...........................................................................................................................................................................................................................................................................................................................................................................
خوش آمدید این سایت دارای مجوز می باشد برای مشاهده مجوز ها پایین صفحه را مشاهده فرمائید.
فایلهای پیدیاف و ورد هر دو کارایی مشترکی دارند؛ ولی فرمتشان متفاوت است. گاهی برای اهداف خاصی لازم است در فایل ورد به بخشی از فایل پیدیاف ارجاع دهید یا محتوای آنها را در یک فایل ادغام کنید. در این مقاله، راههای انتقال فایل پیدیاف به ورد را آموزش میدهیم.
تبدیل PDF به ورد
در این مقاله می خواهیم بهترین، سریع ترین و آسان ترین روش تبدیل فایل PDF به Word را آموزش دهیم. اگر به دنبال تبدیل PDF به ورد هستید، با ادامه مطلب همراه ما باشید:
استفاده از مرورگر گوگل کروم – برای زبان فارسی
گوگل کروم فایل پی دی اف را به ورد تبدیل نمی کند اما فایل پی دی اف را به شما نشان می دهد و به این ترتیب می توانید متن فایل را کپی کرده و در برنامه مایکروسافت ورد Pase کنید. این روش برای فایل پی دی اف متن فارسی بهترین انتخاب است.
به این منظور مراحل زیر را انجام دهید:
مرورگر کروم را باز کنید.
فایل پی دی اف را بر روی صفحه کروم بکشید (درگ کنید) تا فایل به نمایش در بیاید.
متن مورد نظر را انتخاب کرده به یک فایل ورد خالی، کپی کنید.
تبدیل پی دی اف به ورد در برنامه Microsoft Word
کاربران ایرانی برای ویرایش فایل های متنی از برنامه مایکروسافت ورد استفاده می کنند، برای تبدیل PDF به ورد نیز از همین برنامه می توان استفاده کرد. به دلیل محبوبیت مایکروسافت ورد در ایران، به نظر می رسد که استفاده از همین برنامه راحت ترین و آسان ترین راه برای تبدیل فایل های پی دی اف به فایل متنی با پسوند .docx باشد. البته این قابلیت تنها در برنامه ورد نسخه 2013 به بعد وجود دارد و اگر از نسخه های قدیمی تر ورد استفاده می کنید، باید نسخه جدیدتر آن را نصب کنید.
نکته: استفاده از مایکروسافت ورد برای تبدیل فایل های پی دی اف دارای تصویر مناسب نیست. اگر فایل PDF شما تنها از متن تشکیل شده از این روش استفاده کنید.
به این منظور مراحل زیر را انجام دهید:
برنامه Microsoft Word را باز کنید.
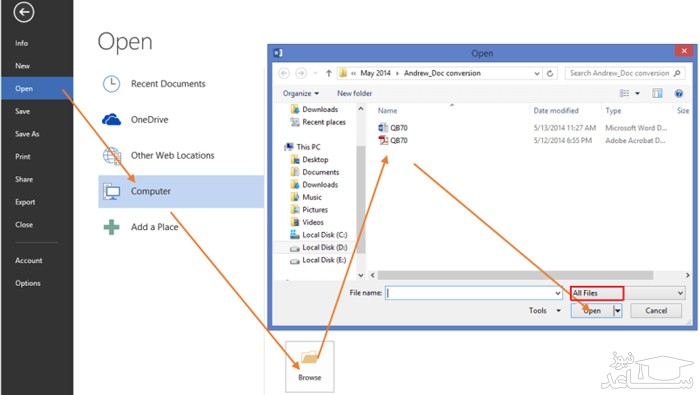
بر روی گزینه File کلیک کرده و از منوی باز شده Open را انتخاب کنید.
در این بخش باید فایل پی دی اف خود را از کامپیوتر انتخاب کنید.
در این قسمت برنامه ورد از شما تائیدیه تبدیل فایل را درخواست می کند و با کلیک بر روی گزینه Yes این تائیدیه را صادر کنید. فایل تبدیل شده پس از چند ثانیه به نمایش در می آید.
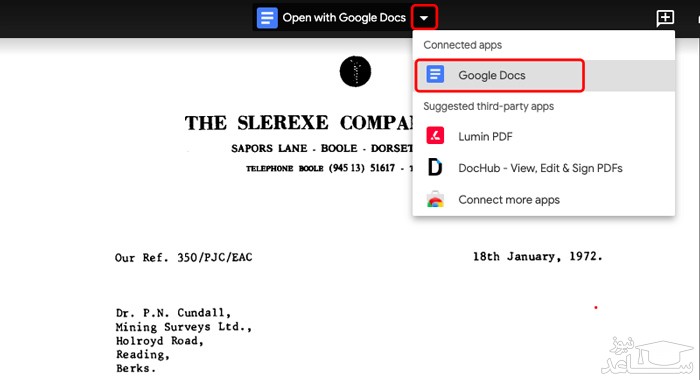
تبدیل PDF به ورد در برنامه Google Docs
گوگل داکس یک برنامه ویرایش متن آنلاین است که قابلیت های زیادی را ارائه می دهد. این برنامه تنها برای افرادی که حساب جیمیل خود را به مرورگر متصل کرده اند، در دسترس است. گوگل داکس هرچند به پای مایکروسافت ورد نمی رسد اما آسانی دسترسی به آن و برخی از ویژگی ها مانند تبدیل صوت به متن حتی در زبان فارسی، موجب شده تا در سال های اخیر، به شمار طرفداران این برنامه افزوده شود. قبل از استفاده از این برنامه به حساب گوگل خود وارد شوید.
نکته: برنامه Google Docs فایل PDF شما را اسکن می کند و مشکلی برای تبدیل متن ندارد، اما تصاویر را به خوبی تبدیل نمی کند و تنها متون موجود در متن را به ورد تبدیل می کند.
برای این منظور مراحل زیر را انجام دهید:
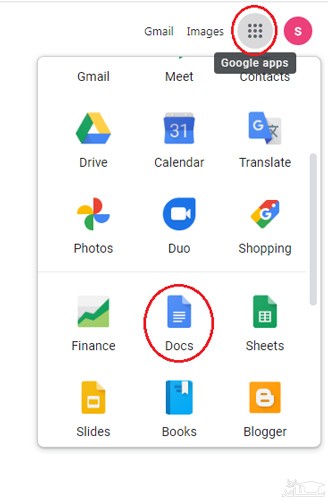
در مرورگر خود بر روی آیکون Google Apps کلیک کرده و برنامه گوگل داکس را انتخاب کنید.
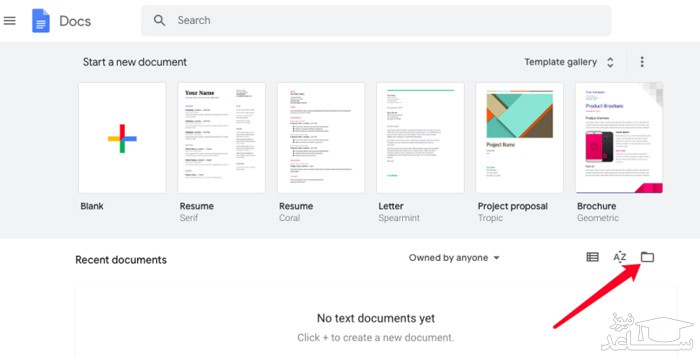
با ورود به برنامه بر روی آیکون پوشه کلیک کنید.
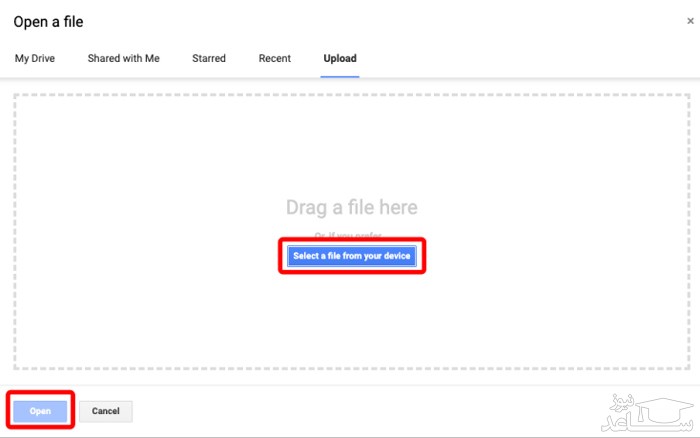
از تب آپلود، فایل PDF خود را با استفاده کشیدن و رها کردن یا انتخاب از روی سیستم، آپلود کنید.
در حال حاضر فایل پی دی اف برای شما به نمایش درآمده است، در این جا باید با کلیک بر روی نشانه گر در قسمت بالای صفحه گزینه گوگل داکس را انتخاب کنید تا با محیط ویرایش متن وارد این برنامه شوید.
حال همانند تصویر، گزینه فایل را انتخاب کرده و از بخش دانلود، بر روی گزینه Microsoft Word کلیک کنید تا فایل ورد بر روی سیستم دانلود شود.
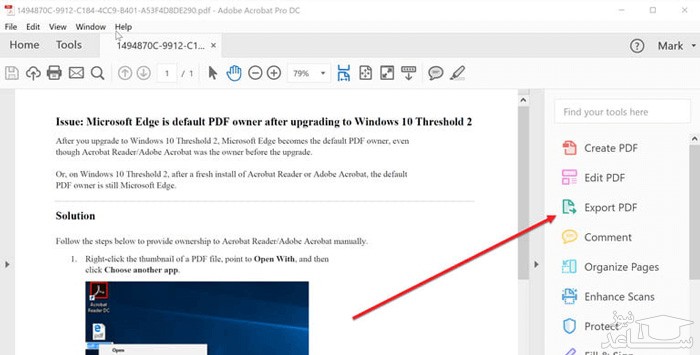
تبدیل پی دی اف به ورد در برنامه Adobe Acrobat – برای فایل های دارای عکس
ادوبی اکروبات یک برنامه تخصصی برای فایل های PDF محسوب می شود که قابلیت های زیادی دارد. در این برنامه می توان از فایل PDF خروجی گرفت و آن را به ورد تبدیل کرد. مزیت برنامه ادوبی اکروبات، خروجی با کیفیت تصاویر در فایل های پی دی اف است، موردی که نقطه ضعف دو روش قبلی محسوب می شد. بنابراین اگر فایل PDF شما دارای تصویر است، بهتر است از ادوبی اکروبات استفاده کنید.
به این منظور مراحل زیر را انجام دهید:
برنامه اکروبات را باز کرده و از منوی فایل یک فایل PDF را انتخاب کنید.
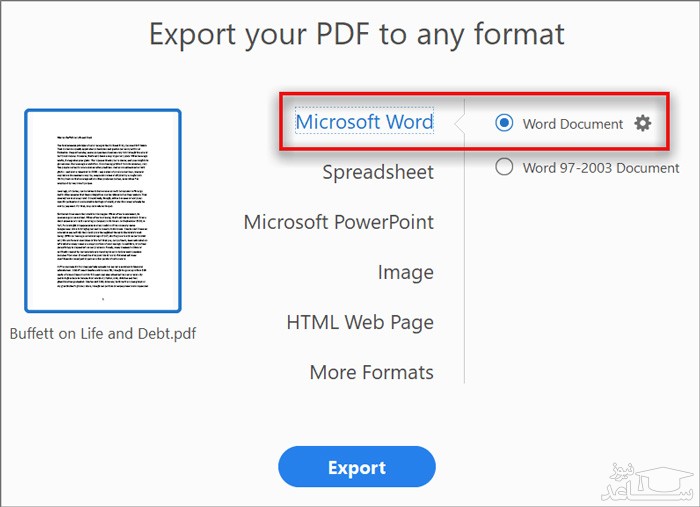
در پنل سمت راست صفحه گزینه Export PDF را پیدا کرده و انتخاب نمایید.
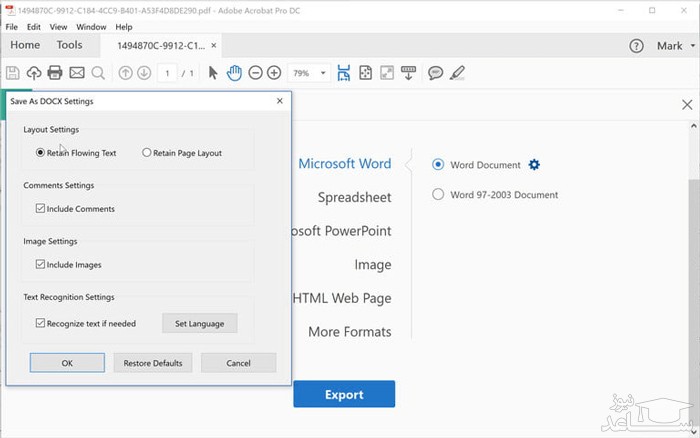
در پنجره جدید گزینه Word Document را انتخاب کنید، البته با این کار تنها متن فایل به پی دی اف تبدیل می شود.
برای خروجی گرفتن از اجزای دیگر فایل PDF مانند عکس و کامنت ها، بر روی آیکون چرخ دنده کلیلک کرده و در پنجره جدید، تیک لایه ها، تصویر و کامنت را بزنید تا از فایل پی دی اف به صورت کامل خروجی گرفته شود.
استفاده از برنامه های تبدیل پی دی اف آنلاین
ده ها سایت آنلاین رایگان برای تبدیل فایل PDF به ورد وجود دارد که با سرعت این کار را انجام می دهند. از جمله این سایت ها می توان به SmallPDF ،PDF2Doc و iLovePDF اشاره کرد. با ورود به این سایت ها فایل پی دی اف خود را آپلود کرده و به ورد تبدیل کنید.
چگونه فایلها را در ویندوز 10 بهصورت مستقیم و بدون انتقال به سطل زباله پاک کنیم؟
ممکن است تأیید انتقال فایلهای پاکشده به سطل زباله و خالیکردن آن زمانبر باشد؛ اما راهکاری وجود دارد که با استفاده از آن میتوان فایلها را بهصورت مستقیم و بدون انتقال به سطل زباله پاک کرد.
شیوه حذف سریع یک یا چند فایل
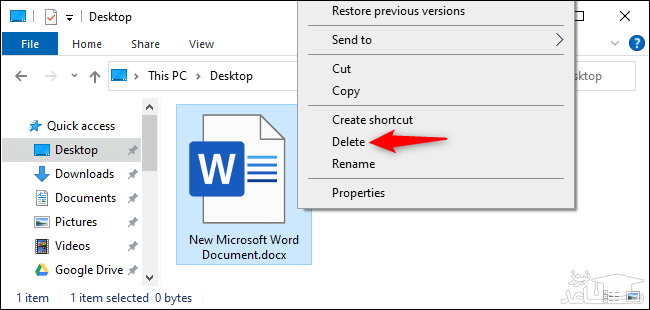
جهت حذف سریع یک یا چند فایل (پوشه)، باید آن ها را انتخاب کرده و سپس کلیدهای “Shift+Delete” را بر روی صفحه کلید خود فشار دهید. البته می توانید بر روی آیتم های انتخاب شده نیز کلیک-راست کرده، کلید “Shift” را نگه داشته و سپس در منوی ظاهر شده بر روی گزینه “Delete” کلیک کنید.
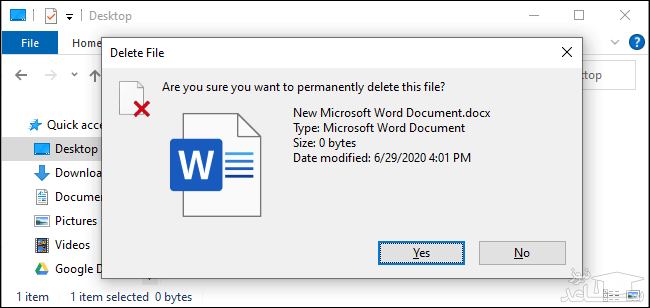
در ادامه ویندوز از شما می پرسد که آیا می خواهید فایل های موردنظر را برای همیشه حذف کنید؟ در اینجا باید بر روی “Yes” کلیک کرده و یا اینکه کلید “Enter” را بر روی صفحه کلید فشار دهید. در این روش دیگر نمی توانید فایل های حذف شده خود را از طریق سطل آشغال بازیابی کنید.
حذف فایل بدون انتقال به سطل آشغال در ویندوز 10 به صورت همیشگی
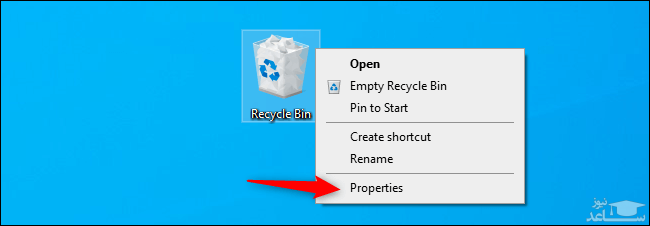
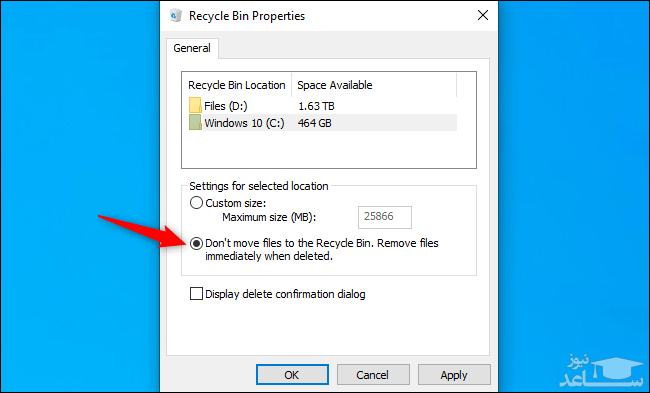
شما همچنین می توانید به ویندوز بگویید که در آینده نیز از سطل آشغال استفاده نکند. جهت انجام این کار باید بر روی آیکون “Recycle Bin” کلیک-راست کرده و سپس گزینه “Properties” را انتخاب کنید.
در ادامه باید گزینه “Don’t move files to the Recycle Bin. Remove files immediately when deleted” را فعال کنید. فقط باید به یاد داشته باشید که ویندوز برای هر درایو، از سطل آشغال مختص به همان درایو استفاده می کند. به عنوان مثال، اگر فایلی را بر روی درایو C حذف کنید، آنگاه به سطل آشغال مربوط به درایو C منتقل می شود. یا اگر فایلی را بر روی درایو D حذف کنید، آنگاه به سطل آشغال همان درایو منتقل خواهد شد.
بنابراین اگر چندین درایو دارید، آنگاه باید تنظیمات بالا را بر روی تمامی درایوهای موردنظر خود اعمال کنید.
در نهایت بر روی کلید “OK” کلیک کنید تا تغییرات اعمال شده شما ذخیره شوند.
هشدار: با انجام اقدامات بالا، در آینده هر فایلی را که حذف کنید، فورا و به صورت مستقیم حذف خواهد شد، درست همانند اینکه در هنگام حذف کردن آن، کلیدهای ترکیبی “Shift+Delete” را نگه داشته باشید. بنابراین اگر فایل (هایی) را انتخاب کرده باشید و سپس به صورت اتفاقی کلید “Delete” را فشار دهید، آنگاه آیتم های یاد شده به سرعت ناپدید شده و دیگر نمی توانید آن ها را بازگردانید (مگر با ابزارهای ریکاوری).
یوتیوب یکی از پرطرفدارترین شبکه های اجتماعی است که بسیاری از افراد برای کسب درآمد و آموزش به آن متوسل می شوند. در کنار فیلتر بودن این شبکه اجتماعی برای کاربران ایرانی، مشکل عمده و اصلی کار را یوتیوب دانلود کردن ویدیوهای آن است در این آموزش با نحوه دانلود ویدیو های یوتیوب همرا ما باشید.
سایت دانلود از یوتیوب با لینک مستقیم
دانلود فیلم از یوتیوب بدون نرم افزار مزیت های متعددی دارد. از مهم ترین آن ها می توان به در دسترس بودن در همه ی سیستم های عامل عدم نیاز به دانلود و نصب نرم افزار و اپلیکیشن اضافه اشاره کرد. یکی از راهکارهای آسان، استفاد از وب سایت vdyoutube است. برای دانلود فیلم از یوتیوب بدون نرم افزار در وب سایت VD، مراحل زیر را دنبال کنید.
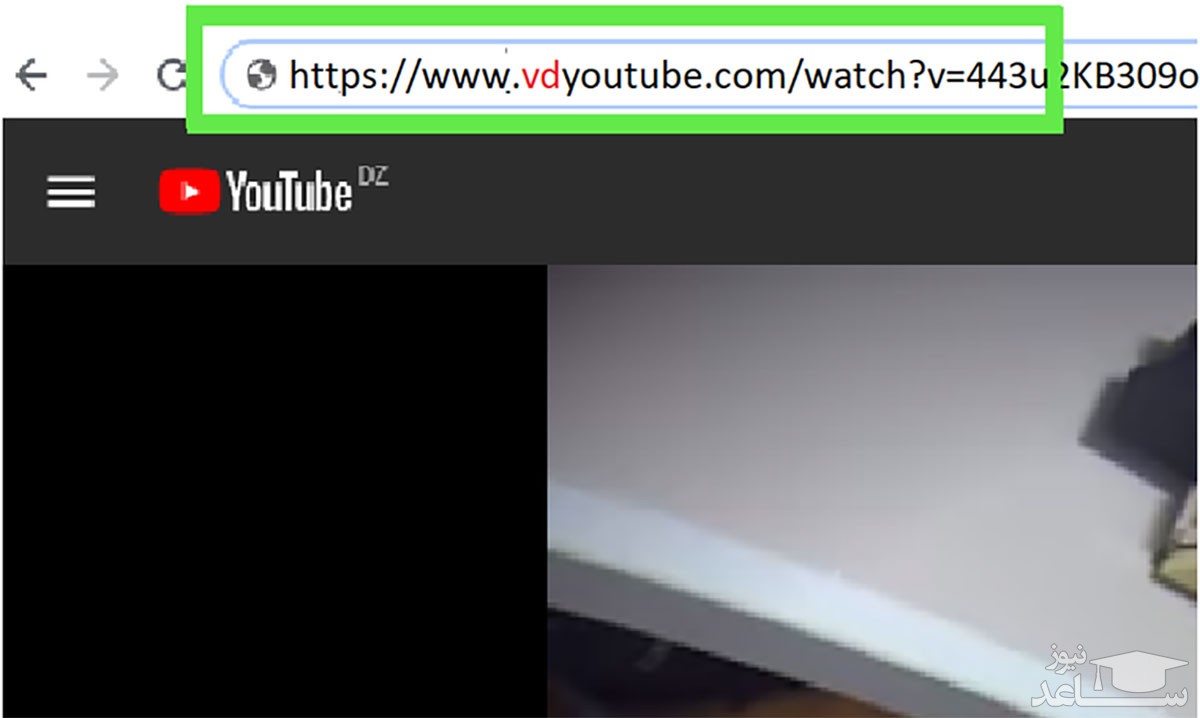
۱- ابتدا وارد وب سایت یوتیوب شوید و فیلم مورد نظر خود را در آن پیدا کنید. سپس در آدرس بالای صفحه، پیش از کلمه ی youtube، حروف vd را نوشته و دکمه ی اینتر را فشار دهید. این کار، شما را به سایت دانلود از یوتیوب با لینک مستقیم می برد.
