...........................................................................................................................................................................................................................................................................................................................................................................
خوش آمدید این سایت دارای مجوز می باشد برای مشاهده مجوز ها پایین صفحه را مشاهده فرمائید.
در بسیاری از تکنیک های آماری، نرمال بودن توزیع داده ها یک پیش فرض است.
وقتی که داده ها از توزیع نرمال پیروی نکنند، ممکن است استفاده از این روش های آماری، منجر به نتیجه گیری اشتباه گردد.
بنابراین آزمون نرمال بودن داده ها اهمیت می یابد.
برخی از تحلیل ها و روش های آماری که پیش شرط نرمال بودن توزیع داده ها و یا باقیمانده های مدل برای آن ها وجود دارد عبارتند از:
آزمون های تی استودنت (تک نمونه ای و دو نمونه ای زوجی و وابسته)
آنالیز واریانس (ANOVA)
آزمون های معناداری ضرایب در رگرسیون
آزمون فیشر برای همگنی واریانس جوامع
آزمون همبستگی پیرسون
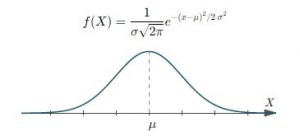
توزیع نرمال، مهم ترین توزیع آماری است هم به جهت اینکه پیش فرض بسیاری از
روش های آماری است ( در عمل پدیده های مختلفی از قانون نرمال پیروی می کنند و این توزیع با توزیع های مختلفی ارتباط پیدا می کند)
و نیز به سبب قضیه مهم حد مرکزی.
در بسیاری از موارد در صورت وجود نمونه به اندازه کافی، جهت تخمین برخی از احتمالات،
می توان از این توزیع بهره برد (به این معنا نیست که نمونه های بزرگ از توزیع نرمال پیروی می کنند بلکه با افزایش
حجم نمونه، توزیع میانگین داده ها و یا برخی آماره های دیگر تحت شرایطی به نرمال گرایش دارد).
توزیع نرمال
برای بررسی نرمال بودن داده ها از دو روش کلی می توان بهره برد
روش توصیفی شامل نمودارها و بررسی شاخص های آماری
روش استنباطی شامل آزمون فرض ها
روش های توصیفی در بررسی نرمال بودن داده ها:
برای بررسی نرمال بودن توزیع داده ها،
ابتدا باید این نکته را توجه داشت که داده هایی که به دنبال بررسی توزیع احتمالی آن هستیم باید کمی و با مقیاس فاصله ای یا نسبی باشند (برای آشنایی با مقیاس های آماری اینجا کلیک کنید).
بنابراین داده هایی که غیر از این باشند،
مثلاً از نوع کیفی اسمی یا کیفی ترتیبی، مثل داده های جمع آوری شده از پرسشنامه با طیف لیکرت، به هیچ وجه نمی توانند از توزیع نرمال پیروی کنند،
حتی اگر برخی از روش ها مثل رسم هیستوگرام داده ها (رسم هیستوگرام برای این داده ها اشتباه است و باید از نمودار میله ای استفاده شود)، توزیع نرمال را تایید کند.
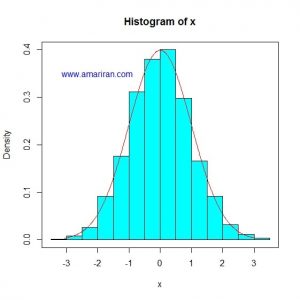
الف) رسم هیستوگرام داده ها و مقایسه آن با منحنی چگالی توزیع نرمال
رسم هیستوگرام داده ها به همراه منحنی توزیع نرمال کمک زیادی به تشخیص نرمال بودن توزیع داده ها می کند.
معمولاً با این روش می توان نرمال نبودن توزیع داده ها و دلایل آن را مشاهده کرد.
اگر هیستوگرام داده ها به توزیع نرمال نزدیک بود آنگاه می توان به سراغ آزمون فرض رفت.
در شکل زیر هیستوگرام یک سری داده استاندارد شده، به همراه منحنی نرمال استاندارد رسم شده است.
توزیع داده ها به توزیع نرمال بسیار نزدیک است (داده ها از توزیع نرمال شبیه سازی شده است).
نکته: برای رسم هیستوگرام داده ها، باید اول داده ها را استاندارد شده (منهای میانگین و تقسیم بر انحراف معیار)
و سپس با منحنی نرمال استاندارد مقایسه شود یا اینکه هیستوگرام داده های اصلی را با توزیع نرمال با میانگین و انحراف معیار داده ها مقایسه شود.
علاوه بر هیستوگرام، استفاده از نمودار جعبه ای نیز می تواند سودمند باشد.
