخص انجام داد.
۲- محاسبه درصد وزنی و حجمی فازهاو چگالی نظری فازهاورسم آن.
۳- همچنین چگالی و درصدحجمی فازها رامی توان بدست آوردو تمام داده ها به صورت لیست به نرم افزار Excelصادر نمود.
۴- بوسیله داده برداری و انجام محاسبه،تغییرات چگالی آلیاژ بر حسب ترکیب شیمیایی آن بدست می آید.
۵- این نرم افزارابزارهای کارآمدی را بوسیله رابط گرافیکی مناسب و به آسانی در اختیار می گذارد.
۶- با استفاده از داده برداری از خطوط solidus و Liquidus می توان مقدار میانگین ضریب توزیع را در یک بازه دمایی مشخص در یک سیستم دوتایی محاسبه کرد.
۷- رسم تغییرات ضریب توزیع نسبت به دمابرای هر سیستم دوتایی دلخواه که توسط درون یابی و میانگین گیری می توان مقدار آن را در یک بازه خاص مشخص کرد.
ان ویوو NVivo
این نرمافزار جهت تجزیهوتحلیل دادههای کیفی به کار میرود. درواقع نرمافزار NVivo برای محققین کیفی طراحیشده که کارشان مبتنی بر متون بسیار غنی یا اطلاعات چندرسانهای است که سطوح عمیق تجزیهوتحلیل در حجم کوچک یا بزرگی از دادهها را میطلبد.
طبقهبندی، مرتب کردن و ساماندهی اطلاعات، بررسی رابطه دادهها و راهنمایی تجزیهوتحلیل آنها را میتوان از امکانات این نرمافزار بهحساب آورد. علاوه بر این به محقق اجازه میدهد که تئوریهای پژوهش خود را بیازماید و روند دادهها را شناسایی کند.
NVivo دادهها در قالبهای مختلفی ازجمله فایل های صوتی، فیلمها، تصاویر دیجیتالی، Word، PDF، excel، متنهای غنی، ساده، وبسایت و دادههای رسانههای اجتماعی (فیس بوک، تویتر، یوتیوب) را پشتیبانی میکند. میتوان دادهها را از برنامههای کاربردی نظیر word، Excel، Spss Statistics، Surveymonkey ، EndNote، OneNote و Evernote وارد کرد.
مکس کیو دی ای MAXQDA
نرمافزار MAXQDA (Qualitative Data Analysis) نرمافزاری حرفه ای برای تجزیهوتحلیل دادههای گردآوری شده توسط روش های کیفی و ترکیبی است. این نرمافزار محدود به یک رویکرد پژوهشی یا روشی نیست. درتحلیل دادههای بدست آمده از مصاحبه، گروه های متمرکز، تحلیل گفت و گو، گفتمان و ژانر، تحلیل روایت و تمام فعالیت هایی که به نوعی با متن سروکار دارند میتوان از این برنامه استفاده کرد. سازماندهی، ارزیابی، کدگذاری، حاشیه نویسی و تفسیر انواع دادهها، دستیابی آسان به گزارشات و تصاویر و اتصال و اشتراک گذاری با پژوهشگران دیگر ازجمله قابلیت های این نرمافزار است.
به منظور مشخص کردن تفاوت معنی دار بین دو یا چند سطح متغیر می توان از آزمون تحلیل واریانس یا (ANOVA) و مانوا (MANOVA) استفاده کرد. یعنی برای مقایسه میانگین اثرات یک یا چند متغیر مستقل بر روی یک متغیر وابسته براساس طرح های آزمایشی مختلف، روش های آماری متعددی مانند آزمون t و آزمون تحلیل واریانس تک متغیری ANOVA بکار گرفته می شود. اما در حالتی که بیش از یک متغیر وابسته مد نظر قرار دارد، با توجه به وابستگی بین متغیرهای وابسته از روش های تحلیل چند متغیره استفاده می شود.