۲- در وب سایت جدید، لینک دانلود فیلم یوتیوب دیده می شود که می توانید با انتخاب کیفیت مورد نظر از بین کیفیت ها و فرمت های موجود، ویدیوی مورد نظر را با لینک مستقیم دانلود کنید.
وب سایت دیگری که برای دانلود از یوتیوب بدون نرم افزار کاربرد دارد، KeepVid نام دارد که از قدیمی ترین سرویس ها محسوب می شود. برای دانلود از KeepVid مراحل زیر را دنبال کنید:
۱- وارد وب سایت یوتیوب شوید و ویدیوی مورد نظر خود را پخش کنید.
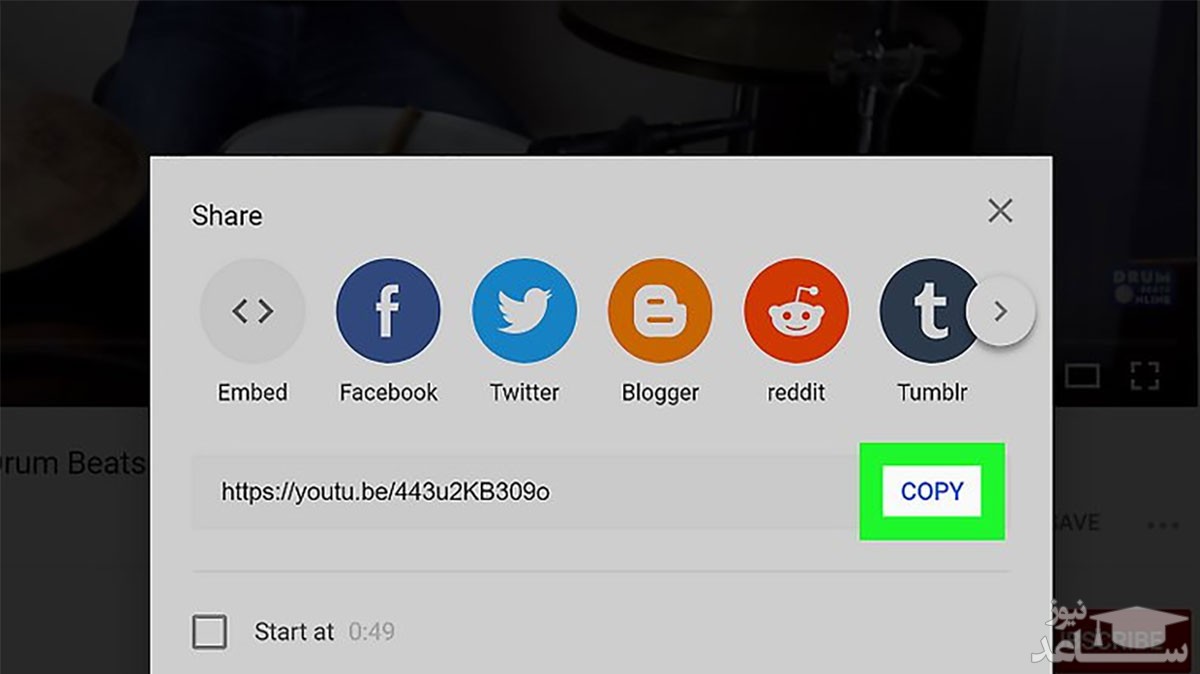
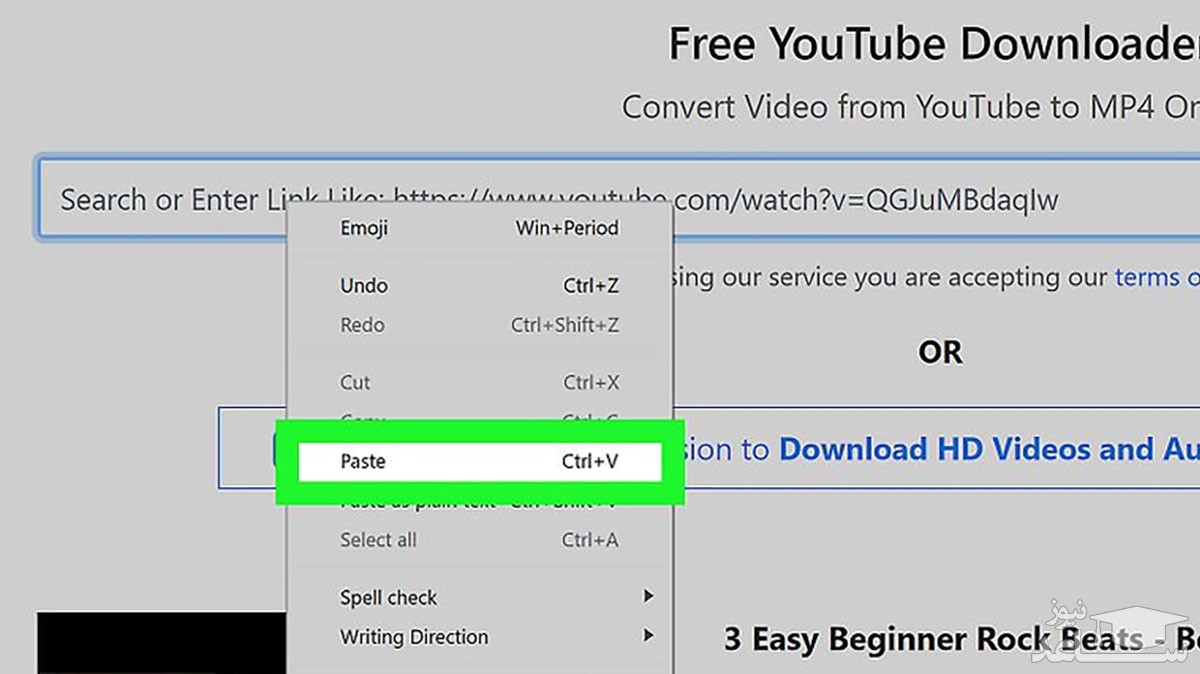
۲- از منوی پایین ویدئو، روی دکمه ی Share و سپس Copy کلیک کنید. آدرس اشتراک ویدئو در کلیپ بورد کامپیوتر کپی می شود.
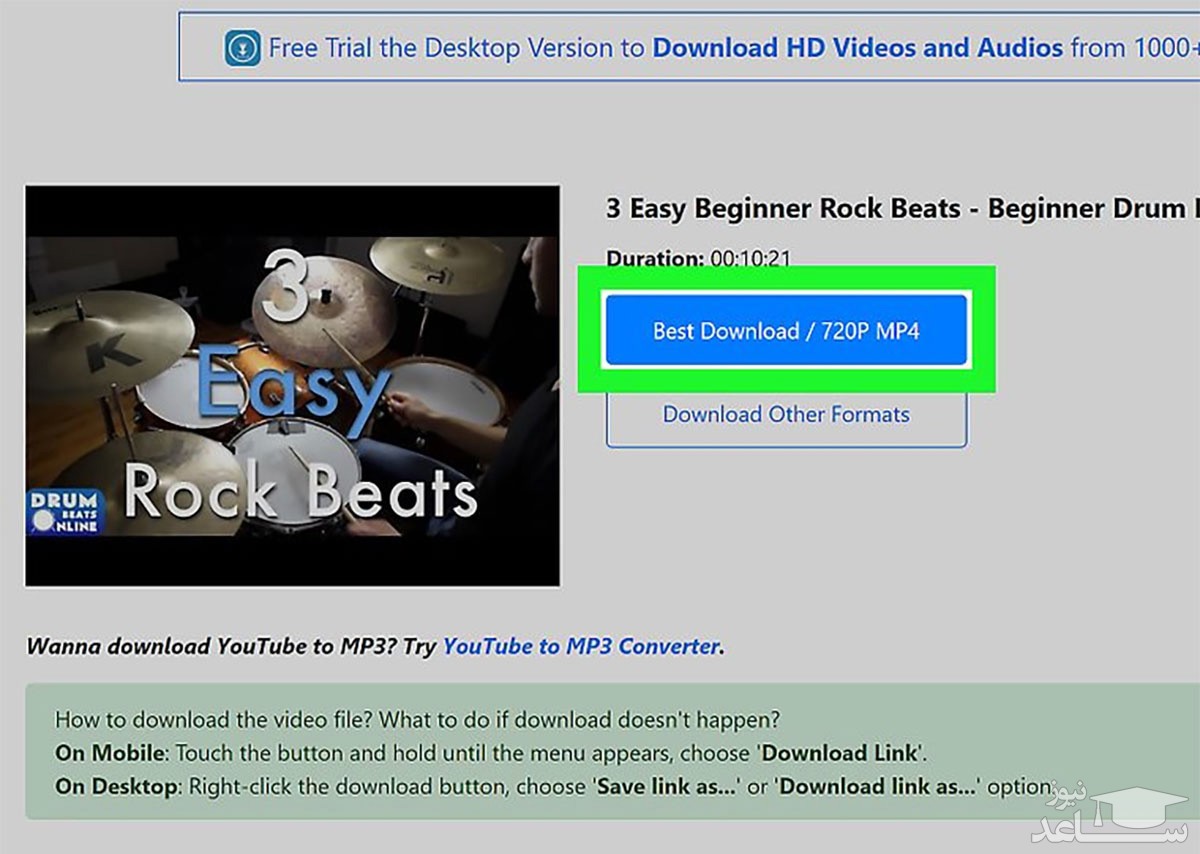
۳- وارد وب سایت Keepvid.pro شوید و وارد منوی Video Downloader و سپس Youtube Video Downloader شوید و لینک را وارد کنید.
۴- برای دانلود فیلم مورد نظر، روی دکمه ی Best Download در صفحه ی جدید کلیک کنید یا برای تغییر فرمت و کیفیت فیلم دانلودی، دکمه ی Download Other Formats را فشار دهید.
نرم افزار دانلود از یوتیوب
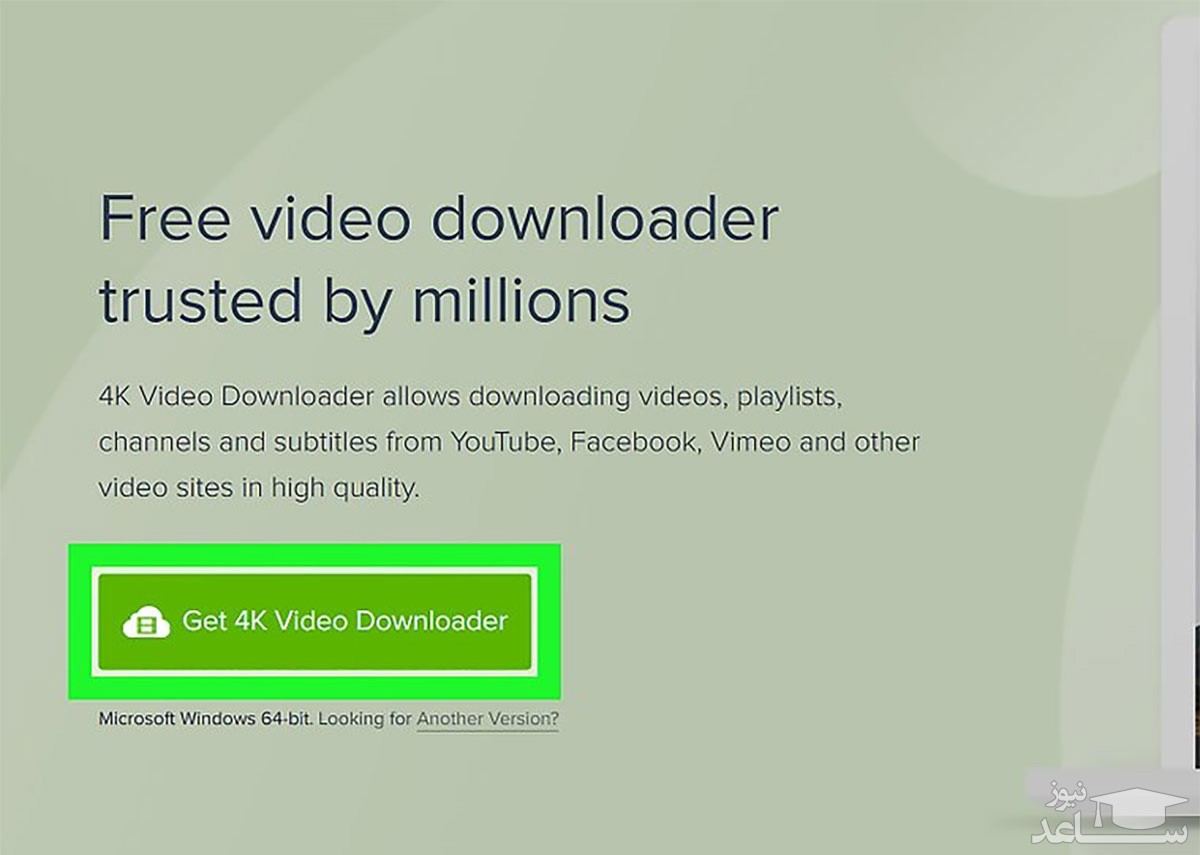
برخی کاربران، نرم افزار دانلود از یوتیوب را به روش های آنلاین ترجیح می دهند. برای این دسته از کاربران هم گزینه های متعددی وجود دارد. از مشهورترین انواع نرم افزار دانلود از یوتیوب می توان 4K Video Downloader را نام برد. برای دانلود از یوتیوب با لینک مستقیم با استفاده از این نرم افزار، مراحل زیر را انجام دهید:
۱- وارد وب سایت 4kdownload شوید و نرم افزار 4K Video Downloader را دانلود کنید. این نرم افزار برای هر دو سیستم عامل ویندوز و مک در دسترس قرار دارد. مراحل نصب را مانند نرم افزارهای دیگر در مک یا ویندوز دنبال کرده و سپس نرم افزار را اجرا کنید.
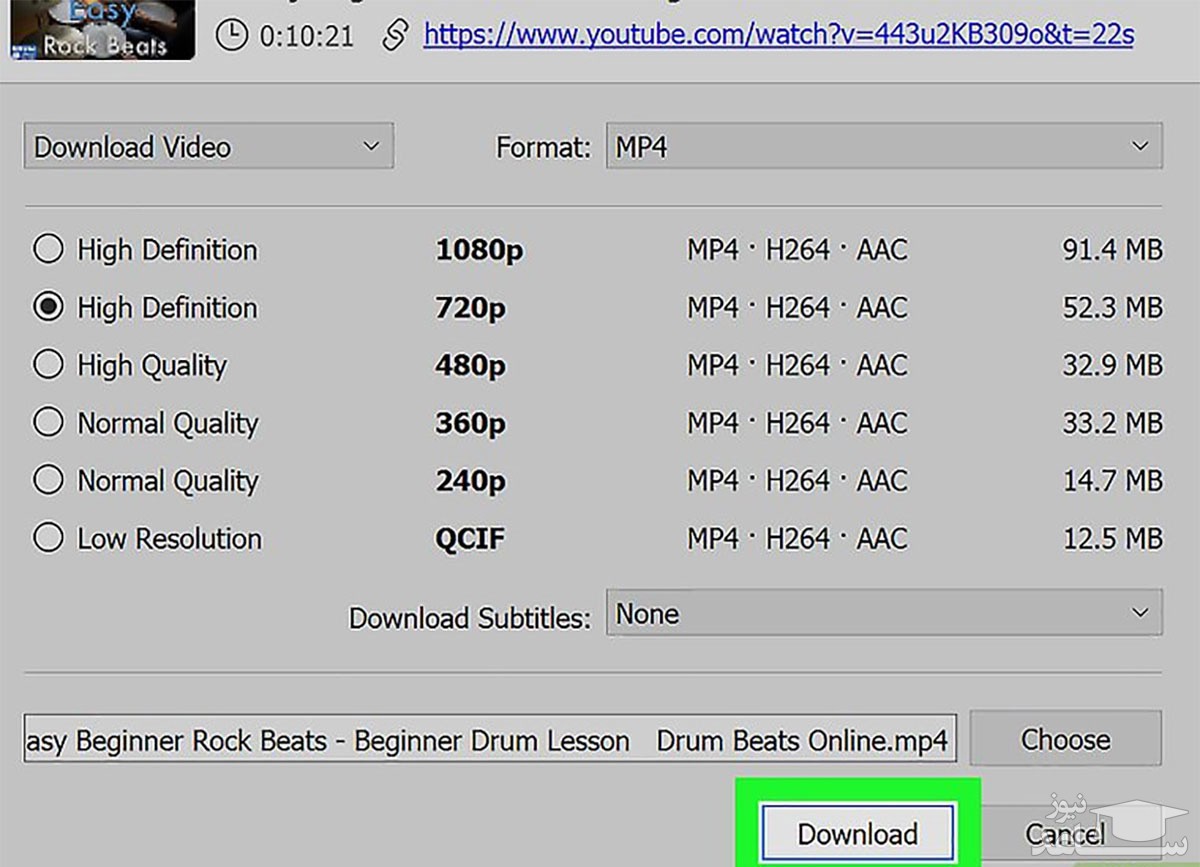
۲- وارد وب سایت یوتیوب شوید و ویدیوی مورد نظر خود را انتخاب کنید. آدرس صفحه ای که ویدئو در آن پخش می شود را کپی کرده و و طبق تصویر زیر در نرم افزار 4K Video Downloader وارد (Paste) کنید.
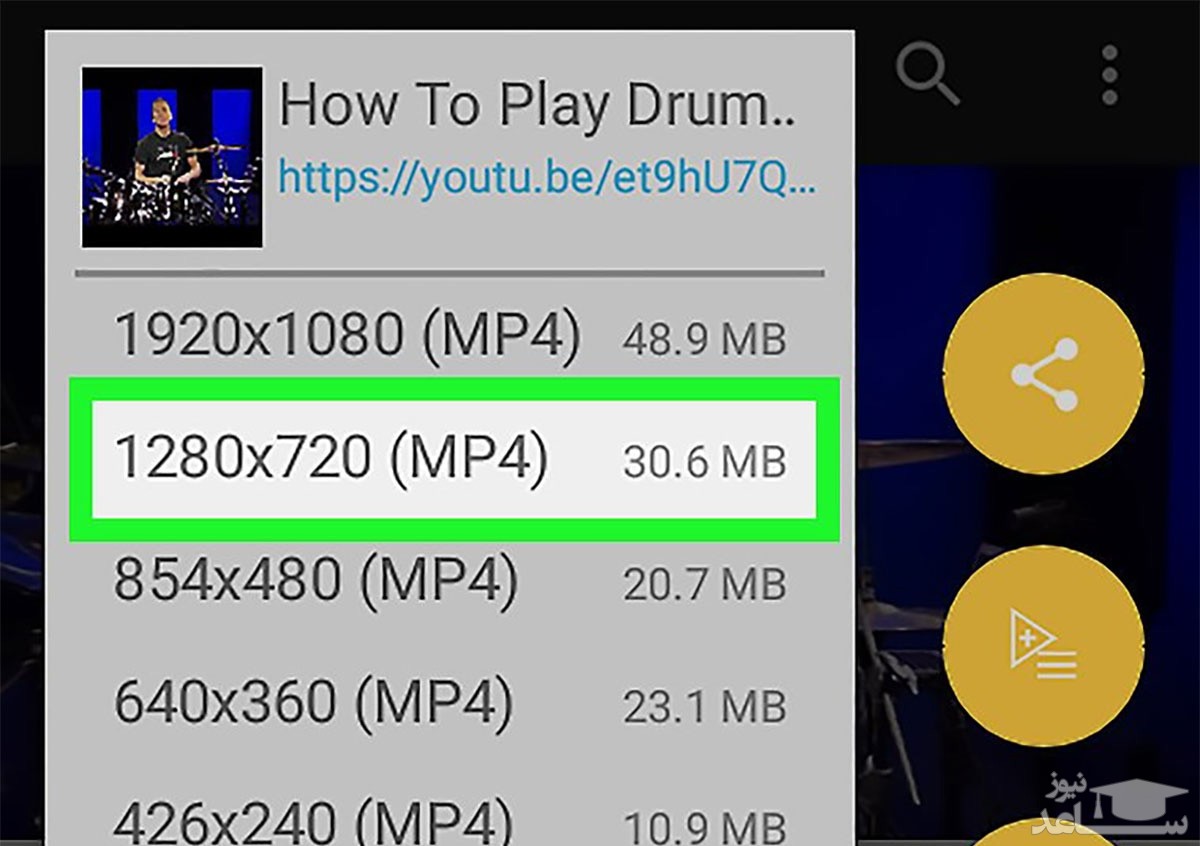
۳- از منوی Format، فرمت و کیفیت مورد نظر خود را انتخاب کنید. در مرحله ی آخر، روی دکمه ی Download کلیک کنید تا فرایند دانلود آغاز شود.