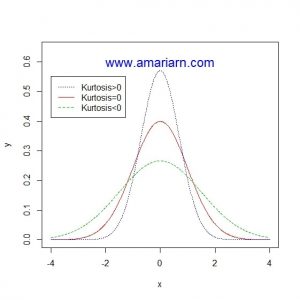
ب) بررسی میزان کشیدگی و چولگی داده ها و مقایسه آن با مقدار این شاخص ها در توزیع نرمال
دو معیار کشیدگی و چولگی در داده ها در تشخیص نرمال بودن توزیع احتمالی داده ها، اهمیت زیادی دارد
و فلسفه برخی از آزمون ها نرمالیتی هم بررسی همین معیارهاست.
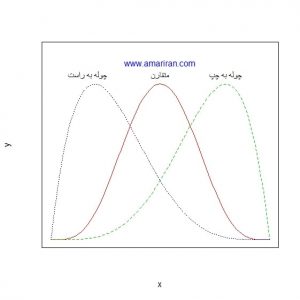
چولگی به میزان عدم تقارن منحنی فراوانی داده ها نسبت به منحنی فراوانی توزیع نرمال استاندارد گفته می شود. در داده های نرمال، منحنی فراوانی به شکل زنگوله مانند و متقارن است به نحوی که می توان شکل را از وسط به دو نیم تقسیم کرد. ولی اگر تمرکز داده ها در یک سمت منحنی نسبت به سمت دیگر بیشتر باشد، نمودار فراوانی داده ها چوله است. اگر تمرکز به سمت راست باشد، چوله به چپ و اگر به سمت چپ باشد، چوله به راست گویند.
چولگی
برای محاسبه میزان چولگی سه ضریب چولگی معمولاً استفاده می شود،
ضریب چولگی اول پیرسون، ضریب چولگی دوم پیرسون و ضریب گشتاوری چولگی (آمار و احتمال مقدماتی بهبودیان).
همچنین کشیدگی به میزان برجستگی منحنی فراوانی داده ها نسبت به منحنی فراوانی توزیع نرمال استاندارد گفته می شود.
معمولاً در محاسبه میزان چولگی و کشیدگی یک نمونه از فرمول های زیر استفاده می شود:
ج) رسم نمودار چندک – چندک و احتمال – احتمال
یکی دیگر از روش های بررسی نرمال بودن داده ها، نمودار چندک – چندک و احتمال – احتمال است.
ایده نمودار چندک – چندک مقایسه چندک های نمونه ای داده ها و چندک های توزیع موردنظر است. در اینجا با توزیع نرمال استاندارد مقایسه صورت می گیرد.
اگر داده ها از توزیع نرمال پیروی کنند، انتظار می رود که نمودار پراکنش چندک های نمونه ای داده ها در مقابل چندک های توزیع نرمال استاندارد در راستای یک خط راست قرار گیرند
(نیاز به استاندارد کردن داده ها نیست).
برای درک فلسفه ایده این روش فرض کنید یک نمونه تصادفی از توزیع نرمال
با میانگین و انحراف معیار در این صورت:
استاندارد شده داده ها و دارای توزیع نرمال استاندارد است.
اگر مرتب شده ها باشند
به نحوی که و ها چندک ام نمونه هستند.
از طرفی تبدیل استاندارد ساز داده ها، نگاشتی صعودی است بدین معنی
که اگر آنگاه بنابراین می توان نوشت:
زیرا:
به عبارت دیگر چون تبدیل استاندارد ساز یک تبدیل صعودی است،
چه اول داده ها را مرتب کرده و سپس تبدیل بزنیم و چه تبدیل زده
و سپس داده های حاصل را مرتب کنیم، در هر دو صورت نتیجه یکسان خواهد بود.
اگر داده ها از توزیع نرمال پیروی کنند، انتظار داریم که با چندک ام توزیع نرمال استاندارد تقریباً برابر باشند.
یعنی . از طرفی به جای بهتر است از یا استفاده کرد.
بنابراین . که معادله یک خط راست با عرض از مبدا و شیب است.
پس اگر توزیع داده ها از توزیع نرمال پیروی کند انتظار می رود که نمودار پراکنش چندک های نمونه ای
و چندک های توزیع نرمال در راستای خطی راست باشد.
نکته: اگر نمودار چندک – چندک، نیمساز ربع اول دستگاه مختصات باشد، توزیع داده ها نرمال استاندارد است.
نکته: از این روش می توان در بررسی برازش توزیع های دیگر به داده ها نیز استفاده کرد.
کافیست به چندک های نمونه ای داده ها در مقابل چندک های توزیع موردنظر بررسی شود.
نکته: در نمودار چندک – چندک لزوماً نیاز به استاندارد سازی داده ها نیست،
طبق آنچه که گفته شد اگر چندک های نمونه ای در مقابل مقادیر مورد انتظارشان در توزیع نرمال استاندارد رسم شود،
انتظار می رود که یک خط راست تشکیل شود؛
حال اگر داده ها استاندارد شود، در صورت نرمال بودن داده ها خط مورد نظر نیمساز ربع اول است
ولی اگر استاندارد نشود، خطی با عرض از مبدأ برابر با میانگین داده ها و شیبی برابر با انحراف معیار داده ها تشکیل می شود.
