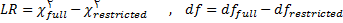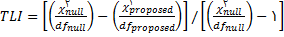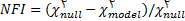بنيان های مدل سازي معادله ساختاري
در این مقاله در خصوص الگوهای معادله ساختاری، تدوین مدل، تشخیص مدل، برآورد مدل، آزمون مدل و اصلاح مدل معادلات ساختاری گفتگو می کنیم.

الگوهای معادله ساختاری
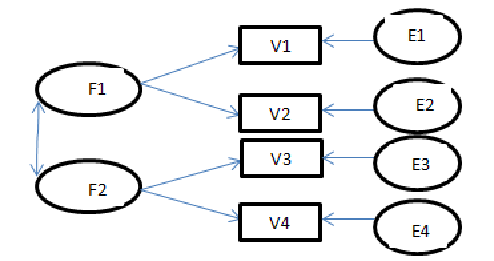
الگوهای معادله ساختاری، مجموعه هایی از معادلات خطی هستند که برای تعیین یک پدیده برحسب متغیرهای علت و معلول از پیش فرض شده به کار می روند. کلی ترین شکل این الگوها امکان اندازه گیری متغیرهایی که نمی توانند مستقیماً اندازه گیری شوند را فراهم می کند. الگوهای معادله ساختاری به ویژه در علوم اجتماعی و رفتاری مفیدند و برای مطالعه رابطه بین وضعیت های اجتماعی و حصول آن ها، تصمیم های مربوط به قابلیت سوددهی شرکت ها، کارایی برنامه های رفتار اجتماعی و دیگر مکانیسم ها مورد استفاده قرار می گیرد.
تدوین مدل
قبل از هر نوع جمع آوری داده و تحلیل، پژوهشگر بایستی مدلی را تدوین نماید که به نظر می رسد مقادیر واریانس- کواریانس آن را تأیید نمایند. به بیان دیگر تدوین مدل تصمیم در این باره است که کدام متغیرها در مدل نظری قرار گیرند و این که این متغیرها چگونه با هم در ارتباط هستند.
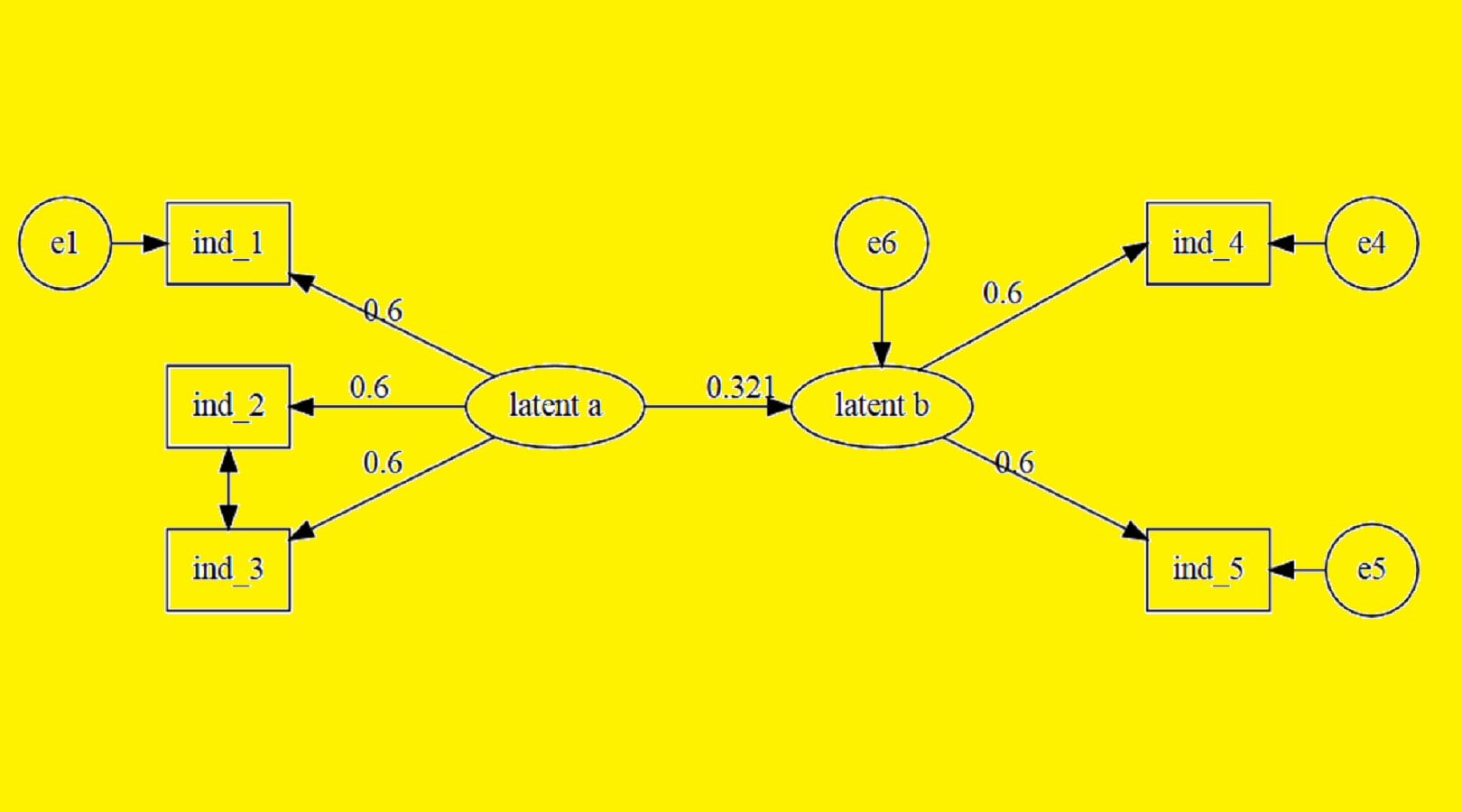
یک مدل هنگامی به خوبی تدوین شده است که مدل واقعی جامعه با مدل نظری فرض شده سازگار باشد. به عبارت دیگر ماتریس کواریانس نمونه ای S به طور بسنده ای بوسیله مدل نظری تحت آزمون بازتولید شود. بنابراین هدف تحقق مدلی است که نزدیکترین برازش را با ساختار کواریانس مدل دارا باشد. مثال ساده ای را با دو متغیر X و Y در نظر بگیرید. ما براساس پژوهش قبلی می دانیم که این دو متغیر با یکدیگر ارتباط دارند. اما چرا؟ کدام ارتباط نظری بیانگر این رابطه است؟ آیا X بر Y اثر می گذارد یا عکس این حالت برقرار می باشد و یا متغیر سومی به نام Z بر هردوی آن ها اثر می گذارد. گاه ممکن است با در نظر مدل اولیه نامناسب باعث شویم یک پارامتر با اهمیت از مدل حذف شود (مثلا غفلت کردن از وجود رابطه X و Y) و یا این که یک متغیر مهم را از مدل حذف نماییم. علاوه بر این ممکن است یک پارامتر یا متغیر نامناسب در مدل وارد شوند که سبب ایجاد اریبی در برآورد پارامترها شده و نوعی خطا را در تدوین مدل بوجود می آورد.
تشخیص مدل
در مدل سازی معادلات ساختاری حل مسئله تشخیص مدل پیش از برآورد پارامترها بسیار با اهمیت است. در تشخیص مدل این سؤال مطرح می شود که : آیا براساس داده های نمونه ای موجود در ماتریس کواریانس نمونه ای S و مدل نظری تعریف شده بوسیله ماتریس کواریانس جامعه ∑ می توان مجموعه ی منحصر به فردی از برآورد پارامترها یافت؟
پیش از توضیح در مورد تشخیص مدل، توضیحاتی را در مورد پارامترهای مدل ارائه می دهیم .هر پارامتر در مدل باید به عنوان یک پارامتر آزاد، ثابت یا مقید مشخص شود. یک پارامتر آزاد پارامتری است که شناخته شده نیست و نیازمند برآورد است. پارامتر ثابت، پارامتری است که آزاد نیست اما برای آن یک مقدار مشخص(به طور معمول مقدار صفر یا 1) تعریف شده است. یک پارامتر مقید نیز پارامتری است که مشخص نیست اما برابر با یک یا تعداد بیشتری پارامتر است.
تشخیص مدل در واقع به طرح پارامترها به عنوان ثابت، آزاد یا مقید بستگی دارد. پس از آن که مدل و پارامترها تدوین شدند، این پارامترها برای برای شکل دادن به یک و تنها یک ∑ با یکدیگر ترکیب می شوند. اگر دو یا تعداد بیشتری از مجموعه پارامترها ماتریس ∑ یکسانی را تولید کنند، انگاه این مجموعه ها معادل یا همتا خوانده می شوند.
بر این اساس سه سطح برای تشخیص مدل وجود دارد:
1- یک مدل فرومشخص است اگر یک یا تعداد بیشتری از متغیرها نتوانند به طور یکتایی مشخص شوند زیرا اطلاعات کافی در ماتریس S وجود ندارد.
2- یک مدل کاملا مشخص است اگر همه پارامترها به دلیل وجود اطلاعات کافی در ماتریس S به طور منحصر به فردی تعیین شوند..
