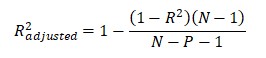روش های آماری پارامتریک و ناپارامتریک
روش های پارامتریک آماری
روش های پارامتریک آماری، روش هایی هستند که برای تحلیل داده ها با استفاده از فرضیاتی درباره توزیع داده ها، استفاده می شوند. به عبارت دیگر، در این روش ها، فرض می شود که داده ها از یک توزیع خاصی، مانند توزیع نرمال، دنبال می کنند و با استفاده از پارامترهایی مانند میانگین و واریانس، توزیع داده ها مدل می شود.
بعضی از روش های پارامتریک آماری شامل موارد زیر هستند:
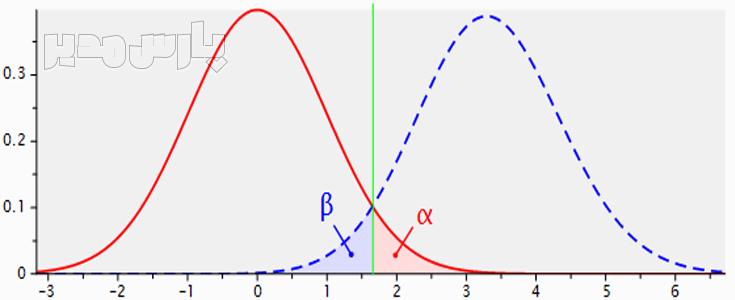
- آزمون تی: این روش برای مقایسه میانگین دو دسته داده استفاده می شود و فرض می شود که داده ها از توزیع نرمال پیروی می کنند.
- آزمون آنوا: این روش برای مقایسه میانگین بیش از دو دسته داده استفاده می شود و فرض می شود که داده ها از توزیع نرمال پیروی می کنند.
- آنالیز رگرسیون: این روش برای بررسی رابطه بین دو متغیر استفاده می شود و فرض می شود که رابطه خطی بین دو متغیر وجود دارد.
- آزمون کای-مربع: این روش برای بررسی رابطه بین دو متغیر غیر عددی استفاده می شود و فرض می شود که داده ها از توزیع خاصی پیروی نمی کنند.
آیا روش های پارامتریک آماری برای داده های پرت و نامتعادل مناسب نیستند؟
بله، روشهای پارامتریک آماری برای دادههای پرت و نامتعادل مناسب نیستند. این روشها برای تحلیل دادهها از فرضیاتی درباره توزیع دادهها استفاده میکنند و به دلیل اینکه دادههای پرت و نامتعادل توزیع دادهها را تحت تأثیر قرار میدهند، دقت و قابلیت تفسیر نتایج را کاهش میدهند.
در دادههای پرت، مقدار یک یا چند داده خارج از محدوده معمول باقی میماند و باعث میشود که توزیع دادهها به شدت از توزیع معمول خود خارج شود. این در حالیست که روشهای پارامتریک برای تحلیل دادهها از فرضیاتی درباره توزیع دادهها استفاده میکنند و اگر دادهها از توزیع معمول خود خارج شوند، ممکن است فرضیات درست نباشد و نتایج تحلیل دادهها نادرست باشد.
در دادههای نامتعادل، تعداد دادهها در هر دسته با یکدیگر متفاوت است و این ممکن است باعث شود که توزیع دادهها در هر دسته با توزیع معمول خود متفاوت باشد. در این موارد، استفاده از روشهای پارامتریک ممکن است باعث نادرستی نتایج تحلیل دادهها شود.
بنابراین، در دادههای پرت و نامتعادل، روشهای ناپارامتریک مانند آزمون ویلکاکسون و آزمون راندومایز شده مناسبتر هستند. این روشها برای تحلیل دادههایی که فرضیات خاصی درباره توزیع دادههایشان وجود ندارد، مناسب هستند و در برخی موارد نتایج دقیقتری نسبت به روشهای پارامتریک به دست میدهند.
روش های پارامتریک آماری مزایایی مانند دقت بالا و قابلیت تفسیر آسان دارند، اما در برخی موارد، فرضیات درباره توزیع داده ها ممکن است نادرست باشند و بهبود نتایج تحلیل داده ها را به خطر بیندازند. همچنین، این روش ها برای داده های پرت و نامتعادل مناسب نیستند. در این
روشهای ناپارامتریک آماری، روشهایی هستند که برای تحلیل دادههایی استفاده میشوند که فرضهای خاصی در مورد توزیع آنها نداریم یا نمیتوانیم این فرضها را بررسی کنیم. این روشها برای دادههای کم حجم و بدون ساختار مناسب هستند و در بسیاری از موارد از دقت بالایی برخوردارند.