در روش رسم نمودار احتمال – احتمال نیز مقادیر تابع توزیع تجربی داده ها در مقابل مقادیر مورد مورد انتظار تابع توزیع موردنظر (در اینجا توزیع نرمال) رسم می شود.
در صورتی که توزیع داده ها نرمال باشد، انتظار می رود که نمودار حاصل در امتداد یک خط راست (نیمساز ربع اول) باشد.
P-P plot & Q-Q plot
آزمون های آماری بررسی نرمال بودن توزیع داده ها
برای بررسی نرمال بودن توزیع داده ها، آزمون های زیادی پیشنهاد شده است از جمله:
استفاده از آزمون های کلوموگروف – اسمیرنوف، شاپیرو – ویلک و اندرسون – دارلینگ عمومیت بیشتری دارد.
با افزایش حجم نمونه انتظار می رود که توان آزمون ها نیز بیشتر شود ولی از بین این آزمون ها، معمولاً شاپیرو – ویلک بیشترین توان و کلوموگروف – اسمیرنوف کمترین توان را دارد.
آزمون های نرمالیتی از لحاظ فلسفه آزمون به سه دسته کلی تقسیم بندی می شوند:
آزمون هایی که تابع توزیع تجربی داده ها با تابع توزیع نرمال مقایسه می کنند
(مثل کلوموگروف – اسمیرنوف)، آزمون هایی که براساس یک رابطه رگرسیونی و یا تحلیل همبستگی
بین آماره های ترتیبی و مقادیر مورد انتظارشان شکل گرفته اند (مثل شاپیرو – ویلک)
و آزمون هایی که براساس مقایسه شرایط عمومی داده ها با توزیع نرمال مثل چولگی و کشیدگی شکل گرفته اند (مثل دی آگوستینو).
نکته: آزمون هایی که در اکثر نرم افزارهای آماری تحت عنوان آزمون کلوکوگروف – اسمیرنوف
برای بررسی توزیع نرمال آمده است در واقع شکل اصلاح شده این آزمون برای بررسی نرمال بودن توزیع داده هاست
که در برخی منابع این نوع آزمون تحت عنوان آزمون لیلیفورس یاد می شود.
آزمون لیلیفورس در بررسی نرمالیتی نسبت به آزمون کلی کلوموگروف – اسمیرنوف توان بالایی دارد
که به همین خاطر در اکثر نرم افزارهای آماری در کنار آزمون شاپیرو – ویلک گنجانده شده است.
بیشترین توان های آزمون نرمالیتی در بین چهار آزمون متداول به ترتیب متعلق
به شاپیرو – ویلک، اندرسون – دارلینگ، لیلیفورس و کلوموگروف – اسمیرنوف است.
نکته: فلسفه آزمون شاپیرو – ویلک شبیه به فلسفه نمودار چندک – چندک است.
در این آزمون یک رابطه رگرسیونی بین آماره های ترتیبی داده ها و مقادیر مورد انتظار آماره های ترتیبی توزیع نرمال
در نظر گرفته می شود و آماره آزمون، چیزی شبیه به ضریب تعیین در رگرسیون است که هر چقدر بیشتر باشد نشان دهنده نزدیکی توزیع داده ها به توزیع نرمال است و مقادیر کوچک آماره آزمون باعث
رد فرض صفر (نرمال بودن توزیع داده ها) می شود.
نکته:برای اجرای آزمون شاپیرو – ویلک تعداد نمونه حداقل ۳ و حداکثر ۵۰۰۰ باید باشد
(نقاط بحرانی این آزمون تا حجم نمونه ۵۰۰۰ محاسبه شده است).
نکته: گاهی این مطلب به چشم می خورد که گفته می شود آزمون شاپیرو – ویلک برای
نمونه های کمتر از ۵۰ بسیار مناسب است. توان این آزمون با افزایش حجم نمونه افزایش می باید
و برعکس این مطلب، در تعداد نمونه کم، این آزمون توان قابل قبولی ندارد.
نقاط بحرانی این آزمون در ابتدا برای حجم نمونه تا ۵۰ (Shapiro and Wilk; 1965) و
در مقاله ای دیگر تا حجم نمونه ۵۰۰۰ محاسبه شده است. لذا در برخی از مقالات، توان این آزمون تا حجم نمونه ۵۰ مورد ارزیابی قرار گرفته و این گمان به وجود آمده که آزمون شاپیرو – ویلک برای نمونه کمتر از ۵۰ مناسب است.
نکته: مقایسه توان آزمون ها بستگی به شرایطی مثل چولگی و کشیدگی و حجم نمونه دارد
و در شرایط مختلف ممکن است کارایی آزمون ها با هم متفاوت باشد.