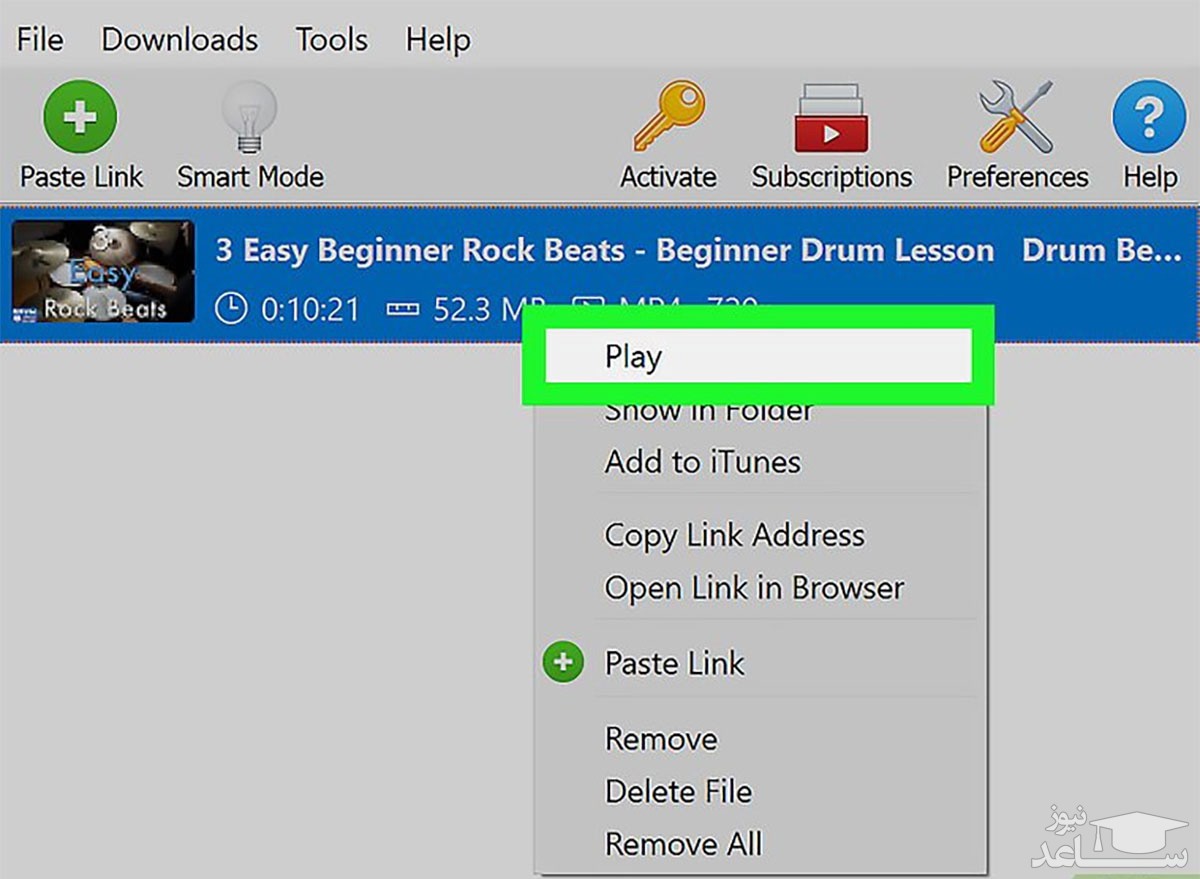
۴- پس از دانلود شدن ویدئو توسط نرم افزار 4K Video Downloader می توانید آن را از داخل همان نرم افزار اجرا کنید (کلیک راست و گزینه ی Play) یا پوشه ی دانلود را باز کرده و فایل را برای اشتراک یا انتقال به پوشه ای دیگر در کامپیوتر، انتخاب کنید (کلیک راست و انتخاب Show in Folder).
از نرم افزارهای محبوب دیگر که می توان برای دانلود از یوتیوب به کار گرفت می توان به VLC اشاره کرد. این نرم افزار متن باز به صورت رایگان در اختیار کاربران قرار دارد و با چند مرحله ی ساده در ویندوز و مک، عملیات دانلود را انجام می دهد. اگر برای شما هم این سؤال پیش آمده است که با استفاده از VLC چگونه از یوتیوب دانلود کنیم مراحل زیر را دنبال کنید:
۱- وارد وب سایت یوتیوب شوید و ویدیوی مورد نظر خود را پخش کنید. سپس آدرس ویدئو را برای وارد کردن در VLC کپی کنید.
۲- اگر نرم افزار VLC را روی کامپیوتر ندارید، آن را از این لینک دانلود کرده و نصب کنید. پس از اجرای نرم افزار، باید از بخش Network آن برای دانلود از یوتیوب بهره ببرید.
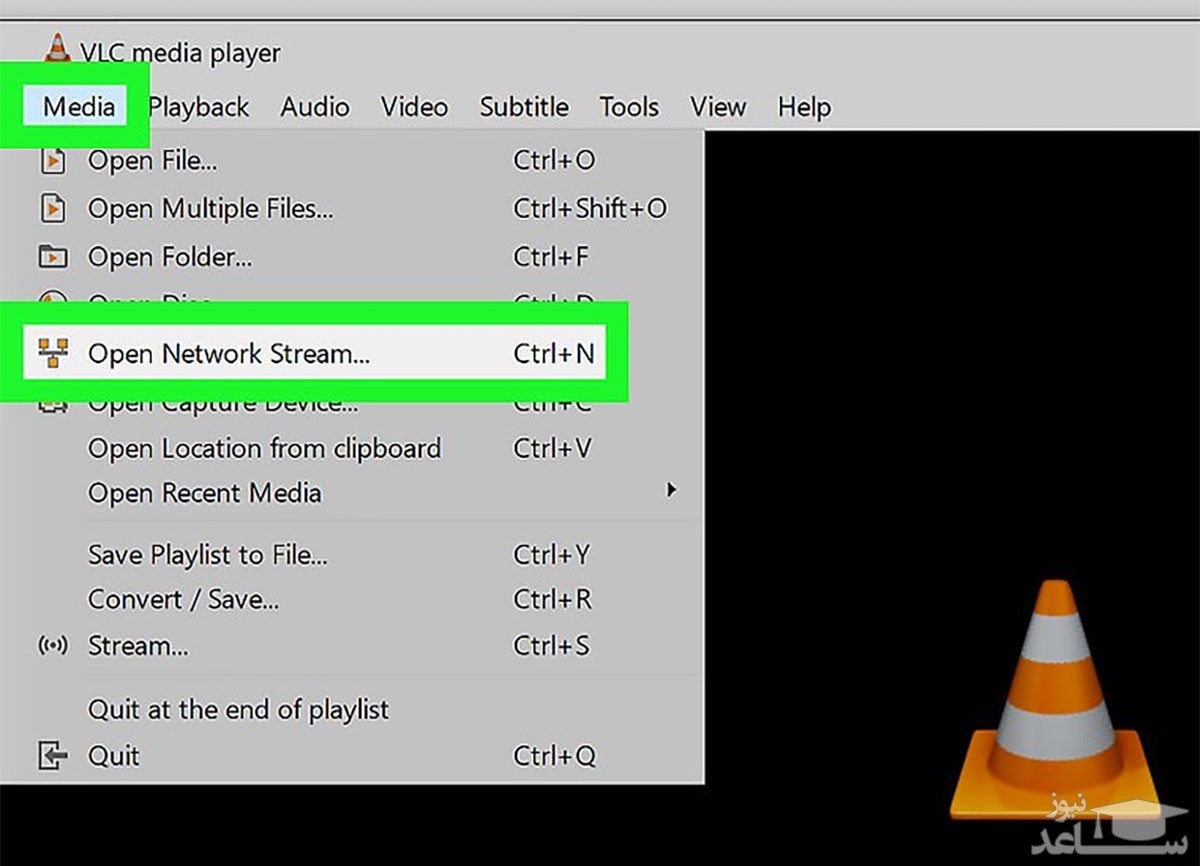
۳- در نسخه ی ویندوز VLC وارد منوی Media و سپس Open Network Stream شوید. اگر از کاربران مک هستید، آدرس File و سپس Open Network را دنبال کنید.
۴- در پنجره ی باز شده، آدرس ویدیوی مورد نظر را وارد کنید (کلیک راست و Paste) و Play (در ویندوز) یا Open (در مک) را انتخاب کنید. نرم افزار VLC، ویدیوی موردنظر را در داخل خود پخش می کند.
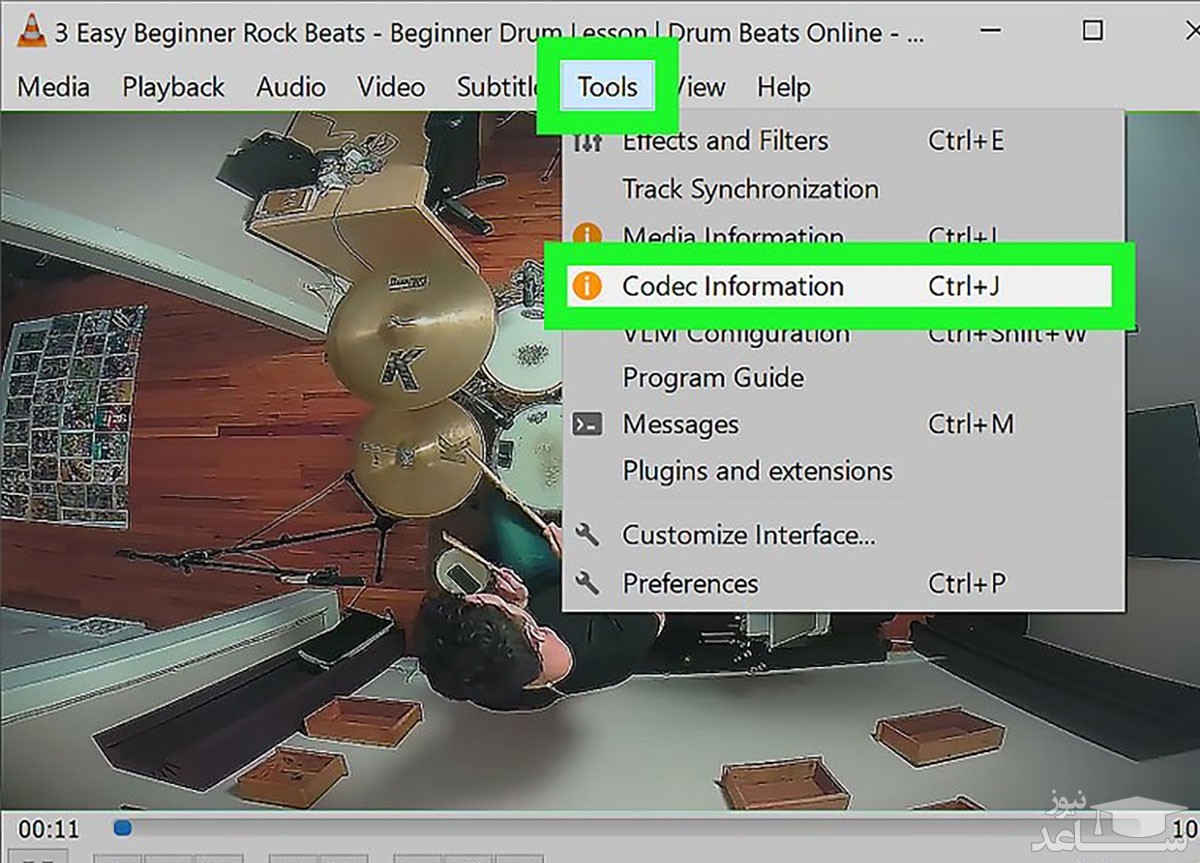
۵- در این مرحله باید اطلاعات مکانی ویدئو را پیدا کنید. در ویندوز وارد منوی Tools و سپس Codec Information شوید و در مک، منوی Window و سپس Media Information را انتخاب کنید.
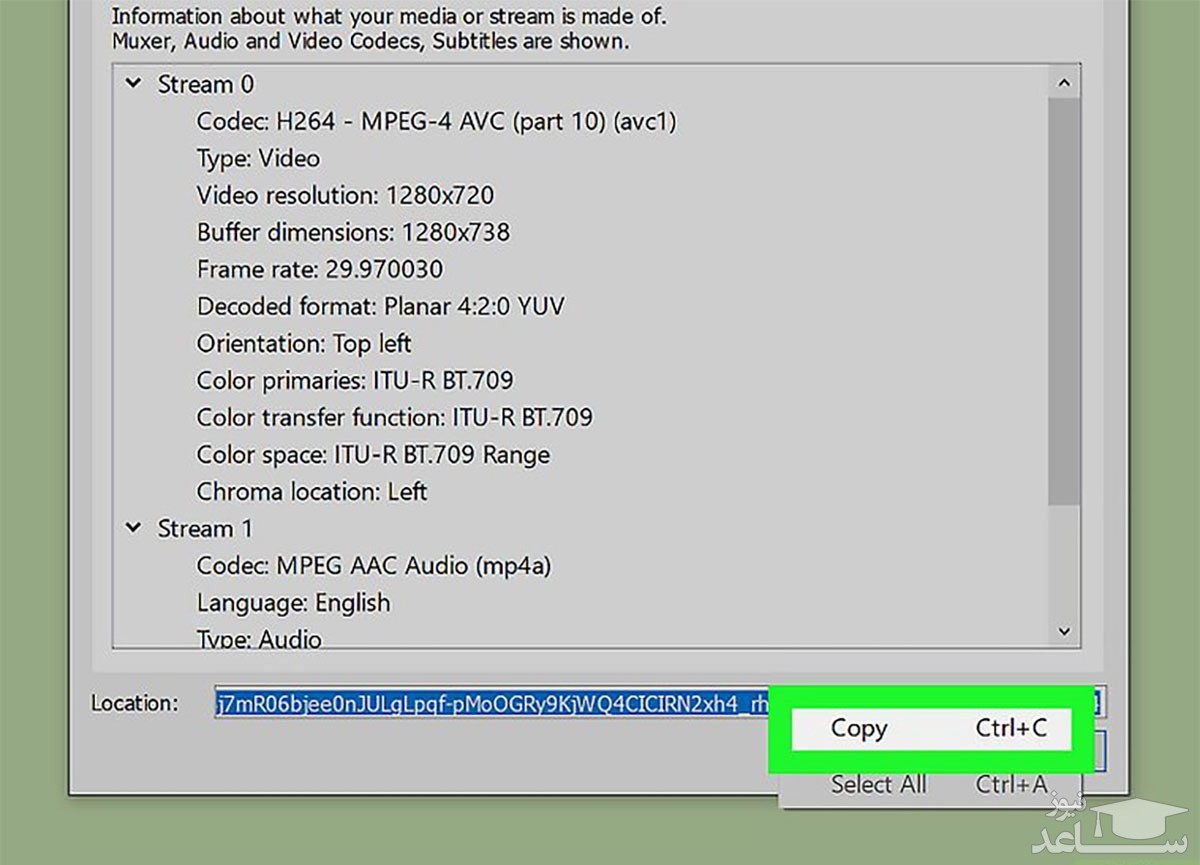
۶- از پایین پنجره، کل آدرس موجود در فیلد Location را کپی کنید (کلیک راست و Copy در ویندوز و کلیک راست و Open URL در مک). در ویندوز، آدرس کپی شده را در مرورگر وب خود وارد کنید. در مک نیز مرورگر به صورت پیش فرض آدرس را باز می کند.
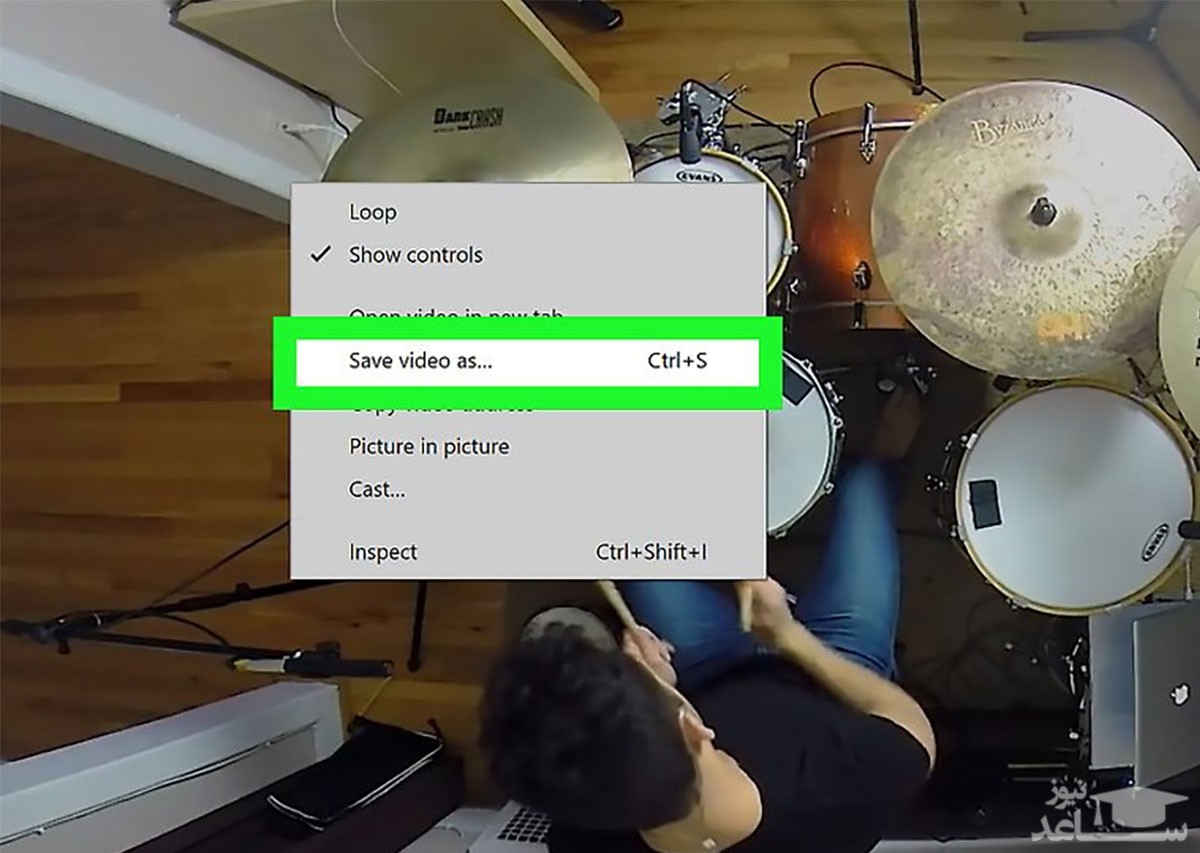
۷- همان طور که می بینید، ویدئو در مرورگر شما بدون بازکردن یوتیوب، پخش می شود، برای دانلود ویدئو، روی آن کلیک راست کرده و Save video as را انتخاب کنید. مرحله ی نهایی، انتخاب مکان ذخیره سازی فیلم است. فراموش نکنید که با این روش، امکان انتخاب کیفیت فیلم برای دانلود وجود ندارد.
اپلیکیشن دانلود فیلم از یوتیوب برای اندروید
همان طور که گفته شد، برای دانلود فیلم از یوتیوب، اپلیکیشن های اختصاصی هم وجود دارد. درواقع اپلیکیشن ها را می توان محبوب ترین روش دانلود از یوتیوب در اندروید دانست که به خاطر تعداد و تنوع بالا، کاربران آن ها را به سرویس های تحت وب ترجیح می دهند. از محبوب ترین سرویس ها می توان به TubeMate اشاره کرد که البته اپلیکیشن آن به صورت رسمی در پلی استور موجود نیست. به هرحال می توانید اپلیکیشن را به صورت مستقیم و به صورت پکیج APK از وب سایت TubeMate دانلود کنید.
برای دانلود فیلم از یوتیوب با استفاده از اپلیکیشن Tubemateدر اندروید، مراحل زیر را دنبال کنید.
۱- پس از دانلود و نصب اپلیکیشن، مجوزهای لازم را برای دسترسی به حافظه و فایل های گالری به اپلیکیشن بدهید.
۲- پس از اجرای اپلیکیشن TubeMate، با محیطی شبیه به اپلیکیشن خود یوتیوب برای اندروید مواجه می شوید. درنتیجه کار سختی برای دانلود ندارید و تنها باید ویدیوی مورد نظر را جست وجو کرده و پیدا کنید.
۳- پس از پیدا کردن و پخش ویدئو در اپلیکیشن، روی آیکن قرمز دانلود در کنار دکمه ی Save کلیک کرده و سپس، فرمت و کیفیت مورد نظر خود را انتخاب کنید.
۴- پس از انتخاب فرمت مورد نظر، با کلیک روی آیکن قرمز در منوی سمت راست، فرایند دانلود فیلم از یوتیوب شروع می شود. اگر در مراحل دانلود، با پیام هایی برای دانلود فایل یا اپلیکیشن های دیگر روبه رو شدید، آن ها را نادیده بگیرید. به خاطر رایگان بود TubeMate، این نرم افزار با نمایش تبلیغات درآمدزایی می کند. هرچند تبلیغات پیشنهادی بدافزار نیستند و از پلی استور دانلود می شوند، اما نیازی به دریافت آن ها برای دانلود فیلم از یوتیوب نیست.
در آیفون و آیپد چگونه از یوتیوب دانلود کنیم
آیفون برخلاف گوشی های اندرویدی امکان ذخیره ی مستقیم و آسان ازطریق اپلیکیشن را ندارد. درواقع محدودیت های سیستم عامل iOS امکان نوشتن اپلیکیشن برای این منظور و توزیع آن در اپ استور را از بین می برد. دانلود اپلیکیشن از منابع ناشناس برای گوشی آیفون هم به آسانی اندروید نیست و درنهایت، باید به دنبال راهی دیگر برای دانلود فیلم از یوتیوب باشید. برای این منظور، اپلیکیشنی را در آیفون نصب کرده و از طریق آن اپلیکیشن و وب سایت Keepvid، ویدئو را در آیفون دانلود می کنیم. برای دانبود فیلم از یوتیوب در آیفون، مراحل زیر را دنبال کنید.
۱- در اپ استور، عبارت readdle را جست وجو کرده و اپلیکیشن Documens by Readdle را دانلود و نصب کنید.