در روش MANOVA ماتریس حاصلضرب برداری کل(T) به دو گروه ماتریس حاصلضرب برداری بین گروه ها (B) و ماتریس حاصلضرب برداری درون گروه ها (W) تفکیک می شود:
T =B + W
Tمیزان انحراف نمونه ها از میانگین را در هر سطح متغیر مستقل یا گروه از میانگین کل هر متغیر وابسته را نشان می دهد. ماتریس B اثرات متفاوت تدابیر آزمایشی را روی مجموعه متغیرهای وابسته نشان می دهد. در نهایت W نشان می دهد که نمونه ها در هر سطح یا گروه متغیر مستقل چگونه از میانگین های متغیرهای وابسته منحرف می شوند.
چهار آزمون آماری متعارف در این زمینه وجود دارد : اثر پیلایی، لامبدای ویلکز، اثر هتلینگ و روش بزرگترین ریشه دوم. پرکاربردترین این آماره ها لامبدای ویلکز می باشد؛ که براساس نسبت Wبر B+W ساخته می شود. در عمل اگر اثر متغیر مستقل بر متغیرهای وابسته از نظر آماری معنادار باشد، یعنی اگر تدابیر آزمایشی اثرگذار باشند، در اینصورت مقدار B نسبتا بزرگ و W کوچک خواهد بود.
در طرح تحلیل واریانس چند متغیری دو یا چند متغیر وابسته پیوسته با یک یا چند متغیر مستقل مقوله ای ارزیابی می شوند. اگر همبستگی بین متغیرهای وابسته وجود نداشته باشد. موقعیت ایده آل برای استفاده از تحلیل واریانس چند متغیری زمانی است که متغیرهای وابسته دارای همبستگی متوسط باشند. در شرایطی که متغیرهای وابسته دارای همبستگی بسیار بالایی هستند نیز نباید از MANOVA استفاده شود. از نظر آماری اینگونه همبستگی ها خطر هم خطی چندگانه را افزایش می دهد. از لحاظ مفهومی متغیرهایی که دارای همبستگی بالایی هستند، ممکن است سازه ی یکسانی را اندازه گیری کنند و بنابراین در مطالعه به عنوان متغیرهای زائد تلقی شوند.
مفروضه ها و محدودیت های آماری در تحلیل واریانس چند متغیری
نرمال بودن چند متغیری: یکی از شرایط استفاده از تحلیل واریانس واریانس چند متغیری نرمال بودن چند متغیری متغیرهای وابسته می باشد. در صورت عدم برقراری این فرض از روش های مختلف تبدیل داده ها مختلف استفاده می شود.
استقلال: شرکت کننده گان در تحقیق باید مستقل از یکدیگر باشند، به لحاظ آزمایشی می توان گفت اگر شرکت کنندگان به صورت تصادفی انتخاب شوند، فرض استقلال برقرار می شود.
مقادیر پرت و گمشده: روش تحلیل واریانس چند متغیری به مقادیر پرت یا کرانه های متغیرهای وابسته بسیار حساس است. خارج نکردن مقادیر پرت از تحلیل و یا تبدیل نکردن این داده ها می تواند میزان خطای نوع اول و دوم را افزایش دهد.
همگنی ماتریس های واریانس-کواریانس: روش استاندارد برای ارزیابی برابری ماتریس های کواریانس آزمونت M باکس است، که در آن معناداری آماری شاخص ناهمگنی یا نابرابری محسوب می شود. از جمله روش های اصلاح نقض این مفروضه ها تبدیل متغیرهای وابسته است.
خطی بودن: فرض بر آن است که بین جفت متغیرهای وابسته روابط خطی برقرار است. در صورت مشاهده روابط غیرخطی می توان از تبدیل های مناسب استفاده نمود.
تحلیل رگرسیون زمانی استفاده می شود که بخواهیم مقادیر یک متغیر را از روی مقادیر متغیر دیگر پیش بینی کنیم. در این مورد، متغیری که ما از بهره می گیریم تا مقدار متغیر دیگر را پیش بینی کنیم، متغیر مستقل (یا پیش بین) نام دارد. متغیری را هم که می خواهیم پیش بینی کنیم متغیر وابسته (یا ملاک) نام دارد .دو نوع عمده تحلیل رگرسیون خطی داریم. رگرسیون خطی تک متغیره برای پیش بینی یک متغیر وابسته توسط یک متغیر مستقل و رگرسیون خطی چند متغیره برای پیش بینی یک متغیر وابسته توسط چند متغیر مستقل.