عموماً آزمون های نرمالیتی برای حجم نمونه بیشتر از ۲۰۰ توان معقولی دارند
به همین خاطر توصیه می شود اگر حجم نمونه کمتر از این مقدار باشد از روش های توصیفی استفاده شود.
نکته: آزمون کلوموگروف – اسمیرنوف به نقاط پرت حساسیت زیادی ندارد
ولی در مقابل آزمون شاپیرو – ویلک به داده های پرت حساس است.
نکته: در نرم افزار SPSS دو آزمون شاپیرو – ویلک و آزمون کلوموگروف – اسمیرنوف قابل انجام است
و در نرم افزار Minitab نیز علاوه بر این دو آزمون، امکان انجام آزمون اندرسون – دارلینگ وجود دارد.
در نرم افزار R نیز در بسته stats دو آزمون کلوموگروف – اسمیرنوف
و شاپیرو – ویلک قابل انجام است
و در بسته nortest آزمون های اندرسون – دارلینگ،
لیلیفورس (حالت اصلاح شده آزمون کلوموگروف برای آزمون نرمالیتی)،
کای دو پیرسون، شاپیرو – فرانسیا و آزمون کرامر – وان–میسز قابل انجام است.
در بسته fBasics نیز امکان انجام آزمون های جارکو – برا و دی آگوستینو وجود دارد.
برای اجرای نرم افزار Spss از روش های زیر میتوان استفاده نمود.
Start \ All Programs \ Spss for windows \ Spss 13 for windows
اجرای مستقیم Spss با دابل کلیک بر روی فتیل Spsswin که در موشه محتوی فایل های SPSS در مسیر نصب قرار دارد
اجرای نرم افزار با استفاده از آیکون های میانبر الف) پوشه ای که SPSS در آنجا نصب شده است را پیدا کنید ب) فایل Spsswin را پیدا کرده و ار آن یک میانبر بر روی Desktop ایجاد کنید ج) با دابل کلیک بر روی ایکون مربوط Spss شوید
اجرای Spss با استفاده از دستور Run کافی است مسیر Spsswin را در مقابل دستور Run وارد نمایید بطور مثال : Run: D: SPSS\Spsswin
برای مشاهده لیست همه ی پرسشنامه های استاندارد لطفا همین جا روی پرسشنامه استانداردکلیک فرمایید.
تحلیل داده های آماری برای پایان نامه و مقاله نویسی ،تحلیل داده های آماری شما با نرم افزارهای کمی و کیفی ،مناسب ترین قیمت و کیفیت عالی انجام می گیرد.
اولین کاری که بعد از گردآوری و وارد کردن داده ها انجام می دهیم شمارش تعداد افرادی است که پاسخ های معیّنی به هر پرسش داده اند.
با این کار نحوه پراکندگی یا توزیع نمونه را در طبقات مختلف هرمتغیر بررسی می کنیم. نتیجه این شمارش توزیع فراوانی است. توزیع فراوانی به طور متداول شامل فراوانی و درصد فراوانی است که عموما برای متغیرهای اسمی یا ترتیبی به کار می رود.
مثلا در مورد تعداد اعضاء خانواده (بعد خانوار)، استفاده از آماره فراوانی فقط زمانی مناسب که است تعداد اعضا شامل حدود 6 طبقه باشد.
همچنین زمانی که درآمد افراد را به صورت عددی می سنجیم ولی درآمد افراد را کدگذاری مجدد کرده و در پنج طبقه قرار بدهیم می توانیم از توزیع فراوانی برای متغیر درآمد بهره بگیریم.
در مجموع می توان گفت که در وضعیتی که طبقات تشکیل دهنده یک متغیر فاصله ای/نسبی محدود باشد (کمتر از 10 طبقه باشد)، استفاده از آماره فراوانی مناسب است.
در فیلم آموزشی زیر به نحوه ی رسم و توضیح کاربردی جدول توزیع فراوانی در spss پرداخته شده است.
آمار با توجه به چگونگی سازماندهی داده ها به اشکال قابل اندازه گیری، یکی از مهمترین بخش های تحقیق امروز است.
با این حال ، برخی از دانشجویان بین آمار توصیفی و استنباطی دچار سردرگمی می شوند و انتخاب بهترین گزینه برای استفاده در تحقیق خود را برای آنها دشوار می کند.
اگر از نزدیک دقت کنید ، تفاوت بین آمار توصیفی و استنباطی در نام های داده شده آنها کاملاً مشهود است.
“توصیفی” داده ها را توصیف می کند ، در حالی که “استنباطی” استنباط می کند یا به محقق اجازه می دهد تا بر اساس اطلاعات جمع آوری شده به نتیجه گیری برسد.
بطور خلاصه:
اگر بر اساس شاخص های آماری محاسبه شده بر مبنای سرشماری (پارامتر ها) به تحلیل نتاج در باره ی جامعه آماری بپردازیم، در حال توصیف آماری هستیم.