برخی از روشهای ناپارامتریک عبارتند از:
- آزمون رتبهای ویلکاکسون: این روش برای مقایسه دو دسته داده برای متغیرهای مستقل وابسته به کار میرود و از ترتیب رتبههای دادهها بجای ارزیابی میزان اختلاف آنها استفاده میکند.
- آزمون کراسکال-والیس: این روش برای مقایسه بیش از دو دسته داده برای متغیرهای مستقل به کار میرود و از رتبهبندی دادهها برای مقایسه تفاوت میان گروهها استفاده میکند.
- آزمون کندال: این روش برای بررسی همبستگی بین دو متغیر بدون نیاز به فرض توزیع خاصی از دادهها به کار میرود.
- آزمون فریدمن: این روش برای مقایسه بیش از دو دسته داده برای متغیرهای وابسته به کار میرود و از رتبهبندی دادهها برای مقایسه تفاوت میان گروهها استفاده میکند.
- رگرسیون ناپارامتریک: این روش برای مدلسازی رابطه بین یک متغیر وابسته و یک یا چند متغیر مستقل بدون نیاز به فرض توزیع خاصی از دادهها به کار میرود.
- روشهای خوشهبندی ناپارامتریک: این روشها برای تقسیم دادهها به چندین خوشه بدون نیاز به فرض توزیع خاصی از دادهها به کار میروند.
- روشهای محاسبه رتبه: این روشها برای ترتیب بندی دادهها و مقایسه تفاوت میان گروهها بدون نیاز به فرض توزیع خاصی از دادهها به کار میروند.
در کل، روشهای ناپارامتریک برای دادههایی که توزیعشان نامشخص است، یا برای زمانی که فرض توزیع خاصی در مورد دادهها نداریم، مناسب هستند.
آیا روشهای ناپارامتریک برای دادههای بزرگ هم مناسب هستند؟
بله، روشهای ناپارامتریک برای دادههای بزرگ نیز مناسب هستند. در واقع، در بسیاری از موارد، روشهای ناپارامتریک برای دادههای بزرگ بهتر از روشهای پارامتریک عمل میکنند. یکی از دلایلی که روشهای ناپارامتریک در برخی موارد برای دادههای بزرگ مناسب هستند، این است که این روشها برای تخمین تابع چگالی احتمال و تابع توزیع تجمعی، از روشهای محاسبه نقطهای استفاده نمیکنند. به عنوان مثال، در آزمون ویلکاکسون، به جای تخمین میانگین و واریانس دو دسته داده، از رتبهبندی دادهها استفاده میشود.
علاوه بر این، روشهای ناپارامتریک برای دادههای بزرگ به دلیل اینکه نیازی به فرض خاصی در مورد توزیع داده ندارند، به عنوان یک روش بدون پارامتر، مقاومت بیشتری در برابر دادههای پرت و نویز دارند. همچنین، این روشها برای تحلیل دادههایی با ساختار پیچیده و بدون ساختار مناسب، از دقت بالایی برخوردارند.
بنابراین، در کل، روشهای ناپارامتریک برای دادههای بزرگ نیز مناسب هستند و در بسیاری از موارد، بهتر از روشهای پارامتریک عمل میکنند.
آیا روشهای ناپارامتریک برای دادههای با توزیع نرمال هم مناسب هستند؟
بله، روشهای ناپارامتریک در مواردی که دادهها دارای توزیع نرمال هستند، به طور کلی به دلیل عدم نیاز به فرض خاصی در مورد توزیع دادهها، قابل استفاده هستند. با این حال، در مواردی که دادهها دارای توزیع نرمال هستند، روشهای پارامتریک نیز میتوانند به خوبی عمل کنند و در برخی موارد دقت بیشتری داشته باشند.
بنابراین، اگر دادههای شما دارای توزیع نرمال هستند، استفاده از روشهای پارامتریک مانند آزمون t و آزمون ANOVA میتواند بهترین گزینه باشد. اما اگر دادهها شامل پرتی و نویز هستند یا توزیع آنها نامشخص است، روشهای ناپارامتریک میتوانند یک گزینه مناسب برای تحلیل دادهها باشند. همچنین، در مواردی که به دلیل اندازه نمونه کوچک، تخمین پارامترهای توزیع دادهها دشوار است، روشهای ناپارامتریک میتوانند بهترین گزینه باشند.