روش های رگرسیون خطی شامل پنج روش می باشد، این پنج نوع تحلیل رگرسیون خطی در SPSS شامل روش ورود یا همزمان، روش گام به گام، روش حذف، روش پیش رونده و روش پس رونده است.
روش ورود یا همزمان: در روش ورود یا همزمان کلیه متغیرهای مستقل به صورت همزمان وارد مدل میشوند تا تاثیر همه متغیرهای مهم و غیر مهم بر متغیر وابسته مشخص شود.
روش گام به گام: متغیرهای مستقل یک به یک و به ترتیب اهمیت و داشتن بیشترین رابطه وارد مدل میشوند. یعنی ورود متغیرها یک به یک صورت میگیرد.
نکته: اگر تعداد متغیرهای شما زیاد است و برخی از متغیرها مهمتر از برخی دیگر هستند، بهتر است از تحلیل رگرسیون خطی به سبک گام به گام استفاده کنید، در غیر اینصورت از تحلیل به سبک ورود یا همزمان استفاده کنید.
مفروضات
-متغیر ها در سطح سنجش فاصله ای -توزیع متغیرهای نرمال یا نزدیک به نرمال باشند. – بین دو متغیر رابطه خطی وجود داشته باشد. جهت سنجش نرمال بودن توزیع متغیر ها از آزمون Shapiro-Wilk و یا Kolmogoro-smirnov استفاده می کنیم. جهت سنجش وجود رابطه خطی بین دو متغیر نیز از آزمون همبستگی پیرسون استفاده می کنیم.
نحوه اجرای مدل:
برای مثال اگر ما بخواهیم رابطه بین ارتفاع از سطح زمین و دما را بررسی کنیم. می توانیم از تحلیل رگرسیون خطی استفاده کنیم.
برای اجرای ابتدا این مسیر را دنبال میکنیم
Analyze › Regression › Linear
حالا شما کادر زیر را مشاهده می کنید: متغیر مستقل (پیش بین) یا همان درآمد را به داخل کادر Independent انتقال می دهیم. متغیر وابسته یا همان قیمت خودرو را وارد کادر Dependent می کنیم. روش (Method) اجرای رگرسیون را نیز مطابق پیش فرض رگرسیون، یعنی همان (Enter) انتخاب می کنیم.
خروجی مربوط به رگرسیون خطی:
جدول بعدی ANOVA نام دارد. این جدول نشان می دهد که آیا مدل رگرسیون می تواند به طور معنا داری (و مناسبی) تغییرات متغیر وابسته را پیش بینی کند. برای بررسی معنا داری به ستون آخر جدول (sig) نگاه می کنیم. این ستون معنا داری آماری مدل رگرسیون را نشان می دهد که چنان چه میزان به دست آمده کمتر از ۰٫۰۵ باشد نتیجه می گیریم که مدل به کار رفته است. میزان معنا داری در مثال ما کمتر از میزان ۰٫۰۵ است که بیان گر این است که مدل رگرسیونی معنا دار است.
جدول زیر Coefficients، اطلاعاتی را در مورد متغیر های پیش بین به ما می دهد. این جدول اطلاعات ضروری برای پیش بین متغیر وابسته را در اختیار ما قرار می دهد. مشاهده می کنیم که مقدار ثابت (constant) و متغیر درآمد هر دو در مدل معنا دار شده اند (به ستون sig) نگاه می کنیم. پس از تعیین معنا دار بودن مقدار ثابت و متغیر درآمد، ستون Standardized Coefficients بیانگر ضریب رگرسیونی استاندارد شده یا مقدار بتا است. ضریب رگرسیونی استاندارد شده یا Beta در مثال ما برابر شده است با ۸۷۳٫ که نشان گر میزان تاثیر متغیر مستقل بر وابسته است. نکته: میزان Beta زمانی که یک متغیر مستقل در مدل داریم، با میزان همبستگی پیرسون بین دو متغیر (R) دقیقا برابر است. اما زمانی که بیش از یک متغیر مستقل داشته باشیم، میزان Beta با ضریب همبستگی بین متغیر های مستقل و وابسته تفاوت خواهد داشت.