همچنین اگر بر اساس شاخص های آماری محاسبه شده بر مبنای نمونه گیری (آماره ها) به تحلیل نتاج در باره ی نمونه ی آماری بپردازیم، بازم در حال توصیف آماری هستیم.
اما اگر بر اساس شاخص های آماری محاسبه شده بر مبنای نمونه گیری به تحلیل نتاج در باره ی جامعه آماری بپردازیم، در حال استنباط آماری هستیم.
به عبارت دقیق تر برآورد پارامترها را با استفاده از آماره ها استنباط آماری نامیده می شود.
در فیلم زیر این مفاهیم به دقت بررسی شده اند. پیشنهاد می شود حتماً این آموزش را از روا20 نگاه کنید.
AMOS مخفف عبارات Analysis of moment structures می باشد. Amos را می توان یکی از موفق ترین نرم افزارهای کامپیوتری دانست که به طور خاص برای مدل سازی معادله ساختاری طراحی شده اند. این نرم افزار توسط شرکت IBM SPSS Statistics طراحی شده است.
نرم افزار آموس (ایموسAmos ) نرم افزاری برای مدل سازی معادلات ساختاری است که مدل سازی معادله ساختاری را به شیوه ای ترسیمی ارائه می دهد، به نحوی که می توان به سرعت مدل ها را تعریف کرد، محاسبات را انجام داد و در صورت نیاز آن ها را به سادگی اصلاح کرد.
هرچند هدف اصلی از طراحی این نرم افزار مدل سازی است اما قابلیت اجرای مجموعه ای از تحلیل های کمی و آماری معمول نیز بوسیله این نرم افزار وجود دارد. این نرم افزار برای اجرا به حداقل ۲۵۶ مگابایت RAM و 125 مگابایت فضای آزاد نیاز دارد.
Amos Graphics
استفاده از این نرم افزار به دو شیوه نوشتن برنامه به زبانVB.NET و همچنین استفاده از Amos Graphics امکان پذیر است. استفاده از هریک از روش های ذکر شده به لحاظ کار بر روی انواع مدل ها، استفاده از انواع شیوه های برآورد پارامترها و یا محاسبه انواع شاخص های برازندگی و اخذ خروجی های مختلف، مشابه یکدیگر است اما در عین حال استفاده از Amos Graphics تاحدودی ساده تر از برنامه نویسی است چرا که استفاده از آن برمبنای ترسیم مدل تدوین شده توسط پژوهشگر قرار دارد.
مدل نظری پژوهش در مقایسه با مدل مدون در Amos
به منظور استفاده از نرم افزار Amos بایستی به تفاوت های بین مدل های تعریف شده در Amos و مدل نظری توجه داشته باشیم. مدل نظری مدلی است که پژوهشگر با توجه به مبانی و چارچوب نظری مدل تعریف کرده است. این مدل عمدتا شامل متغیرهای پنهان، معرف های مرتبط و همچنین روابط بین آن ها می باشد. در مدل نظری پژوهشگر تعریف می کند که متغیرهای پنهان قرار است با کدام معرف ها اندازه گیری شوند و اینکه متغیرهای پنهان (و احتمالا برخی متغیرهای آشکار) چگونه با یکدیگر ارتباط داشته و یا یکدیگر را تحت تأثیر قرار می دهند. مدل مدون در ایموس گرافیکس (Amos Graphics) ضمن آن که همه اجزای تعریف شده در مدل نظری پژوهش را داراست، دارای اجزای جدیدی است که برای کار با Amos وجود این اجزا یا عناصر جدید ضرورت دارد.
جزئیات بیشتر هنگام کار با Amos Graphics معمولا شامل تعریف متغیرهای خطا (خطاهای اندازه گیری و خطاهای تبیین شده یا ساختاری) و همچنین تعریف متغیرهای مرجع است.تعریف متغیر مرجع به این مسئله برمی گردد که متغیرهای پنهان موجود در مدل فاقد ریشه و واحد اندازه گیری هستند.
برای حل بدون مقیاس بودن متغیرهای پنهان دو راه وجود دارد :
استاندارد در نظر گرفتن متغیر پنهان (متغیری با میانگین صفر و انحراف معیار ۱) که برای این منظور لازم است واریانس متغیر پنهان برابر ۱ قرار داده شود.
قرار دادن ریشه و واحد اندازه گیری یکی از متغیرهای مشاهده شده مرتبط با متغیر پنهان به عنوان ریشه و واحد اندازه گیری همان متغیر پنهان. در این حالت به متغیر مشاهده شده اصطلاحا متغیر مرجع یا معرف نشان گذار گفته می شود.