۲- ویدیوی مورد نظر را در اپلیکیشن یوتیوب یا مرورگر آیفون یا آیپد باز و مانند آموزش KeepVid، با انتخاب گزینه ی Share و سپس Copy Link، لینک ویدئو را کپی کنید.
۳- اپلیکیشن Documents را که در مرحله ی اول نصب شد، اجرا کرده و روی آیکن پایین سمت راسمت (طبق تصویر زیر) کلیک کنید. این آیکن، مرورگر داخلی اپلیکیشن را اجرا می کند که باید وب سایت Keepvid.pro را در آن باز کنید.
4- مراحل بعدی مانند دانلود از KeepVid در کامپیوتر است و تنها باید آدرس کپی شده در مرحله ی دوم را در فیلد وب سایت وارد کنیم. پس از دانلود، فیلم وارد اپلیکیشن Documents می شود و می توانید از آنجا آن را اجرا کنید.
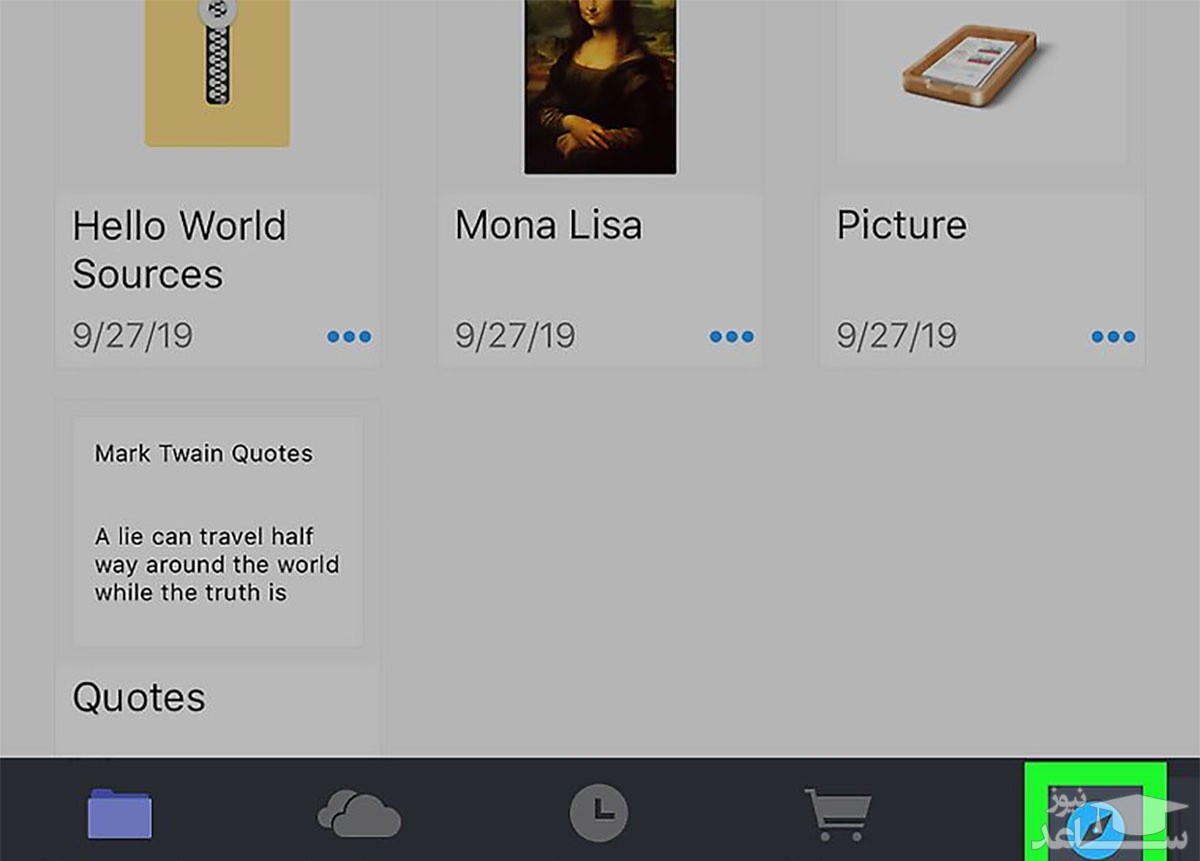
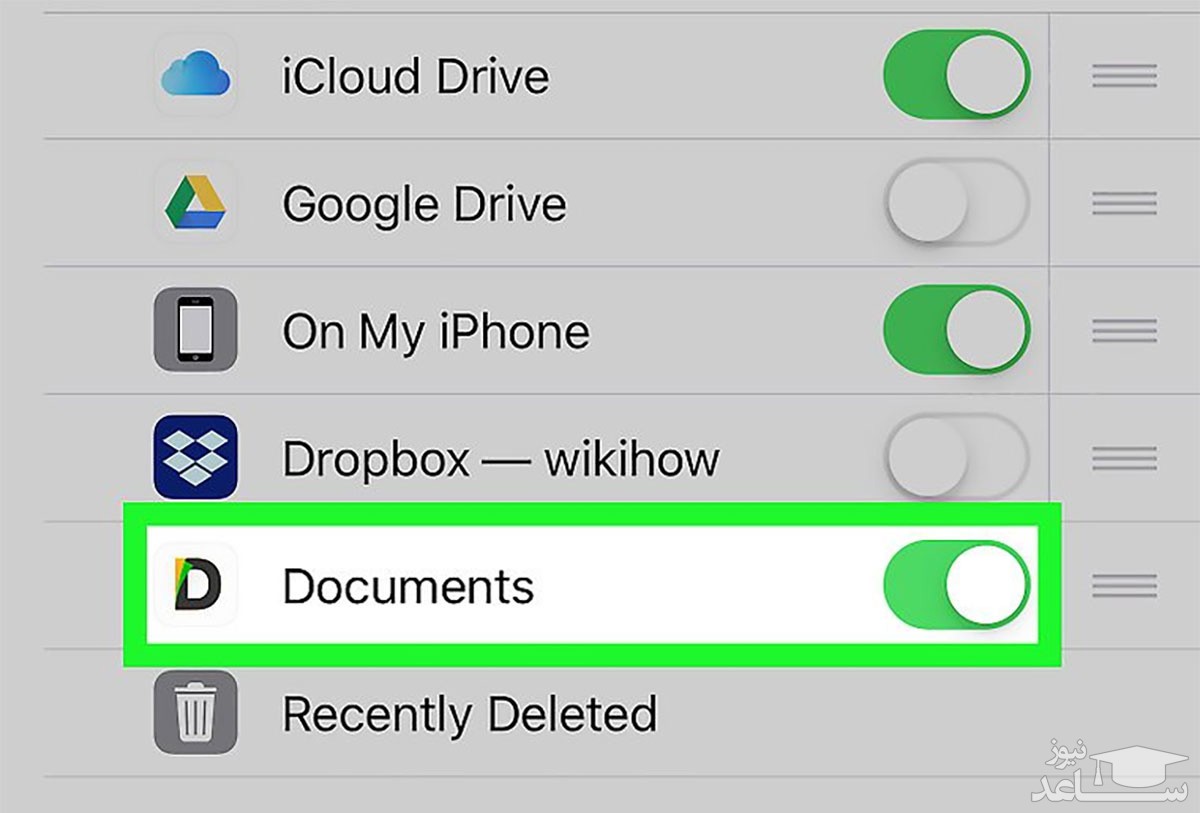
۵- برای آسان تر شدن دسترسی به ویدیوهای دانلودشده، می توان اپلیکیشن Documents را به اپلیکیشن پیش فرض Files در iOS یا iPadOS اضافه کرد. برای این منظور، پس از بازکردن اپلیکیشن، Files را باز کرده و از منوی پایینی، Browse را انتخاب کنید. مراحل بعدی شامل انتخاب گزینه ی Edit و سپس فعال کردن Documents است. از این به بعد می توانید فایل های دانلودشده در اپلیکیشن Documents را در اپلیکیشن پیش فرض Files مشاهده کنید.
ربات دانلود از یوتیوب
قطعا تاکنون با این سؤال مواجه شده اید که با استفاده از تلگرام چگونه از یوتیوب دانلود کنیم و شاید هم گزینه هایی را در نظر داشته باشید. از مشهورترین نمونه های ربات دانلود از یوتیوب می توان ربات utubebot را نام برد. برای دانلود از یوتیوب با استفاده از ربات مذکور، مراحل زیر را دنبال کنید.
۱- ربات utubebot را در تلگرام جست وجو کرده و پس از پیدا کردن و وارد شدن به آن، دستور start را انتخاب کنید.
۲- وب سایت یوتیوب را باز کرده و آدرس صفحه ی فیلم مورد نظر خود را کپی کنید.
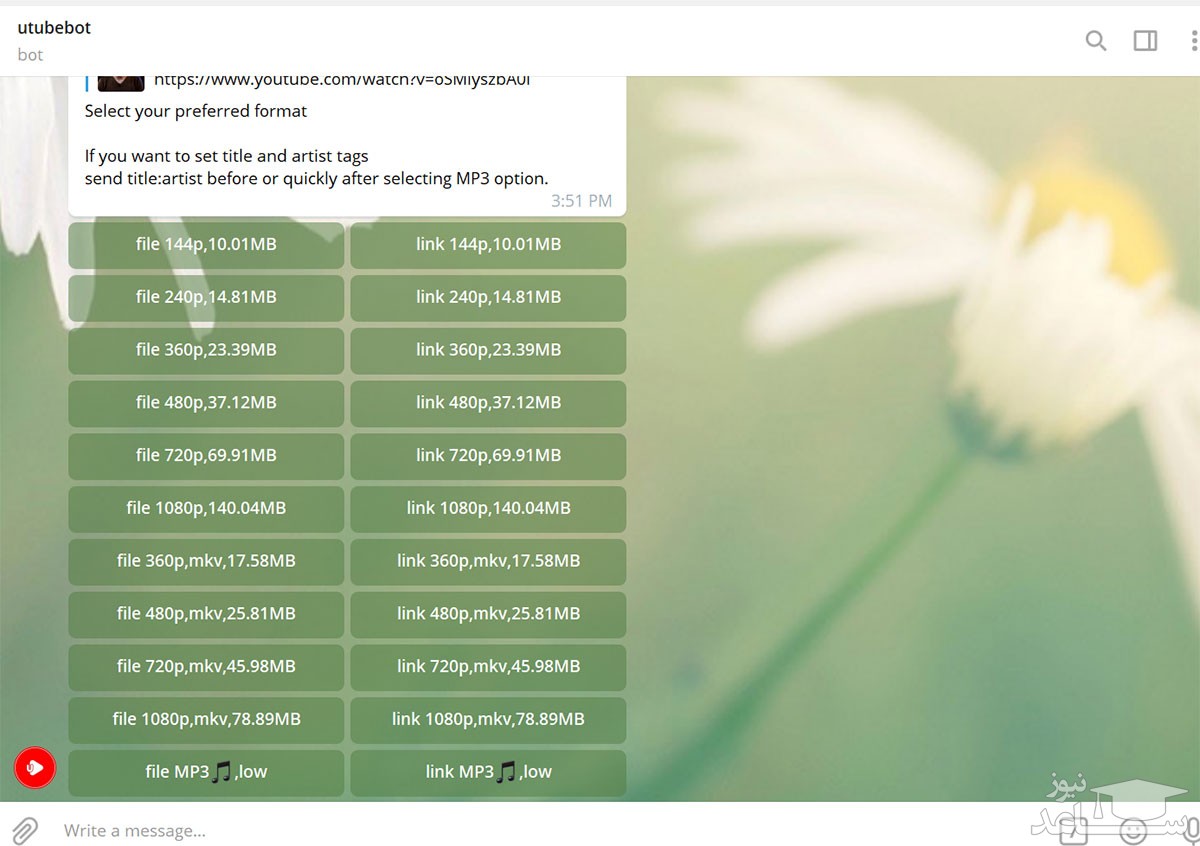
۳- آدرس فیلم در وب سایت یوتیوب را در پنجره ی ربات وارد (Paste) کنید.
۴- همان طور که می بینید، ربات انواع فرمت ها و کیفیت ها را برای دانلود ویدئو از یوتیوب پیشنهاد می دهد. فرمت و کیفیت مورد نظر خود را با کلیک کردن روی دکمه ی مربوط به آن، انتخاب کنید.
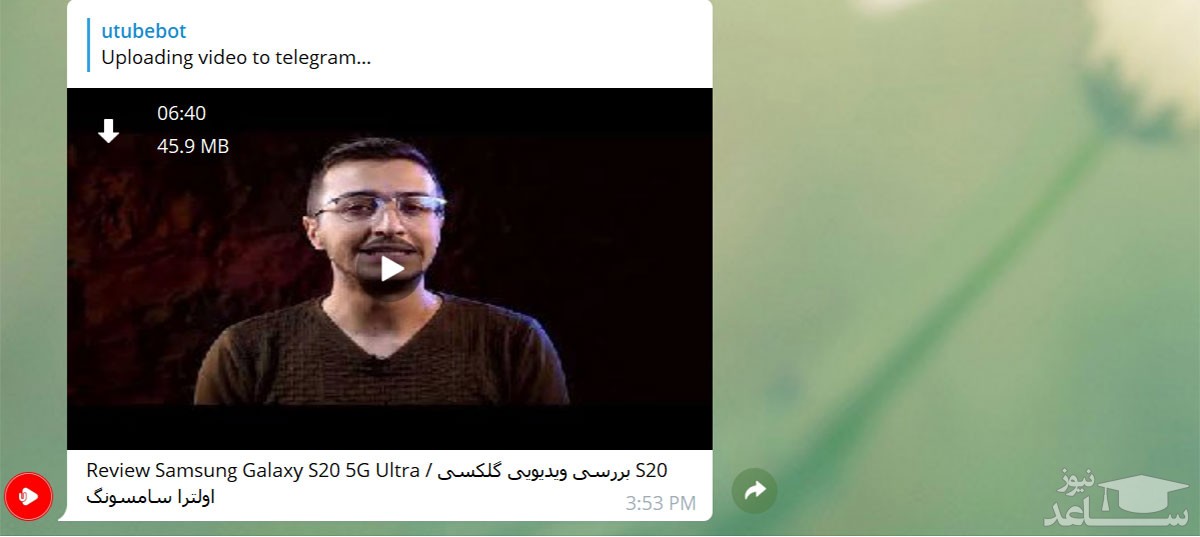
۵- پس از گذشت چند لحظه (بسته به حجم فیلم)، فیلم مورد نظر از یوتیوب به صورت یک فیلم داخل تلگرام در ربات ارسال می شود که می توانید آن را در کامپیوتر شخصی یا گوشی هوشمند دانلود کنید.
همان طور که گفته شد، راهکارهای متعددی برای دانلود فیلم از یوتیوب وجود دارد و در بالا، روش های مرسوم و پرطرفدار دانلود از این سرویس را شرح دادیم. اگر شما هم روش هایی کاربردی برای دانلود از یوتیوب می شناسید، در بخش نظرها آن ها را با دیگر کاربران به اشتراک بگذارید.
پرسش های متداول
آیا امکان دانلود از یوتیوب بدون نرم افزار وجود دارد؟
بله، وجود دارد. همان طور که در این مقاله آموزش داده شده است، راه های ساده ای وجود دارد که از طریق کامپیوتر و بدون استفاده از هیچ نرم افزاری، ویدیوهای موردنظر خود را از یوتیوب دانلود کنید.
آیا امکان دانلود از یوتیوب با گوشی های اندرویدی وجود دارد؟
بله. برای دانلود از یوتیوب با گوشی های اندرویدی راه های زیادی وجود دارد که راحت ترین راه، استفاده از اپلیکیشن های مخصوص دانلود از یوتیوب محسوب می شود. در این مقاله یکی از محبوب ترین آن ها را به طور کامل معرفی کرده ایم.
آیا با آیفون یا آیپد هم می توان از یوتیوب دانلود کرد؟
بله؛ البته به دلیل محدودیت های سیستم عامل اپل، امکان ذخیره مستقیم فایل های ویدیویی روی آیفون یا آیپد وجود ندارد. برای این عبور از این محدودیت ها و دانلود از یوتیوب با آیفون یا آیپد راه حلی وجود دارد که در این مقاله به طور کامل توضیح داده ایم.
پینگ دستوری است که از آن برای سنجش فاصله ی زمانی اتصال بین دو دستگاه در شبکه استفاده می شود. دستور ping در تمام سیستم عامل ها قابل استفاده است. بسیاری از بازی های آنلاین، از پینگ برای سنجش فاصله ی زمانی به صورت تصویری بهره می برند.
پینگ چیست و چه کاربردی دارد؟
پینگ را نمی توان در دسته ی عوامل کارایی دانست. همان طورکه گفته شد، پینگ ابزاری برای اندازه گیری تأخیر اتصال بین کامپیوتر شما و سرور از راه دور است. پینگ می گوید ارسال هر پکت (بسته) داده از کامپیوتر شما به سرور و دریافت پاسخ آن، چقدر طول می کشد. قطعا تاکنون این رخداد را تجربه کرده اید که پس از کلیک روی لینکی، صفحه ی وب به صورت آنی بارگذاری نمی شود. درواقع، تأخیری کوتاه بین کلیک و بازشدن صفحه وجود دارد که البته برخی مواقع کوتاه نیست و حتی شاید یک دقیقه طول بکشد. کامپیوتر باید درخواست بارگذاری صفحه را به سرور ارسال و پاسخ آن را دریافت کند. رفت وآمد پکت داده به زمان نیاز دارد و پینگ زمان مذکور را اندازه گیری می کند.
پینگ اهمیت زیادی در بازی های آنلاین دارد و نشان دهنده ی زمانی است که طول می کشد تا حرکت شما در بازی، در سرور اصلی ثبت و اجرا شود. به عنوان مثال، اگر بازی آنلاینی را با پینگ ۲۰ میلی ثانیه اجرا کنید، دستورها و حرکت های شما تقریبا بدون وقفه و آنی اجرا می شوند. اگر پینگ به رقمی مثلا ۲۰۰ میلی ثانیه ای برسد، حرکت ها با تأخیر زیادی اجرا می شوند و نمی توانید با بازدهی و قدرت لازم بازی کنید. به همین دلیل، پینگ هر کاربر به صورت آنی هنگام انجام بازی آنلاین به او نمایش داده می شود تا سرعت و بازدهی خود را تخمین بزند. درنهایت، پینگ کمتر به معنای سرعت بیشتر خواهد بود و کاهش پینگ از اقدام هایی است که اغلب کاربران دنیای اینترنت به دنبال آن هستند.
پینگ برای چه چیزی استفاده می شود؟
پینگ صرفا ابزاری برای اندازه گیری «عملکرد» نیست. ویژگی بخصوص پینگ اندازه گیری زمان تاخیر اتصال بین کامپیوتر شما با دستگاه مقصد (Remote Device) است. پینگ مدت زمان ارسال بسته (Packet) از رایانه شما، رسیدن آن به دستگاه مقصد و ارسال مجدد آن به رایانه شما را مشخص می کند.
آیا تا کنون به این نکته توجه کرده اید که وقتی در یک وب سایت بر روی لینکی کلیک می کنید، صفحه ی مقصد بلافاصله باز نمی شود؟ در این حالت یک وقفه ی زمانی -که زمان تاخیر است- وجود دارد. درخواست مشاهده ی صفحه ی جدید باید از سوی رایانه ی شما ارسال شود و سپس صفحه مورد نظر برای شما بارگذاری می گردد. زمان کوتاهی برای ارسال هر بسته ی داده ای (Packet Data) از کامپیوتر شما به کامپیوتر مقصد طول خواهد کشید. پینگ به شما اجازه می دهد این زمان را اندازه گیری کنید.
این موضوع در هنگام اجرای بازی های آنلاین بیشتر قابل درک است. مثلا اگر شما قصد انجام یک بازی آنلاین را دارید که نیاز به پینگ ۲۰ میلی ثانیه دارد، زمان تاخیرتان باید بسیار کوتاه باشد. در این صورت اعمالی که در بخش های مختلف بازی انجام می دهید تقریبا بلافاصله انجام خواهند شد. اگر پینگ شما بالاتر و مثلا ۲۰۰ میلی ثانیه است، اعمالی که در بازی انجام می دهید با یک فاصله ی زمانی انجام می شوند و در نتیجه شما نسبت به سایر افرادی که به طور همزمان با آنها بازی می کنید، عقب می مانید.
این که چرا در بازی های آنلاین چند نفره، زمان پینگ خیلی مهم است اینجا مشخص می شود. پینگ به شما کمک می کند تا میزان کیفیت اتصال خود را در شبکه بسنجید و عملکرد و کارایی مورد انتظار سرور را دریابید. هر چه پینگ کوتاه تر باشد بهتر است و به معنی زمان تاخیر کمتر است، در نتیجه اتصالی پرسرعت تر بین رایانه ی شما و سرور برقرار می شود. این موضوع قابل تعمیم به تمام فعالیت های آنلاین شماست خواه انجام یک بازی آنلاین باشد و خواه مرور یک وب سایت.
گاهی اوقات ممکن است پینگ فقط به صورت «تاخیر زمانی» به نمایش درآید. ولی در بازی های آنلاین برای اینکه مشخص شود پینگ شما چقدر خوب است معمولا به صورت یک رنگ برای شما نمایان خواهد شد که شامل سه رنگ سبز (خوب)، زرد (متوسط) و قرمز (ضعیف) است.
پینگ چگونه کار می کند؟
در ادامه به صورت خیلی ساده طرز کار پینگ را با هم مرور می کنیم:
رایانه ی شما بسته های داده ای کوچکی -که در قوانین شبکه، بسته (Packet) نامیده می شوند- را به رایانه ی مقصد ارسال می کند.
رایانه ی مقصد بسته ی ارسالی شما که نیاز به پاسخ دارد را دریافت می کند.
رایانه ی مقصد یک بسته به رایانه ی شما ارسال می کند.
