- تحلیل تم یا تحلیل مضمون چیست؟

- چند ابزار مهم و کاربردی هوش مصنوعی برای پایان نامه نویسی و مقاله نویسی
- ۱۰ سایت عالی جهت انسانی کردن متون برگرفته از متون هوش مصنوعی
- نرم افزار تحلیل آماری aMOS چیست ؟ و چه شرایطی برای استفاده کردن از آن وجود دارد؟
- راهکارهای کاهش اضطراب در زمان جنگ
- تحلیل دیسکورس (Discourse Analysis) چیست؟

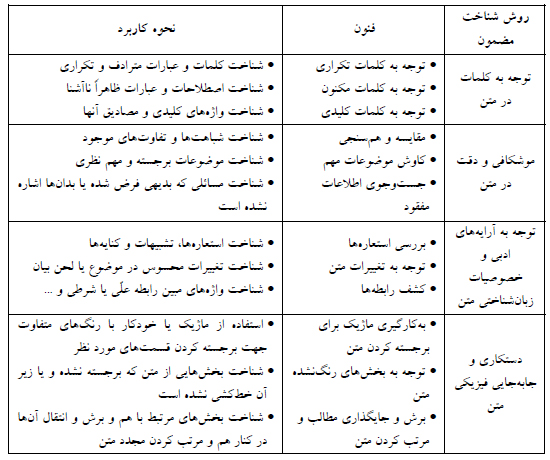
تحلیل تم یا تحلیل مضمون چیست؟ روشی برای تجزیه و تحلیل داده های کیفی است. معمولا برای مجموعه ای از متون پیاده شده مصاحبه یا بحث گروهی استفاده می شود. محقق داده ها را از نزدیک بررسی می کند تا مضامین مشترک، موضوعات، ایده ها و الگوهای معنایی که مکررا مطرح می شوند، را شناسایی کند.
روش تحلیل مضمون چیست؟
سوال پر تکرار تحلیل مضمون چیست دارای روش های مختلفی است، اما رایج ترین شکل آن شامل یک فرآیند شش مرحله ای است: 1. آشنایی، 2. کدگذاری، 3. تولید مضامین، 4. بررسی مضامین، 5. تعریف و نام گذاری مضامین، و 6. نوشتن. فرآیند شش مرحله ی تحلیل مضمون، اولین بار، توسط براون و کلارک در تحقیقات روان شناسی توسعه یافت. تحلیل مضمون در واقع نوعی روش انعطاف پذیر در پژوهش کیفی است که می تواند با بسیاری از انواع مختلف تحقیق تطبیق داده شود.
چه زمان از تحلیل مضمون استفاده کنیم؟
تحلیل مضمون تماتیک یا تحلیل تم و آشنایی با بهترین روش تحلیل مضمون و تحلیل محتوا را در آکادمی پژوهش کیفی دنبال کنید. تحلیل مضمون یا تحلیل تماتیک، رویکرد خوبی برای تحقیق است که در آن شما سعی میکنید از مجموعه ای از داده های کیفی – برای مثال، متن مصاحبه، پروفایل های رسانه های اجتماعی یا پاسخ های نظرسنجی، چیزی در مورد دیدگاه ها، نظرات، دانش، تجربیات یا ارزش های افراد بیابید.
برخی از انواع سوالات پژوهشی که ممکن است برای پاسخ به آن ها از تحلیل مضمون استفاده کنید عبارتند از:
· درک بیماران از پزشکان در یک بستر بیمارستان چگونه است؟
· تجربیات زنان جوان در سایت های همسریابی چیست؟
· ایده ها و نظرات غیر متخصصان در مورد تغییرات آب و هوا چیست؟
· جنسیت در تدریس دبیرستانی چگونه ساخته می شود؟
در تحلیل مضمون، ابتدا برای پاسخ به هر یک از این سوالات، داده های کیفی را از گروهی از شرکت کنندگان مرتبط جمع آوری کرده و سپس آن ها را تجزیه و تحلیل کنید. تحلیل مضمون یا تحلیل تم به شما امکان انعطاف پذیری زیادی را در تفسیر داده ها می دهد و به شما این امکان را می دهد که با دسته بندی آن ها در مضامین گسترده، راحت تر به مجموعه داده های بزرگ نزدیک شوید. با این حال، خطر از دست دادن تفاوت های ظریف در داده ها نیز وجود دارد. تحلیل تماتیک یا تحلیل مضمون اغلب کاملا ذهنی است و به قضاوت محقق متکی است، بنابراین شما باید به دقت در انتخاب ها و تفسیرهای خود تامل کنید. به داده ها توجه زیادی داشته باشید تا اطمینان حاصل کنید که چیزهایی را که وجود ندارند، یا چیزهایی را که هستند، پنهان نمی کنید.
رویکردهای مختلف به تحلیل مضمون
هنگامی که تصمیم به استفاده از تحلیل مضمون گرفتید، رویکردهای مختلفی برای بررسی وجود دارد.
تمایز بین رویکرد های استقرایی و قیاسی وجود دارد:
· یک رویکرد استقرایی شامل اجازه دادن به داده ها برای هدایت و تعیین مضامین شما است.
· یک رویکرد قیاسی شامل دستیابی به داده ها با برخی مضامین از پیش تعیین شده است که انتظار دارید بر اساس تئوری یا دانش پیشین در آنجا منعکس شوند.
از خود بپرسید: آیا چارچوب نظری من یک ایده قوی در مورد مضامین مشخص به من می دهد که به دنبال آنها در داده های خود باشم (رویکرد قیاسی)، یا قصد دارم چارچوب نظری خود را بر اساس آنچه از داده ها می یابم (رویکرد استقرایی) توسعه دهم؟
همچنین تمایزی بین رویکرد معنایی و نهفته وجود دارد:
· یک رویکرد معنایی شامل تجزیه و تحلیل محتوای صریح و آشکار داده ها است.
· یک رویکرد نهفته یا پنهان، شامل خواندن عمق معانی زیرمتن و مفروضات زیربنای داده ها است.
از خود بپرسید: آیا من به نظرات بیان شده افراد (معانی ظاهری داده ها) علاقه مند هستم یا به آنچه اظهارات آن ها در مورد مفروضات و زمینه اجتماعی آن ها آشکار می کند (معانی نهفته)؟
پس از اینکه به این نتیجه رسیدید که تحلیل مضمون یا تحلیل تم روش مناسبی برای تجزیه و تحلیل داده های شماست، و به رویکردی که می خواهید در پیش بگیرید فکر کردید، می توانید شش مرحله توسعه یافته توسط براون و کلارک را دنبال کنید.