آنچه در مدل سازی معمول است استفاد از روش دوم می باشد هرچند استفاده از روش اول نیز منجر به نتایج مشابهی در برآورد پارامترها می شود. لازم به ذکر است که متغیرهای پنهان موجود در مدل (به عبارت دیگر متغیرهایی که فاقد مقیاس اندازه گیری اند) خود به دو دسته اصلی تقسیم می شوند :
الف– متغیرهای خطا که شامل خطای اندازه گیری در مدل های اندازه گیری و خطاهای تبیین در مدل ساختاری اند. این متغیرها اساسا متغیرهای پنهانی هستند که اندازه گیری نشده اند، مدل را تحت تأثیر قرار می دهند ولی در مدل نظری پژوهش حضور نداشته اند.
ب– متغیرهای پنهان درمدل ساختاری که هرکدام با مجموعه ای از متغیرهای مشاهده شده اندازه گیری خواهند شد.
مراحل اجرایی کار با Amos Graphics
به طور خلاصه چهار مرحله اجرایی زیر را برای کار با Amos Graphics می توان نام برد:
الف. تهیه فایل داده ها با SPSS
ب. ترسیم مدل تدوین شده در صفحه میانجی.
ج. مشخص کردن جزئیات تحلیل شامل موارد مورد نیاز در خروجی وتغییر شیوه برآورد پارامترها(درصورت لزوم)
د. انجام تحلیل و برآورد پارامترها.
حال به توضیح هر کدام می پردازیم:
الف .تهیه فایل داده های ورودی
فایل داده ها با استفاده از نرم افزار SPSS و به سه شکل زیر تهیه می شود:
فایل حاوی داده های خام
فایل حاوی ماتریس واریانس-کواریانس برگرفته از داده های خام
مراحل تهیه ماتریس همبستگی تا حد زیادی به تهیه فایل در قالب واریانس-کواریانس شباهت دارد اما با این حال توجه به تفاوت های آن ها نیز ضرورت دارد. یکی از مهمترین این تفاوت ها این است که در صورت تدارک داده های گردآوری شده در قالب ماتریس همبستگی ضرورت دارد که میانگی ها و انحراف معیارهای متغیرها نیز در فایل وارد شوند تا امکان برآورد پارامترها به صورت غیراستاندارد نیز فراهم شود. درحالیکه با وجود ماتریس واریانس-کواریانس امکان برآوردهای استاندارد و غیراستاندارد وجود دارد.
ب. ترسیم مدل تدوین شده در Amos Graphics
Amos Graphics یک جعبه ابزار متنوع در اختیار کاربر قرار می دهد که با استفاده از آن ها می توان مدل تدوین شده را با کلیه جزئیات آن ترسیم کرد بلکه امکانات مختلفی را برای اجرای تحلیل و مشاهده خروجی ها در اختیار قرار می دهد. توضیح این نکته لازم است که جعله ابزار قابل مدیریت است به نحوی که می توان نشانه هایی را به آن افزوده یا از آن کم کرد.
ج. مشخص کردن جزئیات تحلیل
پس از تدارک داده ها و ترسیم مدل لازم است قبل از اجرای تحلیل برخی از جزئیات آن مشخص شوند. چنین جزئیاتی می توانند موارد متنوعی را در برگیرند اما توجه به دو نکته لازم است :
تعیین مواردی که مایل هستید علاوه بر موارد پیش فرض در خروجی گزارش شوند. مانند گزارش برآوردهای استاندارد علاوه بر برآوردهای غیراستاندارد در مدل.
تعیین روش برآورد پارامترها. به طور پیش فرض روش حداکثر درستنمایی برای این منظور تعریف شده است.
د. اجرای تحلیل و برآورد پارامترها
اجرای تحلیل و برآورد پارامترها را می توان آخرین مرحله در اجرای اولیه دانست. پس از اجرای اولیه تحلیل و برآورد پارامترها و شاخص های مختلف برازش و همچنین وارسی سایر خروجی ها درباره تغییر، پژوهشگر می تواند درباره تغییر و اصلاح مدل تصمیم گیری نماید.
منبع
مدل سازی معادله ساختاری در پژوهش های اجتماعی با کاربرد Amos / نوشته دکتر وحید قاسمی / انتشارات جامعه شناسان.