3- یک مدل فرامشخص است هنگامی که بیش از یک جواب برای یک یا چند پارامتر وجود دارد.
اگر مدل فرومشخص باشد برآورد پارامترها قابل اعتماد نبوده و در چنین حالتی درجات آزادی مدل صفر یا منفی است. این مدل ممکن است با افزودن قیدهایی مشخص شود. مدل های کاملا مشخص و فرامشخص برای برآورد پارامترها مناسب هستند.
برآورد مدل
گام بعدی بدست آوردن برآوردهایی برای هریک از پارامترهای تعیین شده در مدل است که ماتریس نظری ∑ را تولید می کنند. برآورد پارامترها باید به گونه ای باشد که نزدیک ترین ماتریس به ماتریس واریانس کواریانس نمونه ای بازتولید شود و خطا یعنی ∑-S حداقل شود.
برخی از روش های اولیه برای این منظور شامل حداقل مربعات غیروزنی، حداقل مربعات معمول، حداقل مربعات تعمیم یافته و روش حداکثر درستنمایی است. از میان این روش ها تنها روش حداقل مربعات غیروزنی وابسته به مقیاس است.
آزمون مدل
پس از آنکه برآورد پارامترها برای یک مدل تدوین شده و مشخص بدست آمدند، محقق باید تعیين کند که داده ها تا چه حد با مدل برازش دارند؟
دو شیوه برای برسی برازش مدل وجود دارد : ابتدا ملاحظه برخی آزمون های عمومیت یافته برای برازش کل مدل است و شیوه دوم بررسی برازش پارامترهای منفرد در هریک از اجزای مدل است. آزمو های کلی با عنوان معیارهای برازش مدل شناخته می شوند. بسیاری از این شاخص ها برمبنای مقایسه ماتریس کواریانس اقتباس شده از مدل ∑ با ماتریس کواریانس نمونه ای S ساخته شده اند.
برای بررسی برازش پارامترهای منفرد سه آزمون اصلی مورد استفاده قرار می گیرند:
- اول آنکه آیا یک پارامتر آزاد به طور معناداری با صفر تفاوت دارد یا خیر؟
- دوم آنکه آیا علامت پاارمتر با آنچه به لحاظ نظری مورد انتظار بوده هماهنگ است؟
- و سوم اینکه برآورد پارامترها باید در دامنه مقادیر مورد انتظار قرارگیرند.
هریک از این سؤالات با کمک روش ها و آزمون های آماری مناسب پاسخ داده می شوند.
اصلاح مدل
اگر برازش یک مدل نظری به قوتی که انتظار داشتیم نبود آنگاه گام بعدی اصلاح مدل و ارزیابی مدل اصلاح شده می باشد. فرآیند نمایان سازی خطاهای تدوین مدل به نحوی که مدل های جایگزین تدوین شده به طور مناسب تری ارزیابی شوند ، «جستجوی تدوین» نامیده می شود. هدف از یک جستجوی تدوین تعویض مدل اصلی با مدلی است که در برخی جهات دارای برازش بهتری بوده و پارامترهایی را برآورد می کند که به لحاظ آماری معنادار و به لحاظ نظری دارای معنا و مفهوم باشند.
بررسی ماتریس باقیمانده ها، ملاحظه معناداری آماری پارامترهای مدل و همچنین استفاده از مضرب لاگرانژ و آماره والد از جمله روش های مورد استفاده برای این منظور هستند.
منبع : مقدمه ای بر مدل سازی معادله ساختاری ، نوشته رندال. ای. شوماخر و ریچارد ای لومکس / ترجمه شده توسط دکتر وحید قاسمی/ انتشارات جامعه شناسان.
برگرفته از سایت اطمینان شرق
- برای مشاهده لیست همه ی پرسشنامه های استاندارد لطفا همین جا روی پرسشنامه استاندارد کلیک فرمایید.
- تحلیل داده های آماری برای پایان نامه و مقاله نویسی ،تحلیل داده های آماری شما با نرم افزارهای کمی و کیفی ،مناسب ترین قیمت و کیفیت عالی انجام می گیرد.نرم افزار های کمی: SPSS- PLS – Amosنرم افزار کیفی: Maxqudaتعیین حجم نمونه با:Spss samplepower
- روش های تماس:Mobile : 09143444846 واتساپ – تلگرام کانال
- تلگرام سایت: برای عضویت در کانال تلگرام سایت اینجا کلیک کنید(البته قبلش فیلتر شکن روشن شود!!) مطالب جالب علمی و آموزشی در این کانال درج می گردد.