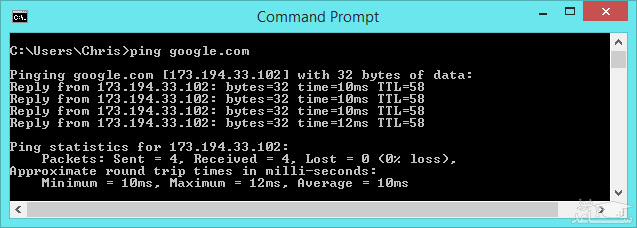
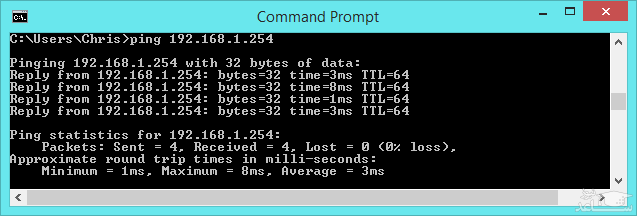
و این مراحل برای هر پینگ تکرار می شود. پینگ به شما اجازه می دهد مدت زمان رفت و برگشت بسته ها را بین رایانه ی خود و رایانه ی مقصد، اندازه بگیرید. به عنوان مثال همانطور که در تصویر زیر می بینید ما از Command Prompt ویندوز برای ارسال پینگ به گوگل (www.Google.com) استفاده می کنیم. این دستور ۴ بسته یا ۴ دستور پینگ جداگانه را ارسال می کند. برای ۳ پینگ اول، زمان ۱۰ میلی ثانیه و برای پینگ آخر ۱۲ میلی ثانیه است. به زبان ساده تر این یعنی برای ارسال ۳ بسته ی اول به گوگل و دریافت آن توسط رایانه ی ما، مدت زمان ۱۰ میلی ثانیه صرف شده در حالیکه برای بسته ی آخر، همین مراحل ۱۲ میلی ثانیه به طول انجامیده است. اما چرا پینگ چهارم بیشتر طول کشید؟ خب دلایل زیادی می تواند داشته باشد. ممکن است سرورهای گوگل اینکار را آهسته تر انجام داده باشند، امکان دارد روتر اینترنتی ای که بین ما و سرورهای گوگل قرار دارد بیشتر از حد معمول مشغول باشد، میزان ورودی اطلاعات توسط وای فای ما ممکن است نوسان داشته باشد و دلایل فراوان دیگر. البته برخی از این نوسانات رایج و طبیعی هستند.
هر پینگ یک درخواست ICMP Echo است
هرگاه شما یک پینگ ارسال می کنید، رایانه ی شما یک درخواست ICMP Echo ارسال می کند. IMCP که مخفف Internet Control Message Protocol به معنای «پروتکل کنترل پیام اینترنت» است و این پروتکل اساسا در میان دستگاه هایی که به یکدیگر شبکه شده اند استفاده می شود. در نتیجه دستگاه های مذکور می توانند با یکدیگر ارتباط داشته باشند. هر بسته، درخواست یک Echo می کند یا به بیانی دیگر، یک پاسخ ارسال می کند. به طور کلی هنگامی که سرور مقصد پینگی دریافت می کند، یک پیام مختص خود را به رایانه ی مبدا ارسال می نماید. وقتی شما دستور ping را اجرا می کنید در هر سطر یک پینگ و پاسخ آن را مشاهده خواهید نمود.
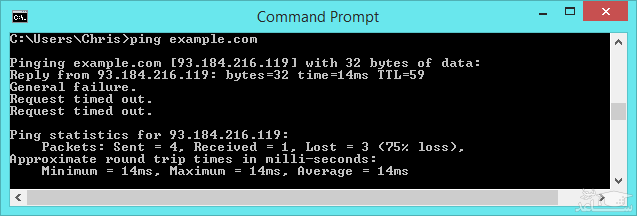
به هر حال همه ی سرورها و رایانه ها قابلیت پاسخ به یک بسته ی درخواست ICMP echo را ندارند و این ویژگی ممکن است در آن ها تعبیه نشده باشد. بنابرین در چنین شرایطی وقتی سرور قادر به پاسخ دادن به درخواست شما در لحظه ی ارسال پینگ نباشد، با پیام «Request timed out» به معنی «درخواست به پایان رسیده است» روبرو خواهید شد. متاسفانه امروزه از پروتکل ICMP برای حملات تکذیب سرور (DDoS attacks) نیز استفاده می شود.
مشاهده ی بسته های از بین رفته
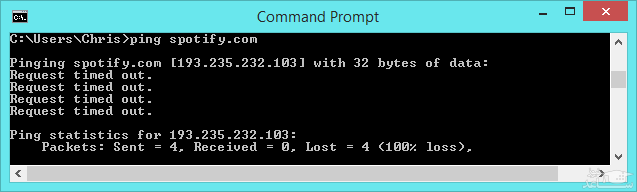
پینگ می تواند به شما کمک کند تا بسته هایی که از بین رفته اند را نیز ببینید. برای مثال فرض کنید دستور ping را اجرا کرده اید و با یکسری پاسخ های مختلف و خطوط «Request timed out» روبرو شده اید. این یعنی برخی از بسته ها توسط رایانه مقصد دریافت نشده اند، یا پاسخ های سرور به رایانه ی شما ارسال نشده. برخی بسته ها نیز ممکن است در طول مسیر ارسال و دریافت از بین بروند.
واضح است که از بین رفتن بسته ها باید جایی بین شما و رایانه ی مقصد اتفاق افتاده باشد، مثلا در شبکه ی رایانه های مقصد، یا جایی در روتر مابین رایانه ی شما و رایانه ی مقصد، و یا خدمات دهنده ی اینترنت (ISP) شما. حتی ممکن است در شبکه ی خانگی شما این بسته ها از بین رفته باشند. اگر در هنگام وبگردی یا انجام بازی های آنلاین با مشکل روبرو می شوید -بخصوص وقتی برای رفتن به یک صفحه ی وب جدید چند بار بر روی لینک آن کلیک می کنید و صفحه ی مورد نظر بالا نمی آید- می توانید از دستور پینگ استفاده نمایید تا بفهمید آیا بسته های داده ای به سمت سرور ارسال می شوند یا خیر. هنگامی که از بین رفتن بسته های داده ای برای شما رخ می دهد برای نتیجه گیری بهتر در مورد کارکرد درست شبکه، می توانید چندین بار دستور پینگ را برای سرور های مختلف اجرا نمایید.
پینگ همچنین مقدار از بین رفتن بسته ها را مشخص می کند. برای مثال بسته ی اولی به سرور رسیده و پاسخ آن برای ما ارسال می شود و سه بسته ی دیگر از بین می روند، در این حالت دستور پینگ نشان می دهد که ۷۵ درصد بسته ها و در واقع سه چهارم آن ها از بین رفته اند.
آیا پینگ صفر امکانپذیر است؟
همانطور که گفتیم هرچه پینگ کوتاه تر باشد بهتر است. پینگ صفر یعنی رایانه ی ما به صورت بی وقفه با رایانه ی مقصد در ارتباط باشد.
با توجه به قوانین فیزیک، حتی بخش بسیار کوچکی از یک داده، که بتوان آن را بسته نامید، برای انجام مسیر رفت و برگشت زمانی را نیاز خواهد داشت. حتی اگر داده های شما در کابل های فیبر نوری ارسال و دریافت شوند، با محدودیت سرعت نور مواجه هستند. از سویی دیگر نیز به دلیل وجود روترهای واسطه که بسته های داده ای را دریافت کرده و آنها را به اتصالات دیگر می فرستند باز هم در رفت و آمد بسته ها محدودیت ایجاد می شود.
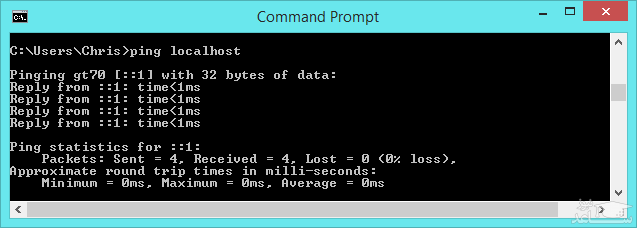
اگر شما قصد اجرای دستور پینگ را در سرور محلی (Localhost) بر روی رایانه خود داشته باشید، در واقع شما از رایانه خود خواسته اید تا بسته ها را از خودش به خودش ارسال کند و در این حالت شما زمان پینگ را صفر میلی ثانیه خواهید دید. به عبارتی این یعنی رایانه ها می تواند با خودشان به صورت بلادرنگ ارتباط داشته باشند. البته در این شرایط نیز باز هم نمی توان زمان صفر مطلق را برای انجام پینگ انتظار داشت، چرا که برای اجرای دستور توسط نرم افزار مربوطه زمانی هر چند بسیار کوتاه، نیاز خواهد بود. اما به هر حال این زمان آنقدر کم است که می توانیم از آن چشم پوشی کرده و زمان صفر میلی ثانیه برای ارتباط رایانه با خودش را در نظر بگیریم.
هنگامی که طول کابل ها، تعداد روترها و فاصله بین رایانه ی مبدا و مقصد را بیشتر کنید قطعا دیگر نمی توانید انتظار پینگ صفر را داشته باشید. می توانید این مورد را بر روی روتر خانگی خود بررسی کنید. ما دستور پینگ را به روتر خانگی خود، که در یک اتاق نسبتا کوچک قرار دارد و به صورت بی سیم به آن متصل هستیم ارسال کردیم و زمان متوسط پینگ ۳ میلی ثانیه و کمترین زمان به دست آمده ۱ میلی ثانیه بود زیرا برای ارتباط با سایر دستگاه ها به مقداری زمان نیاز است. اگر به صورت بی سیم به روتر متصل نباشیم و فقط بخواهیم با آن ارتباط برقرار کنیم، زمان پینگی نزدیک به صفر میلی ثانیه را خواهیم داشت، و همچنین برای ارسال بسته به شبکه ی خدمات دهنده ی اینترنت، و بازگشت آن به سمت روتر و اتصال به اینترنت مقداری زمان نیاز خواهد بود.
در نهایت بگذارید خیالتان را راحت کنیم، شما نمی توانید پینگی با زمان صفر داشته باشید. این محدودیت به دلیل قوانین فیزیک است. ما نمی توانیم اطلاعات را بلادرنگ انتقال دهیم – مگر با استفاده از قوانین کوانتومی. اگر بتوانیم راهی برای انتقال اطلاعات در بستر اینترنت با استفاده از قوانین کوانتومی پیدا کنیم آنگاه می توان به پینگ صفر دست یافت. اما این موضوع نیز فعلا در حد یک نظریه است و نیازی نیست نفستان را برای رسیدن به این موفقیت در سینه حبس کنید! پس آرام باشید و نفسی عمیق بکشید!
اگر شما هم جز افرادی هستید که در پایان هر ایمیلی که ارسال میکنید، نام و نام خانوادگی و یا اطلاعات تماس خود را درج میکنید، میتوانید از امکان درج امضا در جیمیل استفاده کنید تا بهطور خودکار اطلاعات مدنظرتان در پایان هر ایمیل ارسالی لحاظ شود. این کار تضمین میکند که هیچگاه درج این اطلاعات مهم فراموش نشوند.
چگونه چند امضای متفاوت به جیمیل اضافه کنیم
پشتیبانی جیمیل از تنها یک امضا همواره برای برخی کاربران مشکل ساز بوده است؛ زیرا کاربر در شرایطی که بخواهد ایمیل های مختلف را به شکل های متفاوتی به پایان ببرد با محدودیت مواجه است؛ به عنوان مثال ممکن است کاربر بخواهد یک دعوت از طرف دوستانش را به شکل متفاوتی نسبت به درخواست های کاری پاسخ دهد.
خوشبختانه گوگل به تازگی راه حلی برای محدودیت امضا در جیمیل ارائه داده؛ این شرکت امروز ویژگی جدیدی را در سرویس ایمیل خود معرفی کرده است که به کاربران اجازه ی تعریف چندین امضا برای درج در انتهای ایمیل می دهد. اضافه شدن قابلیت جدید به جیمیل و سرویس ابری G Suite از امروز آغاز شده است و تا دو هفته ی دیگر همه ی کاربران به آن دسترسی خواهند داشت.
به گفته ی گوگل در اختیار داشتن چندین امضا، به کاربر اجازه ی دهد تا در موقعیت های مختلف، امضای مناسبی به انتهای ایمیل خود اضافه کند. به عنوان مثال کاربر می تواند از یک امضای رسمی شامل شماره تماس و آدرس برای ایمیل های مربوط به شرکت یا گروه کاری خود استفاده کند و در انتهای ایمیل های شخصی امضای دیگری درج کند.
برای تعریف چندین امضا کافی است جیمیل را باز کنید و با کلیک روی آیکون چرخ دنده وارد بخش تنظیمات شوید. سپس از تب General عنوان Signature را پیدا کرده و روی گزینه ی Create New کلیک کنید. کاربر می تواند یک امضا را به عنوان امضای پیش فرض انتخاب کند. برای تغییر دادن امضای پیش فرض در حین نوشتن متن ایمیل کافی است با کلیک روی آیکون امضا در نوارابزارها موجود در بخش پایینی پنجره ی Compose، در منوی ظاهر شده از بین امضاهای از پیش تعیین شده، مورد مناسب را انتخاب کنید.
امکان انتخاب از بین چندین امضا مخصوصا برای کسانی که از کلاینت های ایمیل برای ارتباط با همکاران و خانواده یا دوستان نزدیک استفاده می کنند بسیار کاربردی است.
آمار در دو شاخه آمار توصیفی و احتمالات و آمار استنباطی بحث و بررسی می شود. احتمالات و تئوریهای احتمال اساسا از دایره بحث ما خارج است. همچنین آمار توصیفی مانند فراوانی، میانگین، واریانس و … نیز مفروض در نظر گرفته شده اند.
۱- آمار استنباطی و آمار توصیفی
در یک پژوهش جهت بررسی و توصیف ویژگیهای عمومی پاسخ دهندگان از روش های موجود در آمار توصیفی مانند جداول توزیع فراوانی، در صد فراوانی، درصد فراوانی تجمعی و میانگین استفاده میگردد. بنابراین هدف آمار توصیفی یا descriptive محاسبه پارامترهای جامعه با استفاده از سرشماری تمامی عناصر جامعه است.
در آمار استنباطی یا inferential پژوهشگر با استفاده مقادیر نمونه آماره ها را محاسبه کرده و سپس با کمک تخمین و یا آزمون فرض آماری، آماره ها را به پارامترهای جامعه تعمیم می دهد.برای تجزیه و تحلیل داده ها و آزمون فرضیه های پژوهش از روش های آمار استنباطی استفاده می شود.
پارامتر شاخص بدست آمده از جامعه آماری با استفاده از سرشماری است و شاخص بدست آمده از یک نمونه n تائی از جامعه آماره نامیده می شود. برای مثال میانگین جامعه یا µ یک پارامتر مهم جامعه است. چون میانگین جامعه همیشه در دسترس نیست به همین خاطر از میانگین نمونه یا که آماره برآورد کننده پارامتر µ است در بسیاری موارد استفاده می شود.
۲- آزمون آماری و تخمین آماری
در یک مقاله پژوهشی یا یک پایان نامه باید سوال پژوهش یا فرضیه پژوهش مطرح شود. اگر تحقیق از نوع سوالی و صرفا حاوی پرسش درباره پارامتر باشد، برای پاسخ به سوالات از تخمین آماری استفاده می شود و اگر حاوی فرضیه ها بوده و از مرحله سوال گذر کرده باشد، آزمون فرضیه ها و فنون آماری آن به کار می رود.
هر نوع تخمین یا آزمون فرض آماری با تعیین صحیح آماره پژوهش شروع می شود. سپس باید توزیع آماره مشخص شود. براساس توزیع آماره آزمون با استفاده از داده های بدست آمده از نمونه محاسبه شده آماره آزمون محاسبه می شود. سپس مقدار بحرانی با توجه به سطح خطا و نوع توزیع از جداول مندرج در پیوست های کتاب آماری محاسبه می شود. در نهایت با مقایسه آماره محاسبه شده و مقدار بحرانی سوال یا فرضیه تحقیق بررسی و نتایج تحلیل می شود. در ادامه این بحث موشکافی می شود.
۳- آزمون های آماری پارامتریک و ناپارامتریک
آمار پارامتریک مستلزم پیش فرضهائی در مورد جامعه ای که از آن نمونه گیری صورت گرفته می باشد. به عنوان مهمترین پیش فرض در آمار پارامترک فرض می شود که توزیع جامعه نرمال است اما آمار ناپارامتریک مستلزم هیچگونه فرضی در مورد توزیع نیست. به همین خاطر بسیاری از تحقیقات علوم انسانی که با مقیاس های کیفی سنجیده شده و فاقد توزیع (Free of distribution) هستند از شاخصهای آمارا ناپارامتریک استفاده می کنند.
فنون آمار پارامتریک شدیداً تحت تاثیر مقیاس سنجش متغیرها و توزیع آماری جامعه است. اگر متغیرها از نوع اسمی و ترتیبی بوده حتما از روشهای ناپارامتریک استفاده می شود. اگر متغیرها از نوع فاصله ای و نسبی باشند در صورتیکه فرض شود توزیع آماری جامعه نرمال یا بهنجار است از روشهای پارامتریک استفاده می شود در غیراینصورت از روشهای ناپارامتریک استفاده می شود.
۳- خلاصه آزمونهای پارامتریک
آزمونtتک نمونه: برای آزمون فرض پیرامون میانگین یک جامعه استفاده می شود. در بیشتر پژوهش هائی که با مقیاس لیکرت انجام می شوند جهت بررسی فرضیه های پژوهش و تحلیل سوالات تخصصی مربوط به آنها از این آزمون استفاده می شود.
آزمونtوابسته: برای آزمون فرض پیرامون دو میانگین از یک جامعه استفاده می شود. برای مثال اختلاف میانگین رضایت کارکنان یک سازمان قبل و بعد از تغییر مدیریت یا زمانی که نمرات یک کلاس با پیش آزمون و پس آزمون سنجش می شود.
آزمونtدو نمونه مستقل: جهت مقایسه میانگین دو جامعه استفاده می شود. در آزمون t برای دو نمونه مستقل فرض می شود واریانس دو جامعه برابر است. برای نمونه به منظور بررسی معنی دار بودن تفاوت میانگین نمره نظرات پاسخ دهندگان بر اساس جنسیت در خصوص هر یک از فرضیه های پژوهش استفاده میشود.
آزمونtولچ: این آزمون نیز مانند آزمون t دو نمونه جهت مقایسه میانگین دو جامعه استفاده می شود. در آزمون t ولچ فرض می شود واریانس دو جامعه برابر نیست. برای نمونه به منظور بررسی معنی دار بودن تفاوت میانگین نمره نظرات پاسخ دهندگان بر اساس جنسیت در خصوص هر یک از فرضیه های پژوهش استفاده میشود.
آزمونtهتلینگ: برای مقایسه چند میانگین از دو جامعه استفاده می شود. یعنی دو جامعه براساس میانگین چندین صفت مقایسه شوند.
تحلیل واریانس(ANOVA):از این آزمون به منظور بررسی اختلاف میانگین چند جامعه آماری استفاده می شود. برای نمونه جهت بررسی معنی دار بودن تفاوت میانگین نمره نظرات پاسخ دهندگان بر اساس سن یا تحصیلات در خصوص هر یک از فرضیه های پژوهش استفاده می شود.
تحلیل واریانس چندعاملی(MANOVA):از این آزمون به منظور بررسی اختلاف چند میانگین از چند جامعه آماری استفاده می شود.
تحلیل کوواریانس چندعاملی(MANCOVA): چنانچه در MANOVA بخواهیم اثر یک یا چند متغیر کمکی را حذف کنیم استفاده می شود.
۵-خلاصه آزمونهای ناپارامتریک
آزمون علامت تک نمونه: برای آزمون فرض پیرامون میانگین یک جامعه استفاده می شود.
آزمون علامت زوجی: برای آزمون فرض پیرامون دو میانگین از یک جامعه استفاده می شود.
ویلکاکسون: همان آزمون علامت زوجی است که در آن اختلاف نسبی تفاوت از میانگین لحاظ می شود.
من-ویتنی: به آزمون U نیز موسوم است و جهت مقایسه میانگین دو جامعه استفاده می شود.
کروسکال-والیس:از این آزمون به منظور بررسی اختلاف میانگین چند جامعه آماری استفاده می شود. به آزمون H نیز موسوم است و تعمیم آزمون U مان-ویتنی می باشد. آزمون کروسکال-والیس معادل روش پارامتریک آنالیز واریانس تک عاملی است.
فریدمن:این آزمون معادل روش پارامتریک آنالیز واریانس دو عاملی است که در آن k تیمار به صورت تصادفی به n بلوک تخصیص داده شده اند.
کولموگروف-اسمیرنف: نوعی آزمون نیکوئی برازش برای مقایسه یک توزیع نظری با توزیع مشاهده شده است.
آزمون تقارن توزیع: در این آزمون شکل توزیع مورد سوال قرار می گیرد. فرض بدیل آن است که توزیع متقارن نیست.
آزمون میانه: جهت مقایسه میانه دو جامعه استفاده می شود و برای k جامعه نیز قابل تعمیم است.
مک نمار: برای بررسی مشاهدات زوجی درباره متغیرهای دو ارزشی استفاده می شود.
آزمونQکوکران: تعمیم آزمون مک نمار در k نمونه وابسته است.
ضریب همبستگی اسپیرمن: برای محاسبه همبستگی دو مجموعه داده که به صورت ترتیبی قرار دارند استفاده می شود.
شاخه های مختلف علوم برای تجزیه و تحلیل داده ها از روش های مختلفی مانند روش های ذیل استفاده می نمایند:
الف) روش تحلیل محتوا
ب) روش تحلیل آماری
ج) روش تحلیل ریاضی
د) روش اقتصاد سنجی
ه) روش ارزشیابی اقتصادی
و) …
تمرکز این نوشتار بر روش های تجزیه و تحلیل سیستمهای اقتصادی اجتماعی و بویژه روش های تحلیل آماری می باشد.
آمار علم طبقه بندی اطلاعات، علم تصمیم گیری های علمی و منطقی، علم برنامه ریزی های دقیق و علم توصیف و بیان آن چیزی است که از مشاهدات می توان فهمید.
هدف ما آموزش درس آمار نیست زیرا اینگونه مطالب تخصصی را میتوان در مراجع مختلف یافت، هدف اصلی ما ارائه یک روش دستیابی سریع به بهترین روش آماری می باشد.