مراحل تحلیل مضمون چیست؟
مرحله 1: آشنایی با داده ها
اولین قدم برای پاسخ به این سوال که مراحل تحلیل مضمون چیست این است که اطلاعات خود را بشناسیم. مهم است که قبل از شروع به تجزیه و تحلیل جداگانه واحدهای تحلیل مثل مصاحبه ها، یک نمای کلی از تمام داده هایی که جمع آوری کرده اید، داشته باشید.این ممکن است شامل پیاده کردن صدا، خواندن متن و یادداشت برداری اولیه و به طور کلی بررسی داده ها برای آشنایی با آن باشد.
مرحله 2: کدگذاری
در مرحله بعد، باید داده ها را کدگذاری کنید. کدگذاری به معنای برجسته کردن بخش هایی از متن – معمولا عبارات یا جملات – و ارائه برچسب های مختصر یا “کد” برای توصیف محتوای آن ها است.
نمونه کدگذاری در تحلیل مضمون : در اینجا یک مثال کوتاه در مورد کدگذاری متن در تحلیل مضمون یا تحلیل تم را آورده ایم. فرض کنید که در حال تحقیق بر روی برداشت های مربوط به تغییرات اقلیمی در میان رای دهندگان محافظه کار 50 ساله و بالاتر هستیم و داده هایی را از طریق یک سری مصاحبه جمع آوری کرده ایم. گزیده ای از یک مصاحبه به این صورت است:
کدگذاری داده های کیفی
| خلاصه مصاحبه | کدها |
| شخصا مطمئن نیستم. من فکر می کنم آب و هوا در حال تغییر است، مطمئنا، اما نمی دانم چرا و چگونه. مردم می گویند باید به کارشناسان اعتماد کرد، اما چه کسی می تواند بگوید که آن ها دلایل خاص خود را برای پیشبرد این روایت ندارند؟ من نمی گویم آن ها اشتباه می کنند، فقط می گویم دلایلی وجود دارد که 100٪ به آن ها اعتماد نکنید. واقعیت ها مدام در حال تغییر هستند – قبلا به آن گرم شدن کره زمین می گفتند. | · عدم قطعیت · تصدیق تغییرات آب و هوایی · بی اعتمادی به کارشناسان · تغییر اصطلاحات |
در این خلاصه، ما عبارات مختلفی را بعنوان کد های مختلف نشان دادیم. هر کد، در واقع، ایده یا احساس بیان شده در آن قسمت از متن را توصیف می کند. در این مرحله، ما می خواهیم دقیق تر باشیم: متن هر مصاحبه را مرور می کنیم و هر چیزی را که مرتبط با سوال تحقیق است یا بالقوه جالب است، برجسته می کنیم. علاوه بر برجسته کردن تمام عبارات و جملاتی که با این کدها مطابقت دارند، می توانیم همچنان به افزودن کدهای جدید در متن ادامه دهیم. پس از بررسی متن، تمام داده ها را در گروه هایی که با کد مشخص شده اند، جمع آوری می کنیم. این کدها به ما این امکان را می دهند که یک نمای کلی فشرده از نکات اصلی و معانی رایجی که در سراسر داده تکرار می شوند به دست آوریم.
مرحله 3: تولید مضمون یا تم
در مرحله بعد، کدهایی را که ایجاد کرده ایم بررسی می کنیم، الگوهایی را در میان آن ها شناسایی می کنیم و شروع به ارائه مضامین می کنیم. تحلیل تم ها یا مضامین عموما گسترده تر از کدها هستند. بیشتر اوقات، چندین کد را در یک مضمون یا تم واحد ترکیب می کنید.
نمونه تحلیل مضمون (استخراج مضامین از کدها)
در مثال ما، ممکن است شروع به ترکیب کدها در مضامینی مانند زیر کنیم:
تبدیل کدها به تم یا مضمون
| کدها | تم یا مضمون |
| · عدم قطعیت · آن را به متخصصان بسپارید · توضیحات جایگزین | عدم قطعیت |
| · تغییر اصطلاحات · بی اعتمادی به دانشمندان · رنجش نسبت به کارشناسان · ترس از کنترل دولت | بی اعتمادی به کارشناسان |
| · حقایق نادرست · سوء تفاهم از علم · منابع رسانه ای مغرضانه | اطلاعات غلط |
در این مرحله، ممکن است تصمیم بگیرید که برخی از کدهای خیلی مبهم یا غیر مرتبط (مثلا چون اغلب در داده ها ظاهر نمی شوند)، را از تحلیل کنار گذاشت. سایر کدها ممکن است به خودی خود به مضمون تبدیل شوند. در مثال ما، تصمیم گرفتیم که کد “عدم قطعیت” به عنوان یک مضمون معنی داشته باشد، با برخی کدهای دیگر در آن گنجانده شده است.