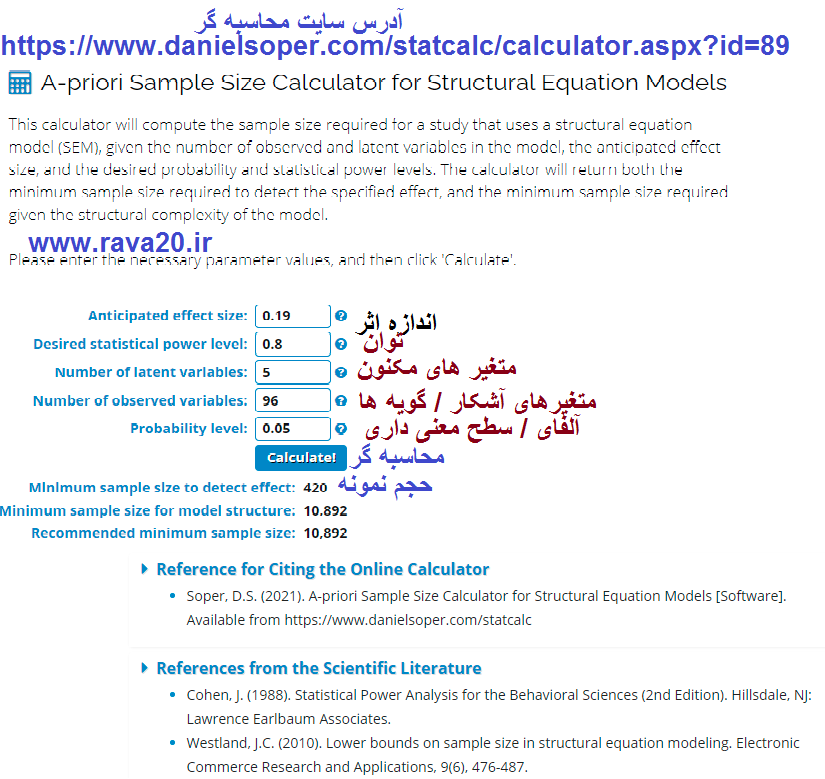
محاسبه گر حجم نمونه برای مدل سازی معادلات ساختاری (SEM) کوواریانش محور
مبحث حجم نمونه و نحوه محاسبه آن یکی از مباحث کلیدی در تحقیقات است که معمولاً محققین در این خصوص سوالات بسیاری دارند و در تعیین حجم نمونه دچار اشکالی اساسی هستند، چون معمولاً برای تعیین حجم نمونه از فرمول کوکران یا جدول کرجسی و مورگان استفاده می کنند، با توجه به اینکه این فرمول ها بر اساس پارامتر نسبت طراحی شده اند در بسیاری از مورد کاربرد ندارند، لذا محققان را در دفاع از پایان نامه یا پذیرش مقاله در مجلات معتبر علمی دچار مشکل می کند.
یکی از نرم افزارهای مناسب برای تعیین حجم نمونه نرم افزار IBM SPSS Sample power است.
در این کتاب سعی شده است روش کار با این نرم افزار به صورت بسیار ساده و کاربردی، همراه با مثال های ملموسی آموزش داده شود، بطوریکه کاربر و محقق بایک بار مطالعه این کتاب، قادر خواهد بود کار با این نرم افزار را یادبگیرد.
امّا واقعیت این است که برای مدل سازی معادلات ساختاری کواریانس محور در این نرم افزار جای مناسبی وجود ندارد ، پس وقتی محقق بخواهد برای تحلیل داده های خود از نرم افزارهای مانند ایموس، لیزرل و … استفاده کند ، برای تعین حجم نمونه باید از فرمول ها و روش های دیگری استفاده نماید. یکی از این روش ها استفاده از قاعده سر انگشتی است و روش بهتر استفاده از محاسبه گرهای مبتنی بر فرمولهای پیشرفته است. که روش دومی مناسبتر می باشد.
در زیر یک محاسبه گر آن لاین آمده است که می توانید برای حجم نمونه در مدل سازی معادلات ساختاری کواریانس محور از آن استفاده نمایید.
برای محاسبه دقیق حجم نمونه بر اساس این محاسبه گر، اعداد را در جای خود بر اساس توضیحات زیر وارد نمایید.
در قسمت Anticipated effect size که باید اندازه اثر مورد نظر برای آزمون مدل سازی معادلات ساختاری را وارد نمایید از قانون سه مقدار Chin در سال 1998 برای مقادیر R2 استفاده می کنید. سه مقدار چین شامل 0.19 و 0.33 و 0.67 است که محقق باید اندازه اثر 0.19 را جهت تشخیص آزمون برای این اندازه اثر وارد نماید.
2. در گام دوم توان آزمون Desired statistical power level یا همان عکس خطای نوع دوم را باید وارد نمود که در مطالعات علوم انسانی و اجتماعی این مقدار بین 80 تا 90 درصد انتخاب می شود و حداقل آزمون باید توانی برابر با 80 درصد داشته باشد.
در قسمت سوم تعداد متغیر های مکنون مدل پژوهش Number of latent variables اعم از برونزا و درونزا را وارد می کنیم که در مثال زیر 5 متغیر مکنون است. که هریک بر اساس گویه هایی اندازه گیری می گردند.
متغیر های آشکار یا همان گویه های پرسش نامه یعنی Number of observed variables را وارد نمایید که در اینجا 96 متغیر آشکار یا مشاهده پذیر وجود دارد(آیتم/ سوال/ گویه)
در نهایت میزان خطای نوع اول را جهت دستیابی به بازه اطمینان 95 یا 99 درصد را وارد نمایید یعنی بجای Probability level مقادیر 0.05 و یا 0.01 را وارد نمایید. البته بهتر است که هر دو در دو سناریو مختلف وارد شوند سپس بر اساس نوع مسئله، توان محقق، بودجه محقق و غیره یکی از حجم نمونه های تعیین شده انتخاب گردد. سپس آیکون Calculate زده می شود. عدد اول ظاهر شده حجم نمونه علمی شما برای تحقیق پیش رو است.