نکته: کاربرد ضریب Beta هنگامی است که بیش تر از یک متغیر مستقل در مدل داشته باشیم. در این صورت مقدار Beta به ما کمک می کند که سهم نسبی هر متغیر را در پیش بینی متغیر وابسته مقایسه کنیم و به عبارتی بتوانیم تعیین کنیم که کدام متغیر ها بیش ترین تاثیر را بر متغیر وابسته دارند.
جهت ایجاد معادله رگرسیونی از میزان ضریب رگرسیونی استاندارد نشده (B) استفاده می کنیم. معادله رگرسیونی جهت پیش بینی دقیق مقادیر متغیر وابسته مورد استفاده قرار می گیرد و معادله آن به صورت زیر است: Y = a + bx Y= مقدار پیش بینی شده ی متغیر وابسته a= عرض از مبدأ نقطه تقاطع خط رگرسیون با محور Y (در جدول: مقدار ثابت یا constant) b= شیب خط (ضریب رگرسیونی استاندارد نشده یا B) X= مقادیر مختلف متغیر مستقل معادله رگرسیونی اجرا شده: Y = 8287 + 0.564 X
نرم افزار ان ویوو یک بسته نرم افزاری تجزیه و تحلیل داده های کیفی (QDA) است که توسط موسسه بین المللی QSR طراحی و عرضه شده است. این نرم افزار برای انجام تحلیل های کیفی طراحی شده که با حجم زیادی از اطلاعات و منابع چند رسانه ای کار می کند و از طریق آن امکان انجام تحلیل های بسیار قوی بر روی داده هایی با حجم کم یا زیاد وجود دارد. با اطمینان می توان گفت ان یوو یه نرم افزار تخصصی برای پروژه های کیفی می باشد ، به عبارت دیگر برای تجزیه تحلیل متون در تحقیقات کیفی بکار می رود، بطور مثال پاسخ های تشریحی یک پرسشنامه. نرم افزار NVivo با مجموعه متنوعی از روش های تحقیق شامل تجزیه و تحلیل سازمانی و شبکه، مطالعات کاربردی یا مبتنی بر شواهد، تحلیل سخنرانی، تئوری های پایه، تحلیل مصاحبه، قوم نگاری، بررسی ادبیات تحقیق، پدیده شناسی، روش های ترکیبی تحقیق و متدولوژی چارچوب سازگار است. این نرم افزار از قالب های مختلف داده همچون فایل های صوتی، ویدئویی، عکس های دیجیتال، فایل های متنی، PDF، کاربرگ ها، متن های غنی، متن رمزگذاری نشده و ساده و نیز داده های مربوط به وب و شبکه های اجتماعی استفاده می کند.
ما در این سایت پرسشنامه های استاندارد (دارای روایی، پایایی، روش دقیق نمره گذاری ، منبع داخل و پایان متن ) ارائه می کنیم و همچنین تحلیل آماری کمی و کیفی رابا قیمت بسیار مناسب و کیفیت عالی و تجربه بیش از 17 سال انجام می دهیم. برای تماس به ما به شماره 09143444846 در شبکه های اجتماعی پیام بفرستید. ایمیلabazizi1392@gmail.com
تمامی حقوق مادی و معنوی این سایت متعلق به لنسرسرا و محفوظ است.
این سایت دارای مجوز می باشد




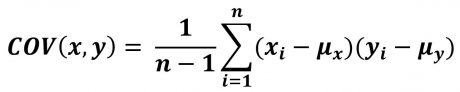
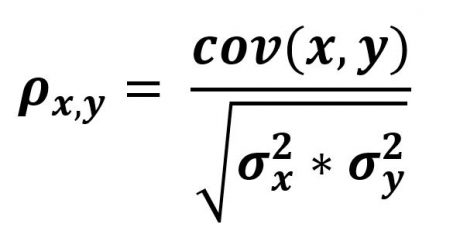


_1593213017270_1606035618465.jpg "سامسونگ")