یکی از مشکلات عمومی در تحقبقات میدانی انتخاب روش تحلیل آماری مناسب و یا به عبارتی انتخاب آزمون آماری مناسب برای بررسی سوالات یا فرضیات تحقیق می باشد.
در آزمون های آماری هدف تعیین این موضوع است که آیا داده های نمونه شواهد کافی برای رد یک حدس یا فرضیه را دارند یا خیر؟
انتخاب نادرست آزمون آماری موجب خدشه دار شدن نتایج تحقیق می شود.
دکتر غلامرضا جندقی استاد یار دانشگاه تهران در مقاله ای کاربرد انواع آزمون های آماری را با توجه به نوع داده ها و وبژگی های نمونه آماری و نوع تحلیل نشان داده است که در این بخش به نکات کلیدی آن اشاره می شود:
قبل از انتخاب یک آزمون آماری بایستی به سوالات زیر پاسخ داد:
۱- چه تعداد متغیر مورد بررسی قرار می گیرد؟
۲- چند گروه مفایسه می شوند؟
۳- آیا توزیع ویژگی مورد بررسی در جامعه نرمال است؟
۴- آیا گروه های مورد بررسی مستقل هستند؟
۵- سوال یا فرضیه تحقیق چیست؟
۶- آیا داده ها پیوسته، رتبه ای و یا مقوله ای Categorical هستند؟
قبل از ادامه این مبحث لازم است مفهوم چند واژه آماری را یاد آور شوم که زیاد وقت گیر نیست.
۱- جامعه آماری: به مجموعه کاملی از افراد یا اشیاء یا اجزاء که حداقل در یک صفت مورد علاقه مشترک باشند ،گفته می شود.
۲- نمونه آماری: نمونه بخشی از یک جامعة آماری تحت بررسی است که با روشی که از پیش تعیین شده است انتخاب میشود، به قسمی که میتوان از این بخش، استنباطهایی دربارة کل جامعه بدست آورد.
۳- پارامتر و آماره: پارامتر یک ویژگی جامعه است در حالی که آماره یک ویژگی نمونه است. برای مثال میانگین جامعه یک پارامتر است. حال اگر از جامعه نمونهگیری کنیم و میانگین نمونه را بدست آوریم، این میانگین یک آماره است.
۴- برآورد و آزمون فرض: برآوردیابی و آزمون فرض دو روشی هستند که برای استنباط درمورد پارامترهای مجهول دو جمعیت به کار می روند.
۵- متغیر: ویژگی یا خاصیت یک فرد، شئ و یا موقعیت است که شامل یک سری از مقادیر با دسته بندیهای متناسب است. قد، وزن، گروه خونی و جنس نمونه هایی از متغیر هستند. انواع متغیر می تواند کمی و کیفی باشد.
۶- داده های کمی مانند قد، وزن یا سن درجه بندی می شوند و به همین دلیل قابل اندازه گیری می باشند. داده های کمی نیز خود به دو دسته دیگر تقسیم می شوند:
الف: داده های فاصله ای (Interval data)
ب: داده های نسبتی (Ratio data)
7- داده های فاصله ای: به عنوان مثال داده هایی که متغیر IQ (ضریب هوشی) را در پنج نفر توصیف می کنند عبارتند از: ۸۰، ۱۱۰، ۷۵، ۹۷ و ۱۱۷، چون این داده ها عدد هستند پس داده های ما کمی اند اما می دانیم که IQ نمی تواند صفر باشد و صفر در اینجا فقط مبنایی است تا سایر مقادیر IQ در فاصله ای منظم از صفر و یکدیگر قرار گیرند پس این داده ها فاصله ای اند.
۸- داده های نسبتی: داده های نسبتی داده هایی هستند که با عدد نوشته می شوند اما صفر آنها واقعی است. اکثریت داده های کمی این گونه اند و حقیقتاً دارای صفر هستند. به عنوان مثال داده هایی که متغیر طول پاره خط بر حسب سانتی متر را توصیف می کنند عبارتند از: ۲۰، ۱۵، ۳۵، ۸ و ۲۳، چون این داده ها عدد هستند پس داده های ما کمی اند و چون صفر در اینجا واقعاً وجود دارد این داده نسبتی تلقی می شوند.
۹- داده های کیفی مانند جنس، گروه خونی یا ملیت فقط دارای نوع هستند و قابل بیان با استفاده از واحد خاصی نیستند. داده های کیفی خود به دو دسته دیگر تقسیم می شوند:
الف: داده های اسمی (Nominal data)
ب: داده های رتبه ای (Ordinal data)
10- داده های رتبه ای Ordinal: مانند کیفیت درسی یک دانش آموز (ضعیف، متوسط و قوی) و یا رتبه بندی هتل ها ( یک ستاره، دو ستاره و …)
۱۱- داده های اسمی (nominal ) که مربوط به متغیر یا خواص کیفی مانند جنس یا گروه خونی است و بیانگر عضویت در یک گروها category خاص می باشد. (داده مقوله ای)
۱۲- متغیر تصادفی گسسته و پیوسته: به عنوان مثال تعداد تصادفات جادهای در روز یک متغیر تصادفی گسسته است ولی انتخاب یک نقطه به تصادف روی دایرهای به مرکز مبدأ مختصات و شعاع ۳ یک متغیر تصادفی پیوسته است.
۱۳- گروه: یک متغیر می تواند به لحاظ بررسی یک ویژگی خاص در یک گروه و یا دو و یا بیشتر مورد بررسی قرار گیرد. نکته ۱: دو گروه می تواند وابسته و یا مستقل باشد. دو گروه وابسته است اگر ویژگی یک مجموعه افراد قبل و بعد از وقوع یک عامل سنجیده شود. مثلا میزان رضایت شغلی کارکنان قبل و بعد از پرداخت پاداش و همچنین اگر در مطالعات تجربی افراد از نظر برخی ویژگی ها در یک گروه با گروه دیگر همسان شود.
۱۴- جامعه نرمال: جامعه ای است که از توزیع نرمال تبعیت می کند.
۱۵- توزیع نرمال: یکی از مهمترین توزیع ها در نظریه احتمال است. و کاربردهای بسیاری در علوم دارد.
فرمول این توزیع بر حسب دو پارامتر امید ریاضی و واریانس بیان می شود. منحنی رفتار این تابع تا حد زیادی شبیه به زنگ های کلیسا می باشد. این منحنی دارای خواص بسیار جالبی است برای مثال نسبت به محور عمودی متقارن می باشد، نیمی از مساحت زیر منحنی بالای مقدار متوسط و نیمه دیگر در پایین مقدار متوسط قرار دارد و اینکه هرچه از طرفین به مرکز مختصات نزدیک می شویم احتمال وقوع بیشتر می شود.
سطح زیر منحنی نرمال برای مقادیر متفاوت مقدار میانگین و واریانس فراگیری این رفتار آنقدر زیاد است که دانشمندان اغلب برای مدل کردن متغیرهای تصادفی که با رفتار آنها آشنایی ندارند، از این تابع استفاده می کنند. به عنوان مثال در یک امتحان درسی نمرات دانش آموزان اغلب اطراف میانگین بیشتر می باشد و هر چه به سمت نمرات بالا یا پایین پیش برویم تعداد افرادی که این نمرات را گرفته اند کمتر می شود. این رفتار را بسهولت می توان با یک توزیع نرمال مدل کرد.
اگر یک توزیع نرمال باشد مطابق قضیه چی بی شف ۲۶٫۶۸ % مشاهدات در فاصله میانگین، مثبت و منفی یک انحراف معیار قرار دارد. و ۴۴٫۹۵ % مشاهدات در فاصله میانگین، مثبت و منفی دو انحراف معیار قرار دارد. و ۷۳٫۹۹ % مشاهدات در فاصله میانگین، مثبت و منفی سه انحراف معیار قرار دارد.
نکته ۱: واضح است که داده های رتبه ای دارای توزیع نرمال نمی باشند.
نکته ۲: وقتی داده ها کمی هستند و تعداد نمونه نیز کم است تشخیص نرمال بودن داده ها توسط آزمون کولموگروف – اسمیرنف مشکل خواهد شد.
۱۶- آزمون پارامتریک: آزمون های پارامتریک، آزمون های هستند که توان آماری بالا و قدرت پرداختن به داده های جمع آوری شده در طرح های پیچیده را دارند. در این آزمون ها داده ها توزیع نرمال دارند. (مانند آزمون تی).
۱۷-آزمون های غیرپارامتری: آزمون هائی می باشند که داده ها توزیع غیر نرمال داشته و در مقایسه با آزمون های پارامتری از توان تشخیصی کمتری برخوردارند. (مانند آزمون من – ویتنی و آزمون کروسکال و والیس)
نکته۳: اگر جامعه نرمال باشد از آزمون های پارامتریک و چنانچه غیر نرمال باشد از آزمون های غیر پارامتری استفاده می نمائیم.
نکته ۴: اگر نمونه بزرگ باشد، طبق قضیه حد مرکزی جتی اگر جامعه نرمال نباشد می توان از آزمون های پارامتریک استفاده نمود.
حال به کمک جدول زیر براحتی می توانید یکی از ۲۴ آزمون مورد نظر خود را انتخاب کنید:
هدف
داده کمی و دارای توزیع نرمال
داده رتبه ای و یا داده کمی غیر نرمال
داده های کیفی اسمی Categorical
توصیف یک گروه
آزمون میانگین و انحراف معیار
آزمون میانه
آزمون نسبت
مقایسه یک گروه با یک مقدار فرضی
آزمون یک نمونه ای
آزمون ویلکاکسون
آزمون خی – دو یا آزمون دو جمله ای
مقابسه دو گروه مستقل
آزمون برای نمونه های مستقل
آزمون من – ویتنی
آزمون دقیق فیشر ( آزمون خی دو برای نمونه های بزرگ)
مقایسه دو گروه وابسته
آزمون زوجی
آزمون کروسکال
آزمون مک – نار
مقایسه سه گروه یا بیشتر (مستقل)
آزمون آنالیز واریانس یک راهه
آزمون والیس
آزمون خی – دو
مقایسه سه گروه یا بیشتر (وابسته)
آزمون آنالیز واریانس با اندازه های مکرر
آزمون فریدمن
آزمون کوکران
اندازه همبستگی بین دو متغیر
آزمون ضریب همبستگی پیرسون
آزمون ضریب همبستگی اسپرمن
آزمون ضریب توافق
پیش بینی یک متغیر بر اساس یک یا چند متغیر
آزمون رگرسیون ساده یا غیر خطی
آزمون رگرسیون نا پارامتریک
آزمون رگرسیون لجستیک
در رویکردی دیگر بر مبنای تعداد متغیر، تعداد گروه و نرمال بودن جامعه نیز می توان به الگوریتم آزمون آماری مورد نظر دست یافت:
یک متغیر:
انتخاب آزمون آماری برای یک متغیر
یک متغیر در یک گروه
یک متغیر در دو گروه
یک متغیر در سه گروه یا بیشتر
متغیر نرمال
آزمون میانگین و انحراف معیار
آزمون تی
آزمون آنالیز واریانس ANOVA
متغیر غیر نرمال
آزمون نسبت (دو جمله ای)
آزمون خی -دو
آزمون ناپارامتریک
دو متغیر
انتخاب آزمون آماری برای دو متغیر
هر دو متغیر پیوسته هستند
یک متغیر پیوسته و دیگری گسسته است
هر دو متغیر مقوله ای هستند
آزمون همبستگی
آزمون آنالیز واریانس ANOVA
آزمون خی – دو
سه متغیر و بیشتر:
انتخاب آزمون آماری برای سه متغیر و بیشتر
یک گروه
دو گروه و بیشتر
آنالیز کواریانس
تحلیل ممیزی
آنالیز واریانس با اندازه های مکرر
آنالیز واریانس چند متغیره
تحلیل عاملیورگرسیون چند گانه
قابل ذکر است قبل از ورود به الگوریتم انتخاب آزمون آماری بهتر است به سوالات زیر پاسخ دهیم:
۱- آیا اختلافی بین میانگین (نسبت) یک ویژگی در دو یا چند گروه وجود دارد؟
۲- آیا دو متغیر ارتباط دارند؟
۳- چگونه می توان یک متغیر را با استفاده از متغیر های دیگر پیش بینی کرد؟
۴- چه چیزی می توان با استفاده از نمونه در مورد جامعه گفت؟
پس از انتخاب آزمون آماری مناسب حال می توان با هر یک از آزمون ها به صورت تخصصی برخورد کرد:
آزمون کی دو (خی دو یا مربع کای)
این آزمون از نوع ناپارامتری است و برای ارزیابی همقوارگی متغیرهای اسمی به کار میرود. این آزمون تنها راه حل موجود برای آزمون همقوارگی در مورد متغیرهای مقیاس اسمی با بیش از دو مقوله است، بنابراین کاربرد خیلی زیادتری نسبت به آزمونهای دیگر دارد. این آزمون نسبت به حجم نمونه حساس است.
آزمونz –آزمون خطای استاندارد میانگین
این آزمون برای ارزیابی میزان همقوارگی یا یکسان بودن و یکسان نبودن (Goodness of fit) میانگین نمونه ای و میانگین جامعه به کار می رود. این آزمون مواقعی به کار می رود که می خواهیم بدانیم آیا میانگین برآورد شده نمونه ای با میانگین جامعه جور می آید یا نه. اگر این تفاوت کم باشد، این تفاوت معلول تغییر پذیری نمونه ای شناخته می شود، ولی اگر زیاد باشد نتیجه گرفته می شود که برآورد نمونه ای با پارامتر جامعه یکسان (همقواره) نیست. این آزمون پارامتری است یعنی استفاده از آن مشروط به آن است که دو پارامتر جامعه که میانگین و انحراف معیار معلوم باشند. همچنین برای آزمون متغیرهای پیوسته (مقیاس فاصله ای) کاربرد دارد. تعداد نمونه بزرگتر و یا مساوی ۳۰ باشد و نیز توزیع متغیر در جامعه نرمال باشد.
آزمون استیودنتt
این آزمون برای ارزیابی میزان همقوارگی یا یکسان بودن و نبودن میانگین نمونه ای با میانگین جامعه در حالتی به کار می رود که انحراف معیار جامعه مجهول باشد. چون توزیع t در مورد نمونه های کوچک (کمتر از ۳۰) با استفاده از درجات آزادی تعدیل میشود، میتوان از این آزمون برای نمونه های بسیار کوچک استفاده نمود. همچنین این آزمون مواقعی که خطای استاندارد جامعه نامعلوم و خطای استاندارد نمونه معلوم باشد، کاربرد دارد.
برای به کاربردن این آزمون، متغیر مورد مطالعه باید در مقیاس فاصله ای باشد، شکل توزیع آن نرمال و تعداد نمونه کمتر از ۳۰ باشد.
آزمون t در حالتهای زیر کاربرد دارد:
– مقایسه یک عدد فرضی با میانگین جامعه نمونه
– مقایسه میانگین دو جامعه
– مقایسه یک نسبت فرضی با یک نسبتی که از نمونه بدست آمده
– مقایسه دو نسبت از دو جامعه
آزمونF
این آزمون تعمیم یافته آزمون t است و برای ارزیابی یکسان بودن یا یکسان نبودن دو جامعه و یا چند جامعه به کار برده میشود. در این آزمون واریانس کل جامعه به عوامل اولیه آن تجزیه میشود. به همین دلیل به آن آزمون آنالیز واریانس (ANOVA) نیز میگویند.
وقتی بخواهیم بجای دو جامعه، همقوارگی چند جامعه را تواما با هم مقایسه نماییم از این آزمون استفاده میشود، چون مقایسه میانگین های چند جامعه با آزمون t بسیار مشکل است. مقایسه میانگین ها و همقوارگی چند جامعه بوسیله این آزمون (F یا ANOVA) راحت تر از آزمون t امکان پذیر است.
آزمون کوکران
آزمون کوکران تعمیم یافته آزمون مک نمار است. این آزمون برای مقایسه بیش از دو گروه که وابسته باشند و مقیاس آنها اسمی یا رتبه ای باشند به کار میرود و همچون آزمون مک نمار، جوابها باید دوتایی باشند.
برای آزمون تغییرات یک نمونه در زمان ها و یا موقعیت های مختلف (مثل آراء رای دهندگان قبل از انتخابات در زمانهای مختلف) به کار میرود. مقیاس میتواند اسمی یا رتبه ای باشد. به جای چند سوال میتوان یک سوال را در موقعیت های مختلف ارزیابی نمود. همه افراد باید به همه سوالات پاسخ گفته باشند. چون پاسخ ها دو جوابی است، در بعضی از انواع تحقیقات ممکن است اطلاعات بدست آمده از دست برود و بهتر است از رتبه بندی استفاده کرد که در این صورت «آزمون ویلکاکسون» بهتر جوابگو خواهد بود.
در صورت کوچک بودن نمونه ها آزمون کوکران مناسب نیست و بهتر است از «آزمون فرید من» استفاده شود.
آزمون فریدمن
این آزمون برای مقایسه چند گروه از نظر میانگین رتبه های آنهاست و معلوم میکند که آیا این گروه ها میتوانند از یک جامعه باشند یا نه؟
مقیاس در این آزمون باید حداقل رتبه ای باشد. این آزمون متناظر غیر پارامتری آزمون F است و معمولا در مقیاس های رتبه ای به جای F به کار میرود و جانشین آن میشود (چون در F باید همگنی واریانس ها وجود داشته باشد که در مقیاسهای رتبه ای کمتر رعایت میشود).
آزمون فریدمن برای تجریه واریانس دو طرفه (برای داده های غیر پارامتری) از طریق رتبه بندی به کار میرود و نیز برای مقایسه میانگین رتبه بندی گروه های مختلف. تعداد افراد در نمونه ها باید یکسان باشند که این از معایب این آزمون است. نمونه ها باید همگی جور شده باشند.
آزمون کالماگورف- اسمیرانف
این آزمون از نوع ناپارامتری است و برای ارزیابی همقوارگی متغیرهای رتبه ای در دو نمونه (مستقل و یا غیر مستقل) و یا همقوارگی توزیع یک نمونه با توزیعی که برای جامعه فرض شده است، به کار میرود (اسمیرانف یک نمونه ای). این آزمون در مواردی به کار میرود که متغیرها رتبه ای باشند و توزیع متغیر رتبه ای را در جامعه بتوان مشخص نمود. این آزمون از طریق مقایسه توزیع فراوانی های نسبی مشاهده شده در نمونه با توزیع فراوانی های نسبی جامعه انجام میگیرد. این آزمون ناپارامتری است و بدون توزیع است اما باید توزیع متغیر در جامعه برای هر یک از رتبه های مقیاس رتبه ای در جامعه بطور نسبی در نظر گرفته شود که آنرا نسبت مورد انتظار می نامند.
آزمون کالماگورف- اسمیرانف دو نمونه ای Two- Sample Kalmogorov- Smiranov Test
این آزمون در مواقعی به کار میرود که دو نمونه داشته باشیم (با شرایط مربوط به این آزمون که قبلا گفته شد) و بخواهیم همقوارگی بین آن دو نمونه را با هم مقایسه کنیم.
آزمون کروسکال- والیس
این آزمون متناظر غیر پارامتری آزمون F است و همچون آزمون F ، موقعی به کار برده میشود که تعداد گروه ها بیش از ۲ باشد. مقیاس اندازه گیری در کروسکال والیس حداقل باید ترتیبی باشد.
این آزمون برای مقایسه میانگین های بیش از ۲ نمونه رتبه ای (و یا فاصله ای) بکار میرود. فرضیات در این آزمون بدون جهت است یعنی فقط تفاوت را نشان میدهد و جهت بزرگتر یا کوچکتر بودن گروه ها را از نظر میانگین هایشان نشان نمی دهد. کارایی این آزمون ۹۵ درصد آزمون F است.
آزمون مک نمار
این آزمون از آزمونهای ناپارامتری است که برای ارزیابی همانندی دو نمونه وابسته بر حسب متغیر دو جوابی استفاده میشود. متغیرها میتوانند دارای مقیاس های اسمی و یا رتبه ای باشند. این آزمون در طرح های ماقبل و مابعد میتواند مورد استفاده قرار گیرد (یک نمونه در دو موقعیت مختلف). این آزمون مخصوصا برای سنجش میزان تاثیر عملکرد تدابیر به کار میرود.
ویژگی ها: اگر متغیرها اسمی باشند، این آزمون بی بدیل است اما اگر رتبه ای باشد میتوان از آزمون t نیز استفاده کرد (در صورت وجود شرایط آزمون t) ، و یا آزمون ویلکاکسون استفاده نمود. از عیوب این آزمون این است که جهت و اندازه تغییرات را محاسبه نمیکند و فقط وجود تغییرات را در نمونه ها در نظر میگیرد.
آزمون میانه
این آزمون همتای ناپارامتری آزمون های t – Z – F است و وقتی دو یا چند گروه از میان دو یا چند جامعه مستقل با توزیع های یکسان انتخاب شده اند به کار برده میشود. در این آزمون مقیاس اندازه گیری ترتیبی است و بین داده ها نباید همرتبه وجود داشته باشد. این آزمون، هم برای گروه های مستقل و هم وابسته کاربرد دارد و لزومی ندارد که حتما حجم گروه های نمونه با یکدیگر برابر باشند.
آزمون تک نمونه ای دورها
این آزمون مواقعی به کار میرود که توالی مقادیر متغیرها را بخواهیم آزمون نماییم که آیا تصادفی بوده و یا نه. در واقع آزمون کی دو و یا آزمون های دیگر که در آنها توالی متغیرها بی اهمیت است، در این آزمون مهم و اصل انگاشته میشود. به عبارت دیگر، برای اینکه بتوانیم در یک نمونه که در آن رویدادهای مختلف از طرف فرد و یا واحد آماری رخ داده است، آزمون نماییم که آیا این رویدادها تصادفی است یا نه، به کار برده میشود. هیچ آزمون دیگری همچون این آزمون نمی تواند توالی را مورد نظر قرار دهد. بنابراین برای این منظور منحصر به فرد میباشد.