گاهی اوقات برای انجام برخی تحلیل ها نیاز به داده های گسسته و متغیر کیفی در نرم افزار SPSS داریم. روش Recode یکی از مفید ترین روندهایی است که جهت تبدیل یک متغیر پیوسته به متغیر گسسته بکار می رود. گزینه Recode از منوی Transform جهت کدگذاری یک متغیر پیوسته به رده های از هم جدا به کار می رود. : فرض کنید متغیر خستگی عاطفی را به صورت یک متغیر کمی وارد نموده اید و حال می خواهید افراد را به 3 گروه 1- عدم خستگی 2- خستگی متوسط و 3- خیلی خسته تقسیم کنید.
ما در این سایت پرسشنامه های استاندارد (دارای روایی، پایایی، روش دقیق نمره گذاری ، منبع داخل و پایان متن ) ارائه می کنیم و همچنین تحلیل آماری کمی و کیفی رابا قیمت بسیار مناسب و کیفیت عالی و تجربه بیش از 17 سال انجام می دهیم. برای تماس به ما به شماره 09143444846 در شبکه های اجتماعی پیام بفرستید. ایمیلabazizi1392@gmail.com
تمامی حقوق مادی و معنوی این سایت متعلق به لنسرسرا و محفوظ است.
این سایت دارای مجوز می باشد
Statcounter


![\[ b= \frac{\mu_3}{s^3}=\frac{\frac{1}{n}\sum_{i=1}^n (x_i-\bar{x})^3} {\sqrt{\frac{1}{n-1}\sum_{i=1}^n (x_i-\bar{x})^2}^3}\]](https://amariran.com/wp-content/ql-cache/quicklatex.com-24256f061964c6565c7f2b0a0ec0b184_l3.svg "Rendered by QuickLaTeX.com")
![\[ \frac{.}{.} \]](https://amariran.com/wp-content/ql-cache/quicklatex.com-2e770cede27765f752eb2ab5a7aebe38_l3.svg "Rendered by QuickLaTeX.com")
![\[k=\frac{\mu_4}{s^4}-3=\frac{\frac{1}{n}\sum_{i=1}^n (x_i-\bar{x})^4}{(\frac{1}{n-1}\sum_{i=1}^n (x_i-\bar{x})^2)^2}-3\]](https://amariran.com/wp-content/ql-cache/quicklatex.com-d4c8fada6ca3be530a63512c044bec55_l3.svg "Rendered by QuickLaTeX.com")
 یک نمونه تصادفی از توزیع نرمال
یک نمونه تصادفی از توزیع نرمال و انحراف معیار
و انحراف معیار  در این صورت:
در این صورت:![\[ Z_i = (X_i-\mu) / \sigma , i=1, 2, \dots, n \]](https://amariran.com/wp-content/ql-cache/quicklatex.com-6aa1749a22ae8bc8e728fd498ecb232e_l3.svg "Rendered by QuickLaTeX.com")
 مرتب شده
مرتب شده  ها باشند
ها باشند  و
و  ها چندک
ها چندک  ام نمونه هستند.
ام نمونه هستند. آنگاه
آنگاه  بنابراین می توان نوشت:
بنابراین می توان نوشت:![\[ Z_{(i)} = (X_{(i)}-\mu) / \sigma , i=1, 2, \dots, n \]](https://amariran.com/wp-content/ql-cache/quicklatex.com-c327c9390b389fce65922c301ec30c1e_l3.svg "Rendered by QuickLaTeX.com")
![\[ Z_{(1)} \leq Z_{(2)} \leq \dots \leq Z_{(n)} \Longleftrightarrow X_{(1)} \leq X_{(2)} \leq \dots \leq X_{(n)} \]](https://amariran.com/wp-content/ql-cache/quicklatex.com-0dd389a740fbc59ee5cf3d7ac7e345cb_l3.svg "Rendered by QuickLaTeX.com")
 . از طرفی به جای
. از طرفی به جای  بهتر است از
بهتر است از  یا
یا  استفاده کرد.
استفاده کرد.  . که معادله یک خط راست با عرض از مبدا
. که معادله یک خط راست با عرض از مبدا 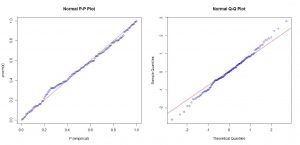



 ۲۰ توصیه برای حرفهای شدن و موفق شدن در زندگی شغلی
۲۰ توصیه برای حرفهای شدن و موفق شدن در زندگی شغلی