آزمون علامت
این آزمون از انواع آزمونهای غیر پارامتری است و هنگامی به کار برده میشود که نمونه های جفت، مورد نظر باشد (مثل زن و شوهر و یا خانه های فرد و زوج و . . . ). زیرا در این آزمون یافتهها به صورت جفت جفت بررسی میشوند و اندازه مقادیر در آن بی اثر است و فقط علامت مثبت و منفی و یا در واقع جهت پاسخ ها و یا بیشتر و کمتر بودن پاسخ های جفتهای گروه مورد تحقیق (نمونه آماری) در نظر گرفته میشود.
هنگامی که ارزشیابی متغیر مورد مطالعه با روشهای عادی قابل اندازه گیری نباشد و قضاوت در مورد نمونه های آماری (که به صورت جفت ها هستند) فقط با علامت بیشتر (+) و کمتر (-) مورد نظر باشد ، از این آزمون میتوان استفاده کرد. شکل توزیع میتواند نرمال و یا غیر نرمال باشد و یا از یک جامعه و یا دو جامعه باشند (مستقل و یا وابسته). توزیع باید پیوسته باشد. این آزمون فقط تفاوت های زوجها را مورد بررسی قرار میدهد و در صورت مساوی بودن نظرات هر زوج (مشابه بودن) آنها را از آزمون حذف میکند. چون مقادیر در این آزمون نقشی ندارند، شدت و ضعف و اندازه بیشتر یا کمتر بودن نظرات پاسخگویان (جفت ها) در این آزمون بی اثر است و در واقع نقص این آزمون حساب میشود.
آزمون تی هتلینگ(T)
آزمون T هتلینگ تعمیم یافته t استیودنت است. در آزمون t یک نمونه ای، میانگین یک صفت از یک نمونه، با یک عدد فرضی که میانگین آن صفت از جامعه فرض میشد، مورد مقایسه قرار میگرفت، اما در T هتلینگ K متغیر (صفت) از آن جامعه (نمونه های جامعه) با k عدد فرضی، مورد مقایسه قرار میگیرند. در واقع این آزمون از نوع آزمونهای چند متغیره است که همقوارگی (Goodness of fit) را بین صفت های مختلف از جامعه بدست میدهد. در T هتلینگ دو نمونه ای نیز همچون T استیودنت دو نمونه ای، مقایسه دو نمونه است اما در این آزمون K صفت از یک جامعه (نمونه) با K صفت از جامعه دیگر (نمونه دیگر) مورد مقایسه قرار میگیرد.
آزمون مان وایتنیU
هر گاه دو نمونه مستقل از جامعه ای مفروض باشد و متغیرهای آنها به صورت ترتیبی باشند، از این آزمون استفاده میشود. این آزمون مشابه t استیودنت با دو نمونه مستقل است و آزمون ناپارامتری آن محسوب میشود.
منبع: http://isigroup.ir/tag
هرگاه شرایط استفاده از آزمونهای پارامتری در متغیرها موجود نباشد، یعنی متغیرها پیوسته و نرمال نباشند از این آزمون استفاده میشود. دو نمونه باید مستقل بوده و هر دو کوچکتر از ۱۰ مورد باشند. در صورت بزرگتر بودن از ۱۰ مورد باید از آماره های Z استفاده کرد (در محاسبات کامپیوتری، تبدیل به Z به طور خودکار انجام میشود). در این آزمون شکل توزیع، پیش فرضی ندارد یعنی میتواند نرمال و یا غیر نرمال باشد.
آزمون ویلکاکسون
این آزمون از آزمونهای ناپارامتری است که برای ارزیابی همانندی دو نمونه وابسته با مقیاس رتبه ای به کار میرود. همچون آزمون مک نمار، این آزمون نیز مناسب طرح های ماقبل و مابعد است (یک نمونه در دو موقعیت مختلف)، و یا دو نمونه که از یک جامعه باشند. این آزمون اندازه تفاوت میان رتبه ها را در نظر میگیرد بنابراین متغیرها میتوانند دارای جوابهای متفاوت و یا فاصله ای باشند. این آزمون متناظر با آزمون t دو نمونه ای وابسته است و در صورت وجود نداشتن شرایط آزمون t جانشین خوبی برای آن است. نمونه های به کار برده شده در این آزمون باید نسبت به سایر صفت هایشان جور شده (جفت شده) باشند.
آزمون لونLevene
آزمون لون همگنی واریانس ها را در نمونه های متفاوت بررسی می نماید. به عبارتی فرض تساوی متغیر وابسته را برای گروه هائی که توسط عامل رسته ای تعیین شده اند، آزمون می کند و نسبت به اکثر آزمونها کمتر به فرض نرمال بودن وابسته بوده و در واقع به انحراف نرمال مقاوم است.
این آزمون در نظر می گیرد که واریانس جمعیت آماری در نمونه های مختلف برابر است. فرض صفر همگن بودن واریانس ها می باشد یعنی واریانس جمعیت ها با هم برابر است و اگر مقدار P-VALUE در اماره لون کمتر از ۰٫۰۵ باشد تفاوت بدست آمده در واریانس نمونه بعید است که بر اساس روش نمونه گیری تصادفی رخ داده باشد. بنابراین فرض صفر که برابری واریانس ها می باشد رد می شود و به این نتیجه می رسیم که که بین واریانس ها در نمونه تفاوت وجود دارد.
همانگونه که واضح و مشخص است با گذشت زمان علم نیز پیشرفت می کند، هر چه به جلوتر می رویم روشهای جدیدتر و بهتر مورد استفاده قرار می گیرد. علم امروز نسبت به دیروز جدیدتر است. روشهای جدید علمی در پی کشف محدودیت های روشهای قدیمی ایجاد می شود و از آنجایی که روشهای آماری جزء روشهای قدیمی Data mining محسوب می شوند، از این قاعده کلی که دارای محدودیت هستند مستثنی نیستند. داشتن فرض اولیه در مورد داده ها، یکی از این موارد است. در اینجا به تشریح بیشتر تفاوت های بین مباحث و متدهای آماری و دیگر متدهای داده کاوی که در کتابهای مختلف بحث شده است می پردازیم.
تکنیکهای داده کاوی و تکنیکهای آماری در مباحثی چون تعریف مقدار هدف برای پیش گویی، ارزشیابی خوب و داده های دقیق (تمیز) (clean data) خوب عمل می کنند، همچنین این موارد در جاهای یکسان برای انواع یکسانی از مسایل (پیش گویی، کلاس بندی و کشف) استفاده می شوند، بنابراین تفاوت این دو چیست؟چرا ما آنچنان که علاقه مند بکاربردن روشهای داده کاوی هستیم علاقه مند روشهای آماری نیستیم؟ برای جواب این سوال چندین دلیل وجود دارد. اول اینکه روشهای کلاسیک داده کاوی از قبیل شبکه های عصبی، تکنیک نزدیک ترین همسایه روشهای قوی تری برای داده های واقعی به ما می دهند و همچنین استفاده از آنها برای کاربرانی که تجربه کمتری دارند راحت تر است و بهتر می توانند از آن استفاده کنند. دلیل دیگر اینکه بخاطر اینکه معمولاُ داده ها اطلاعات زیادی در اختیار ما نمی گذارند، این روشها با اطلاعات کمتر بهتر می توانند کار کنند و همچنین اینکه برای داده ها وسیع کابرد دارند.
در جایی دیگر اینگونه بیان شده که داده های جمع آوری شده نوعاُ خیلی از فرضهای قدیمی آماری را در نظر نمی گیرند، از قبیل اینکه مشخصه ها باید مستقل باشند، تعیین توزیع داده ها، داشتن کمترین همپوشانی در فضا و زمان اغلب داده ها هم پوشانی زیاد می دارند، تخلف کردن از هر کدام از فرضها می تواند مشکلات بزرگی ایجاد کند. زمانی که یک کاربر (تصمیم گیرنده) سعی می کند که نتیجه ای را بدست آورد. داده های جمع آوری شده بطورکلی تنها مجموعه ای از مشاهدات چندی بعد است بدون توجه به اینکه چگونه جمع آوری شده اند.
در جایی پایه و اساس Data mining به دو مقوله آمار و هوش مصنوعی تقسیم شده است که روشهای مصنوعی به عنوان روشهای یادگیری ماشین در نظر گرفته می شوند.فرق اساسی بین روشهای آماری و روشهای یادگیری ماشین (machine learning) بر اساس فرضها و یا طبیعت داده هایی که پردازش می شوند.بعنوان یک قانون کلی فرضها تکنیکهای آماری بر این اساس است که توزیع داده ها مشخص است که بیشتر موارد فرض بر این است که توزیع نرمال است و در نهایت درستی یا نادرستی نتایج نهایی به درست بودن فرض اولیه وابسته است.در مقابل روشهای یادگیری یادگیری ماشین از هیچ فرض در مورد داده ها استفاده نمی کند و همین مورد باعث تفاوتهایی بین این دو روش می شود.
به هر حال ذکر این نکته ضروری به نظر می رسد که بسیاری از روشهای یادگیری ماشین برای ساخت مدل dataset از حداقل چند استنتاج آماری استفاده می کنندکه این مساله بطور خاص در شبکه عصبی دیده می شود.
بطور کلی روشهای آماری روش های قدیمی تری هستند که به حالت های احتمالی مربوط می شوند.Data mining جایگاه جدید تری دارد که به هوش مصنوعی یادگیری ماشین سیستمهای اطلاعات مدیریت (MIS) و متدلوژی Database مربوط می شود.
روشهای آماری بیشتر زمانی که تعداد دادهها کمتر است و اطلاعات بیشتری در مورد داده ها می توان بدست آورد استفاده می شوند به عبارت دیگر این روشها با مجموعه داده ها ی کوچک تر سر و کار دارند همچنین به کاربران ابزارهای بیشتری برای امتحان کردن داده ها با دقت بیشتر فهمیدن ارتباطات بین داده ها می دهد. بر خلاف روشهایی از قبیل شبکه عصبی که فرآیند مبهمی دارد. پس به طور کلی این روش در محدوده مشخصی از داده های ورودی بکار می رود.بکار بردن این روشها مجموعه داده های مجموعه داده های زیاد احتمال خطا در این روشها را زیاد می کند.چون در داده ها احتمالnoise وخطا بیشتر می شود و نیز روشهای آماری معمولابه حذف noiseمی پردازند، بنابراین خطای محاسبات در این حالت زیاد می شود.
در بعضی از روشهای آماری نیازداریم که توزیع داده ها را بدانیم. اگر بتوان به آن دسترسی پیدا کرده با بکار بردن روش آماری می توان به نتایج خوبی رسید.
روشهای آماری چون پایه ریاضی دارند نتایج دقیق تری نسبت به دیگر روشهای Data mining ارائه می دهند ولی استفاده از روابط ریاضی نیازمند داشتن اطلا عات بیشتری در مورد داده ها است.
مزیت دیگر روشهای آماری در تعبیر و تفسیر داده ها است. هر چند روشهای آماری به خاطر داشتن ساختار ریاضی تفسیر سخت تری دارند ولی دقت نتیجه گیری و تعبیر خروجی ها در این روش بهتر است بطور کلی روشهای آماری زمانی که تفسیر داده ها توسط روشهای دیگر مشکل است بسیار مفید هستند.
تفاوتهای کلی روشهای آماری و دیگر روشهای Data mining در جدول اریه شده است :
روشهای آماری
دیگر روشهایData mining
داشتن فرض اولیه
بدون فرض اولیه
تنها برای داده های عددی کاربرد دارند
در انواع مختلفی از داده ها کاربرد دارند نه فقط داده های عددی
در محدوده کوچکی از داده ها
در محدوده وسیع تری از داده ها
حذفnoise ها ، داده های نامشخص ووفیلتر کردن dirty data
Data mining به دادهای درست clean data بستگی دارند
روشهای رگرسیون و استفاده از معادلات
استفاده از شبکه عصبی
استفاده از چارتهای دو بعدی و سه بعدی
استفاده ازData visualization
استفاده از روابط ریاضی
استفاده از روشهای یادگیری ماشین و هوش مصنوعی
در descriptive statisticalوcluster analysis کاربرد دارد.
در یادگیری غیر نظارتی کاربرد بیشتر دارد
همچنین می توان گفت که در DM داده ها اغلب بر اساس همپوشانی نمونه هاست،نسبت به اینکه بر اساس احتمال داده ها باشد.همپوشانی نمونه ها برای آشنایی همه انواع پایه ها برای تخمین پا را مترها مشهور است. وهمچنین اغلب استنتاج های آماری نتایج ممکن است مشارکتی باشد تا اینکه سببی باشند.
تکنیکهای ماشین را به سادگی می توان تفسیر کرد .مثلاَُ روش شبکه عصبی بر اساس یک مدل ساده بر اساس مغز انسان استوار است.یعنی همان ساختار مغز انسان را اجرا می کنند ولی خروجی های بسیاری از روشهای آماری ساختار ریاضی دارند،مثلاَُ یک معادله است که تعبیر و تفسیر آن مشکل تر است.در مورد روش های آماری بایداین مطلب را گفت بدون توجه به اینکه مدل کاربردی،مدل آماری است یا خیر،تستهای آماری می تواند برای تحلیل نتایج مفید باشد.
با ارایه توضیحات داده شده درباره های تفاوتهای روشهای آماری و دیگر روشهای DM در ادامه به کابردهای روش روشهای آماری و بحثهای مشترک آمار وDM می پردازیم .
کاربردهای روشهای آماری
Data mining معمولا وظایف یا به عبارت بهتر استراتژهای زیر را در داده ها بکار می برد :
– توضیح و تفسیر (description)
– تخمینestimation) )
– پیش بینیprediction) )
– کلاس بندیclassification) )
– خوشه سازی (clustering)
– وابسته سازی وایجاد رابطه (association)
در جدول زیر استراتژی ها و روشهای هر استراتژی مشخص شده است :
روشها
استراتژیها
تحلیل داده ها
توضیح وتفسیر
تحلیل های آماری
تخمین
تحلیل های آماری
پیش بینی
الگوریتم نزدیک ترین همسایه
کلاس بندی
درخت تصمیم
کلاس بندی
شبکه های عصبی
کلاس بندی
خوشه سازی k-mean
خوشه سازی
شبکه های kohonen
خوشه سازی
وابسته سازی و ایجاد رابطه
رابطه سازی
البته باید گفت که روشهای data mining تنها به یک استراتژی خاص محدود نمی شوندو نتایج یک را همپوشانی بین روشها نشان می دهد. برای مثال درخت تصمیم ممکن است که درکلاس بندی تخمین وپیش بینی کاربرد داشته باشد. بنابراین این جدول را نباید به عنوان تعریف تعریف تقسیم بندی از وظایف در نظرگرفته شود بلکه به عنوان یک خروجی از آنچه که ما به عنوان وظایف dataminig آشنایی پیدا کردیم در نظر گرفته می شود.
همانگونه که ازجدول پیداست روشهای آماری در مباحث تخمین و پیش بینی کاربرد دارند. در تحلیل آماری تخمین و پیش بینی عناصری از استنباطهای آماری هستند.استنباطهای آماری شامل روشهایی برای تخمین و تست فرضیات درباره جمعیتی از ویژگیها براساس اطلاعات حاصل از نمونه است .یک جمعیت شامل مجموعه ای از عناصر از قبیل افراد، ایتم ها، یا داده ها یی که دریک مطالعه خاص آمده است. بنابراین در اینجا به توضیح این دواستراتژی می پردازیم.
۱- تخمین
در تخمین به دنبال این هستیم که مقدار یک مشخصه خروجی مجهول را تعیین کنیم،مشخصه خروجی در مسائل تخمین بیشتر عددی هستند تا قیاسی. بنابراین مواردی که بصورت قیاسی هستند باید به حالت عددی تبدیل شوند. مثلا موارد بلی،خیر به ۰ و۱ تبدیل می شود.
تکنیکهای نظارتی DM قادرند یکی از دو نوع مسایل کلاس بندی یا تخمین را حل کنند، نه اینکه هر دو را. یعنی اینکه تکنیکی که کار تخمین را ا نجام می دهد، کلا س بندی نمی کند.
روشهای آماری مورد استفاده دراین مورد بطورکلی شامل تخمین نقطه و فاصله اطمینان میباشد. تحلیل های آماری تخمین و تحلیل های یک متغیره و… از این جمله می باشند.
در توضیح اینکه چرا به سراغ تخمین می رویم باید گفت که مقدار واقعی پارامترها برای ما ناشناخته است.مثلا مقدار واقعی میانگین یک جامعه مشخص نیست. داده ها ممکن است که بطور رضایت بخشی جمع آوری نشده باشد یا به عبارتی warehouse نشده باشد. به همین دلیل تحلیل گران از تخمین استفاده میکنند.
در خیلی از موارد تعیین میانگین مجموعه ای از داده ها برای ما مهم است.مثلا میانگین نمرات درسی یک کلاس،میانگین تعداد نفراتی که در یک روز به بانک مراجعه می کنند،متوسط مقدار پولی که افراد دریک شعبه خاص از بانک واریز می کنند و موارد این چنینی.
زمانی که مقدار یک آماره را برای براورد کردن پارامتر یک جامعه به کار ببریم، آن پارامتر را تخمین زده ایم و به مقدار این آماره برآورد نقطه ای پرامتر اطلاق می کنیم. در واقع از کلمه نقطه برای تمایز بین براورد کننده های نقطه ای و فاصله ای استفاده می کنیم. از مهمترین تخمین زننده ها است که به ترتیب برآورد واریانس و میانگین جامعه هستند. خود برآورد کننده ها دارای خاصیت هایی چون ناریبی، کارایی، ناسازگاری، بسندگی و… هستند، که هر یک به بیان ویژگی خاصی از آنها می پردازند و میزان توانایی آنها را در تخمین درست و دقیق یک پارامتر تعیین می کنند.
در مواردی نیز تخمین فاصله برای ما اهمیت دارد. فاصله اطمینان شامل فاصله ای است که با درصدی از اطمینان می توانیم بگوییم که مقدار یک پارامتر درون این فاصله قرار می گیرد. به عبارت دیگر اگر چه برآورد نقطه ای طریقه متداول توصیف برآورد هاست اما درباره آن، جا برای پرسشهای زیادی باقی است. مثلا برآورد نقطه ای به ما نمی گوید که برآورد بر چه مقداری از اطلاعات مبتنی است و چیزی درباره خطا بیان نمی کند. بنابراین می توانیم که برآورد پارامتر را با بعلاوه کردن اندازه کردن اندازه نمونه و مقدار واریانس ،یا اطلاعات دیگری درباره توزیع نمونه گیری کامل کنیم.این کار ما را قادر می سازد که اندازه ممکن خطا را برآورد کنیم.
۲- پیش بینی( prediction )
هدف از انجام پیش بینی تعیین ترکیب خروجی با استفاده از رفتار موجود می باشد. یعنی در واقع رسیدن به یک نتیجه بوسیله اطلاعات موجود از داده ها. مشخصه های خروجی در این روش هم می توانند عددی باشند و هم قیاسی. این استراتژی در بین استراتژی های data mining از اهمیت خاصی بر خوردار است، و مفهوم کلی تری را نسبت به موارد دیگر دارد. خیلی از تکنیکهای نظارتی data mining که برای کلاس بندی و تخمین مناسب هستند در واقع کار پیش بینی انجام می دهند.
آنچه از کتابهای آماری و data minig تحت عنوان پیش بینی برمی آید رگرسیون و مباحث مر بوط به آن است . در واقع در اکثر این کتابها هدف اصلی از انجام تحلیل های آماری برای داده کاوی، رگرسیون داده هاست و این بعنوان وظیفه اصلی متد های آماری معرفی می شود.
جهت جابجا کردن سطر و ستون در اکسل مراحل زیر را انجام دهید
1- ابتدا محدوده مورد نظر را انتخاب نموده و بعد روی محدوده ی انتخاب شده راست کلیک و گزینه کپی یا کات را انتخاب کنید.
2- در جای مورد نظر ( جایی در همان صفحه _ یا در شیتی دیگر یا در فایل اکسل دیگری) دوباره راست کلیک کن و از قسمت paste Special گزینه Transpose را انتخاب کن.
راحت و کاربردی بود نه! پس سایت را به دیگران معرفی کن، نظرت را بنویس و قوت قلب ما باش!
برای مشاهده لیست همه ی پرسشنامه های استاندارد لطفا همین جا روی پرسشنامه استاندارد کلیک فرمایید.
نرم افزار لیزرل و انجام مدلسازی معادلات ساختاری با آن
1- مدل معادلات ساختاری چیست؟
مدل يابي معادلات ساختاري (Structural equation modeling: SEM) يک تکنيک تحليل چند متغيري بسيار کلي و نيرومند از خانواده رگرسيون چند متغيري و به بيان دقيقتر بسط “مدل خطي کلي” (General linear model) یا GLM است. SEM به پژوهشگر امکان ميدهد مجموعه اي از معادلات رگرسيون را به صورت هم زمان مورد آزمون قرار دهد.
مدل يابي معادله ساختاري يک رويکرد جامع براي آزمون فرضيههايي درباره روابط متغيرهاي مشاهده شده و مکنون است که گاه تحليل ساختاري کوواريانس، مدل يابي علّي و گاه نيز ليزرل (Lisrel) ناميده شده است اما اصطلاح غالب در اين روزها، مدل يابي معادله ساختاري يا به گونه خلاصه SEM است. (هومن 1384،11)
از نظر آذر (1381) نيز يکي از قويترين و مناسبترين روشهاي تجزيه و تحليل در تحقيقات علوم رفتاري و اجتماعي، تجزيه و تحليل چند متغيره است زيرا اين گونه موضوعات چند متغيره بوده و نمي توان آنها را با شيوه دو متغيري (که هر بار يک متغير مستقل با يک متغير وابسته در نظر گرفته ميشود) حل نمود.
«تجزيه و تحليل ساختارهاي کوواريانس» يا همان «مدل يابي معادلات ساختاري»، يکي از اصليترين روشهاي تجزيه و تحليل ساختار دادههاي پيچيده و يکي از روشهاي نو براي بررسي روابط علت و معلولي است و به معني تجزيه و تحليل متغيرهاي مختلفي است که در يک ساختار مبتني بر تئوري، تاثيرات همزمان متغيرها را به هم نشان ميدهد. از طريق اين روش ميتوان قابل قبول بودن مدلهاي نظري را در جامعههاي خاص با استفاده از دادههاي همبستگي، غير آزمايشي و آزمايشي آزمود.
2- انديشه اساسي و زيربنايی مدل يابي ساختاري
يکي از مفاهيم اساسي که در آمار کاربردي در سطح متوسط وجود دارد اثر انتقالهاي جمع پذير و ضرب پذير در فهرستي از اعداد است. يعني اگر هر يک از اعداد يک فهرست در مقدار ثابت K ضرب شود ميانگين اعداد در همان K ضرب ميشود و به اين ترتيب، انحراف معيار استاندارد در مقدار قدر مطلق K ضرب خواهد شد.
نکته اين است که اگر مجموعه اي از اعداد X با مجموعه ديگري از اعداد Y از طريق معادله Y=4X مرتبط باشند در اين صورت واريانس Y بايد 16 برابر واريانس X باشد و بنابراين از طريق مقايسه واريانسهاي X و Y ميتوانيد به گونه غير مستقيم اين فرضيه را که Y و X از طريق معادله Y=4X با هم مرتبط هستند را بيازماييد.
اين انديشه از طريق تعدادي معادلات خطي از راههاي مختلف به چندين متغير مرتبط با هم تعميم داده ميشود. هرچند قواعد آن پيچيدهتر و محاسبات دشوارتر ميشود، اما پيام کلي ثابت ميماند. يعني با بررسي واريانسها و کوواريانسهاي متغيرها ميتوانيد اين فرضيه را که “متغيرها از طريق مجموعه اي از روابط خطي با هم مرتبط اند” را بيازماييد.
توسعه مدلهاي علّي و همگرايي روشهاي اقتصادسنجي، روان سنجي و غیره
توسعه مدلهاي علّي متغيرهاي مکنون معرف همگرايي سنتهاي پژوهشي نسبتا مستقل در روان سنجي، اقتصادسنجي، زيست شناسي و بسياري از روشهاي قبلا آشناست که آنها را به شکل چهارچوبي وسيع در ميآورد. مفاهيم متغيرهاي مکنون (Latent variables) در مقابل متغيرهاي مشاهده شده (Observed variables) و خطا در متغيرها، تاريخي طولاني دارد.
در اقتصادسنجي آثار جهت دار هم زمان چند متغير بر متغيرهاي ديگر، تحت برچسب مدلهاي معادله همزمان بسيار مورد مطالعه قرار گرفته است. در روان سنجي به عنوان تحليل عاملي و تئوري اعتبار توسعه يافته و شالوده اساسي بسياري از پژوهشهاي اندازه گيري در روانسنجي ميباشد. در زيست شناسي، يک سنت مشابه همواره با مدلهاي معادلات همزمان (گاه با متغيرهاي مکنون) در زمينه نمايش و طرح برآورده در تحليل مسير سر و کار دارد.
3- موارد کاربرد روش ليزرل
روش ليزرل ضمن آنکه ضرايب مجهول مجموعه معادلات ساختاري خطي را برآورد ميکند براي برازش مدلهايي که شامل متغيرهاي مکنون، خطاهاي اندازه گيري در هر يک از متغيرهاي وابسته و مستقل، عليت دو سويه، هم زماني و وابستگي متقابل ميباشد طرح ريزي گرديده است.
اما اين روش را ميتوان به عنوان موارد خاصي براي روشهاي تحليل عاملي تاييدي، تحليل رگرسيون چند متغيري، تحليل مسير، مدلهاي اقتصادي خاص دادههاي وابسته به زمان، مدلهاي برگشت پذير و برگشت ناپذير براي دادههاي مقطعي/ طولي، مدلهاي ساختاري کوواريانس و تحليل چند نمونه اي (مانند آزمون فرضيههاي برابري ماتريس کوواريانس هاي، برابري ماتريس همبستگي ها، برابري معادلات و ساختارهاي عاملي و غيره) نيز به کار برد.
4- نرم افزار ليزرل چیست؟
ليزرل يک محصول نرم افزاري است که به منظور برآورد و آزمون مدلهاي معادلات ساختاري طراحي و از سوي “شرکت بين المللي نرم افزار علمي”
Scientific software international (www.ssicentral.com)
به بازار عرضه شده است. اين نرم افزار با استفاده از همبستگي و کوواريانس اندازه گيري شده، ميتواند مقادير بارهاي عاملي، واريانسها و خطاهاي متغيرهاي مکنون را برآورد يا استنباط کند و از آن ميتوان براي اجراي تحليل عاملي اکتشافي، تحليل عاملي مرتبه دوم، تحليل عاملي تاييدي و همچنين تحليل مسير (مدل يابي علت و معلولي با متغيرهاي مکنون) استفاده کرد.
تحلیل ساختاری کوواریانس که به آن روابط خطی ساختاری نیز می گویند، یکی از تکنیک های تحلیل مدل معادلات ساختاری است. جالب است بدانید که نام LISREL از عبارت
Linear Structural Relations
که به معنای روابط خطی ساختاری است، بدست آمده است.
5- تحليل عاملي اکتشافي (efa) و تحليل عاملي تاييدي (cfa)
تحليل عاملي ميتواند دو صورت اکتشافي و تاييدي داشته باشد. اينکه کدام يک از اين دو روش بايد در تحليل عاملي به کار رود مبتني بر هدف تحليل داده هاست.
تحليل عاملی اکتشافي
در تحليل عاملی اکتشافي(Exploratory factor analysis) پژوهشگر به دنبال بررسي دادههاي تجربي به منظور کشف و شناسايي شاخصها و نيز روابط بين آنهاست و اين کار را بدون تحميل هر گونه مدل معيني انجام ميدهد. به بيان ديگر تحليل عاملی اکتشافي علاوه بر آنکه ارزش تجسسي يا پيشنهادي دارد ميتواند ساختارساز، مدل ساز يا فرضيه ساز باشد.
تحليل اکتشافي وقتي به کار ميرود که پژوهشگر شواهد کافي قبلي و پيش تجربي براي تشکيل فرضيه درباره تعداد عاملهاي زيربنايي دادهها نداشته و به واقع مايل باشد درباره تعيين تعداد يا ماهيت عاملهايي که همپراشي بين متغيرها را توجيه ميکنند دادهها را بکاود. بنابر اين تحليل عاملی اکتشافي بيشتر به عنوان يک روش تدوين و توليد تئوري و نه يک روش آزمون تئوري در نظر گرفته ميشود.
تحليل عاملي اکتشافي روشي است که اغلب براي کشف و اندازه گيري منابع مکنون پراش و همپراش در اندازه گيريهاي مشاهده شده به کار ميرود. پژوهشگران به اين واقعيت پي برده اند که تحليل عاملي اکتشافي ميتواند در مراحل اوليه تجربه يا پرورش تستها کاملا مفيد باشد. توانشهاي ذهني نخستين ترستون، ساختار هوش گيلفورد نمونههاي خوبي براي اين مطلب ميباشد. اما هر چه دانش بيشتري درباره طبيعت اندازه گيريهاي رواني و اجتماعي به دست آيد ممکن است کمتر به عنوان يک ابزار مفيد به کار رود و حتي ممکن است بازدارنده نيز باشد.
از سوي ديگر بيشتر مطالعات ممکن است تا حدي هم اکتشافي و هم تاييدي باشند زيرا شامل متغير معلوم و تعدادي متغير مجهولاند. متغيرهاي معلوم را بايد با دقت زيادي انتخاب کرد تا حتي الامکان درباره متغيرهاي نامعلومي که استخراج ميشود اطلاعات بيشتري فراهمايد. مطلوب آن است که فرضيه اي که از طريق روشهاي تحليل اکتشافي تدوين ميشود از طريق قرار گرفتن در معرض روشهاي آماري دقيقتر تاييد يا رد شود. تحليل عاملی اکتشافي نيازمند نمونههايي با حجم بسيار زياد ميباشد.
تحليل عاملي تاييدي
در تحليل عاملي تاييدي (Confirmatory factor analysis) ، پژوهشگر به دنبال تهيه مدلي است که فرض ميشود دادههاي تجربي را بر پايه چند پارامتر نسبتا اندک، توصيف تبيين يا توجيه ميکند. اين مدل مبتني بر اطلاعات پيش تجربي درباره ساختار داده هاست که ميتواند به شکل:
1) يک تئوري يا فرضيه
2) يک طرح طبقه بندي کننده معين براي گويهها يا پاره تستها در انطباق با ويژگيهاي عيني شکل و محتوا
3)شرايط معلوم تجربي
و يا 4) دانش حاصل از مطالعات قبلي درباره دادههاي وسيع باشد.
تمايز مهم روشهاي تحليل اکتشافي و تاييدي در اين است که روش اکتشافي با صرفهترين روش تبيين واريانس مشترک زيربنايي يک ماتريس همبستگي را مشخص ميکند. در حالي که روشهاي تاييدي (آزمون فرضيه) تعيين ميکنند که دادهها با يک ساختار عاملي معين (که در فرضيه آمده) هماهنگ اند يا نه.
ضمنا خاطر نشان می شود برای دریافت ویدئوی آموزشی تحلیل عاملی تاییدی در نرم افزار لیزرل می توانید به این صفحه مراجعه نمایید:
6- آزمونهاي برازندگي مدل کلي
با آنکه انواع گوناگون آزمونها که به گونه کلي شاخصهاي برازندگي(Fitting indexes) ناميده ميشوند پيوسته در حال مقايسه، توسعه و تکامل ميباشند اما هنوز درباره حتي يک آزمون بهينه نيز توافق همگاني وجود ندارد. نتيجه آن است که مقالههاي مختلف، شاخصهاي مختلفي را ارائه کرده اند و حتي نگارشهاي مشهور برنامههاي SEM مانند نرم افزارهاي lisrel, Amos, EQS نيز تعداد زيادي از شاخصهاي برازندگي به دست ميدهند.(هومن1384 ،235)
اين شاخصها به شيوههاي مختلفي طبقه بندي شده اند که يکي از عمدهترين آنها طبقه بندي به صورت مطلق، نسبي و تعديل يافته ميباشد. برخي از اين شاخص ها عبارتند از:
1-6- شاخصهاي GFI و AGFI
شاخص GFI – Goodness of fit index مقدار نسبي واريانسها و کوواريانسها را به گونه مشترک از طريق مدل ارزيابي ميکند. دامنه تغييرات GFI بين صفر و يک ميباشد. مقدار GFI بايد برابر يا بزرگتر از 0.09 باشد.
شاخص برازندگي ديگر Adjusted Goodness of Fit Index – AGFI يا همان مقدار تعديل يافته شاخص GFI براي درجه آزادي ميباشد. اين مشخصه معادل با کاربرد ميانگين مجذورات به جاي مجموع مجذورات در صورت و مخرج (1- GFI) است. مقدار اين شاخص نيز بين صفر و يک ميباشد. شاخصهاي GFI و AGFI را که جارزکاگ و سوربوم (1989) پيشنهاد کرده اند بستگي به حجم نمونه ندارد.
2-6- شاخص RMSEA
اين شاخص , ريشه ميانگين مجذورات تقريب ميباشد.
شاخص Root Mean Square Error of Approximation – RMSEA براي مدلهاي خوب برابر 0.05 يا کمتر است. مدلهايي که RMSEA آنها 0.1 باشد برازش ضعيفي دارند.
3-6- مجذور کاي
آزمون مجذور كاي (خي دو) اين فرضيه را مدل مورد نظر هماهنگ با الگوي همپراشي بين متغيرهاي مشاهده شده است را ميآزمايد، کميت خي دو بسيار به حجم نمونه وابسته ميباشد و نمونه بزرگ کميت خي دو را بيش از آنچه که بتوان آن را به غلط بودن مدل نسبت داد, افزايش ميدهد. (هومن.1384. 422).
4-6- شاخص NFI و CFI
شاخصNFI (که شاخص بنتلر-بونت هم ناميده ميشود) براي مقادير بالاي 0.09 قابل قبول و نشانه برازندگي مدل است. شاخص CFI بزرگتر از 0.09 قابل قبول و نشانه برازندگي مدل است. اين شاخص از طريق مقايسه يک مدل به اصطلاح مستقل که در آن بين متغيرها هيچ رابطه اي نيست با مدل پيشنهادي مورد نظر، مقدار بهبود را نيز ميآزمايد. شاخص CFI از لحاظ معنا مانند NFI است با اين تفاوت که براي حجم گروه نمونه جريمه ميدهد.
شاخصهاي ديگري نيز در خروجي نرم افزار ليزرل ديده ميشوند که برخي مثل AIC, CAIC ECVA براي تعيين برازندهترين مدل از ميان چند مدل مورد توجه قرار ميگيرند.
براي مثال مدلي که داراي کوچکترين AIC ,CAIC ,ECVA باشد برازندهتر است.(هومن1384 ،244-235) برخي از شاخصها نيز به شدت وابسته به حجم نمونه اند و در حجم نمونههاي بالا ميتوانند معنا داشته باشند.
برگرفته از سایت اطمینان شرق
برای مشاهده لیست همه ی پرسشنامه های استاندارد لطفا همین جا روی پرسشنامه استاندارد کلیک فرمایید.
در این مقاله در خصوص الگوهای معادله ساختاری، تدوین مدل، تشخیص مدل، برآورد مدل، آزمون مدل و اصلاح مدل معادلات ساختاری گفتگو می کنیم.
الگوهای معادله ساختاری
الگوهای معادله ساختاری، مجموعه هایی از معادلات خطی هستند که برای تعیین یک پدیده برحسب متغیرهای علت و معلول از پیش فرض شده به کار می روند. کلی ترین شکل این الگوها امکان اندازه گیری متغیرهایی که نمی توانند مستقیماً اندازه گیری شوند را فراهم می کند. الگوهای معادله ساختاری به ویژه در علوم اجتماعی و رفتاری مفیدند و برای مطالعه رابطه بین وضعیت های اجتماعی و حصول آن ها، تصمیم های مربوط به قابلیت سوددهی شرکت ها، کارایی برنامه های رفتار اجتماعی و دیگر مکانیسم ها مورد استفاده قرار می گیرد.
تدوین مدل
قبل از هر نوع جمع آوری داده و تحلیل، پژوهشگر بایستی مدلی را تدوین نماید که به نظر می رسد مقادیر واریانس- کواریانس آن را تأیید نمایند. به بیان دیگر تدوین مدل تصمیم در این باره است که کدام متغیرها در مدل نظری قرار گیرند و این که این متغیرها چگونه با هم در ارتباط هستند.
یک مدل هنگامی به خوبی تدوین شده است که مدل واقعی جامعه با مدل نظری فرض شده سازگار باشد. به عبارت دیگر ماتریس کواریانس نمونه ای S به طور بسنده ای بوسیله مدل نظری تحت آزمون بازتولید شود. بنابراین هدف تحقق مدلی است که نزدیکترین برازش را با ساختار کواریانس مدل دارا باشد. مثال ساده ای را با دو متغیر X و Y در نظر بگیرید. ما براساس پژوهش قبلی می دانیم که این دو متغیر با یکدیگر ارتباط دارند. اما چرا؟ کدام ارتباط نظری بیانگر این رابطه است؟ آیا X بر Y اثر می گذارد یا عکس این حالت برقرار می باشد و یا متغیر سومی به نام Z بر هردوی آن ها اثر می گذارد. گاه ممکن است با در نظر مدل اولیه نامناسب باعث شویم یک پارامتر با اهمیت از مدل حذف شود (مثلا غفلت کردن از وجود رابطه X و Y) و یا این که یک متغیر مهم را از مدل حذف نماییم. علاوه بر این ممکن است یک پارامتر یا متغیر نامناسب در مدل وارد شوند که سبب ایجاد اریبی در برآورد پارامترها شده و نوعی خطا را در تدوین مدل بوجود می آورد.
تشخیص مدل
در مدل سازی معادلات ساختاری حل مسئله تشخیص مدل پیش از برآورد پارامترها بسیار با اهمیت است. در تشخیص مدل این سؤال مطرح می شود که : آیا براساس داده های نمونه ای موجود در ماتریس کواریانس نمونه ای S و مدل نظری تعریف شده بوسیله ماتریس کواریانس جامعه ∑ می توان مجموعه ی منحصر به فردی از برآورد پارامترها یافت؟
پیش از توضیح در مورد تشخیص مدل، توضیحاتی را در مورد پارامترهای مدل ارائه می دهیم .هر پارامتر در مدل باید به عنوان یک پارامتر آزاد، ثابت یا مقید مشخص شود. یک پارامتر آزاد پارامتری است که شناخته شده نیست و نیازمند برآورد است. پارامتر ثابت، پارامتری است که آزاد نیست اما برای آن یک مقدار مشخص(به طور معمول مقدار صفر یا 1) تعریف شده است. یک پارامتر مقید نیز پارامتری است که مشخص نیست اما برابر با یک یا تعداد بیشتری پارامتر است.
تشخیص مدل در واقع به طرح پارامترها به عنوان ثابت، آزاد یا مقید بستگی دارد. پس از آن که مدل و پارامترها تدوین شدند، این پارامترها برای برای شکل دادن به یک و تنها یک ∑ با یکدیگر ترکیب می شوند. اگر دو یا تعداد بیشتری از مجموعه پارامترها ماتریس ∑ یکسانی را تولید کنند، انگاه این مجموعه ها معادل یا همتا خوانده می شوند.
بر این اساس سه سطح برای تشخیص مدل وجود دارد:
1- یک مدل فرومشخص است اگر یک یا تعداد بیشتری از متغیرها نتوانند به طور یکتایی مشخص شوند زیرا اطلاعات کافی در ماتریس S وجود ندارد.
2- یک مدل کاملا مشخص است اگر همه پارامترها به دلیل وجود اطلاعات کافی در ماتریس S به طور منحصر به فردی تعیین شوند..
3- یک مدل فرامشخص است هنگامی که بیش از یک جواب برای یک یا چند پارامتر وجود دارد.
اگر مدل فرومشخص باشد برآورد پارامترها قابل اعتماد نبوده و در چنین حالتی درجات آزادی مدل صفر یا منفی است. این مدل ممکن است با افزودن قیدهایی مشخص شود. مدل های کاملا مشخص و فرامشخص برای برآورد پارامترها مناسب هستند.
برآورد مدل
گام بعدی بدست آوردن برآوردهایی برای هریک از پارامترهای تعیین شده در مدل است که ماتریس نظری ∑ را تولید می کنند. برآورد پارامترها باید به گونه ای باشد که نزدیک ترین ماتریس به ماتریس واریانس کواریانس نمونه ای بازتولید شود و خطا یعنی ∑-S حداقل شود.
برخی از روش های اولیه برای این منظور شامل حداقل مربعات غیروزنی، حداقل مربعات معمول، حداقل مربعات تعمیم یافته و روش حداکثر درستنمایی است. از میان این روش ها تنها روش حداقل مربعات غیروزنی وابسته به مقیاس است.
آزمون مدل
پس از آنکه برآورد پارامترها برای یک مدل تدوین شده و مشخص بدست آمدند، محقق باید تعیين کند که داده ها تا چه حد با مدل برازش دارند؟
دو شیوه برای برسی برازش مدل وجود دارد : ابتدا ملاحظه برخی آزمون های عمومیت یافته برای برازش کل مدل است و شیوه دوم بررسی برازش پارامترهای منفرد در هریک از اجزای مدل است. آزمو های کلی با عنوان معیارهای برازش مدل شناخته می شوند. بسیاری از این شاخص ها برمبنای مقایسه ماتریس کواریانس اقتباس شده از مدل ∑ با ماتریس کواریانس نمونه ای S ساخته شده اند.
برای بررسی برازش پارامترهای منفرد سه آزمون اصلی مورد استفاده قرار می گیرند:
اول آنکه آیا یک پارامتر آزاد به طور معناداری با صفر تفاوت دارد یا خیر؟
دوم آنکه آیا علامت پاارمتر با آنچه به لحاظ نظری مورد انتظار بوده هماهنگ است؟
و سوم اینکه برآورد پارامترها باید در دامنه مقادیر مورد انتظار قرارگیرند.
هریک از این سؤالات با کمک روش ها و آزمون های آماری مناسب پاسخ داده می شوند.
اصلاح مدل
اگر برازش یک مدل نظری به قوتی که انتظار داشتیم نبود آنگاه گام بعدی اصلاح مدل و ارزیابی مدل اصلاح شده می باشد. فرآیند نمایان سازی خطاهای تدوین مدل به نحوی که مدل های جایگزین تدوین شده به طور مناسب تری ارزیابی شوند ، «جستجوی تدوین» نامیده می شود. هدف از یک جستجوی تدوین تعویض مدل اصلی با مدلی است که در برخی جهات دارای برازش بهتری بوده و پارامترهایی را برآورد می کند که به لحاظ آماری معنادار و به لحاظ نظری دارای معنا و مفهوم باشند.
بررسی ماتریس باقیمانده ها، ملاحظه معناداری آماری پارامترهای مدل و همچنین استفاده از مضرب لاگرانژ و آماره والد از جمله روش های مورد استفاده برای این منظور هستند.
منبع : مقدمه ای بر مدل سازی معادله ساختاری ، نوشته رندال. ای. شوماخر و ریچارد ای لومکس / ترجمه شده توسط دکتر وحید قاسمی/ انتشارات جامعه شناسان.
برگرفته از سایت اطمینان شرق
برای مشاهده لیست همه ی پرسشنامه های استاندارد لطفا همین جا روی پرسشنامه استاندارد کلیک فرمایید.
ما در این سایت پرسشنامه های استاندارد (دارای روایی، پایایی، روش دقیق نمره گذاری ، منبع داخل و پایان متن ) ارائه می کنیم و همچنین تحلیل آماری کمی و کیفی رابا قیمت بسیار مناسب و کیفیت عالی و تجربه بیش از 17 سال انجام می دهیم. برای تماس به ما به شماره 09143444846 در شبکه های اجتماعی پیام بفرستید. ایمیلabazizi1392@gmail.com
تمامی حقوق مادی و معنوی این سایت متعلق به لنسرسرا و محفوظ است.
این سایت دارای مجوز می باشد