مرحله 4: بررسی و مرور مضامین یا تم ها
اکنون باید مطمئن شویم که مضامین ما بازنمایی مفید و دقیق داده ها هستند. در اینجا، ما به مجموعه داده برمی گردیم و مضامین خود را با آن مقایسه می کنیم. آیا چیزی را از دست می دهیم؟ آیا این مضامین واقعا در داده ها وجود دارند؟ چه چیزی را می توانیم تغییر دهیم تا مضامین ما بهتر عمل کنند؟ اگر با مشکلاتی در مضامین خود مواجه شویم، ممکن است آن ها را تقسیم کنیم، ترکیب کنیم، آن ها را کنار بگذاریم یا مضامین جدیدی ایجاد کنیم: هر کاری که آن ها را مفیدتر و دقیق تر کند. برای مثال، ممکن است با بررسی داده ها تصمیم بگیریم که با تغییر برخی اصطلاحات ، مضمون “عدم قطعیت” را بجای “بی اعتمادی به متخصصان” بیاوریم و استفاده کنیم زیرا داده های برچسب گذاری شده با این کد، مستلزم سردرگمی است، نه لزوما بی اعتمادی.
مرحله 5: تعریف و نامگذاری مضامین یا تم ها
اکنون که فهرست نهایی مضامین یا تم ها را دارید، وقت آن است که هر یک از آن ها را نام ببرید و تعریف کنید. تعریف مضامین مستلزم فرمول بندی دقیق است، منظور ما از هر مضمون چیست و درک اینکه چگونه به ما در درک داده ها کمک می کند. نامگذاری مضامین شامل ارائه یک نام مختصر و قابل درک برای هر مضمون یا تم است. برای مثال، ممکن است به ” بی اعتمادی به کارشناسان” نگاه کنیم و دقیقا منظورمان از “متخصصان” در این موضوع را مشخص کنیم. ممکن است تصمیم بگیریم که نام بهتری برای موضوع “بی اعتمادی به قدرت” یا ” تفکر توطئه” باشد.
مرحله 6: نوشتن
در نهایت، ما تجزیه و تحلیل خود را از داده ها می نویسیم. مانند همه متون دانشگاهی، نوشتن یک تحلیل مضمون یا تحلیل تم نیاز به مقدمه ای برای تعیین سوال، اهداف و رویکرد تحقیق ما دارد. ما همچنین باید یک بخش روش شناسی قرار دهیم که نحوه جمع آوری داده ها را توضیح دهد (مثلا از طریق مصاحبه های نیمه ساختار یافته یا سوالات نظرسنجی باز) و توضیح دهد که چگونه تحلیل مضمون را انجام دادیم.
بخش نتایج یا یافته ها معمولا به نوبه خود به هر مضمون می پردازد. ما توضیح می دهیم که هر چند وقت یک بار مضامین مطرح می شوند و معنی آن ها چیست، از جمله مثال هایی از داده ها به عنوان شواهد. در نهایت، نتیجه گیری ما نکات اصلی را توضیح می دهد و نشان می دهد که چگونه تجزیه و تحلیل به سوال تحقیق ما پاسخ داده است.
در مثال ما، ممکن است استدلال کنیم که تفکر توطئه ای درباره تغییرات آب و هوایی در میان رای دهندگان محافظه کار مسن تر شایع است، به عدم قطعیتی که بسیاری از رای دهندگان به این موضوع نگاه می کنند اشاره کنیم، و درباره نقش اطلاعات نادرست در ادراک پاسخ دهندگان بحث کنیم.

تفاوت تحلیل محتوا و تحلیل مضمون چیست؟
یک سوال پرتکرار، این است که “تفاوت تحلیل محتوا و تحلیل مضمون چیست؟” شباهت هایی بین این دو رویکرد تحلیلی وجود دارد. با این حال، تفاوت های کلیدی نیز وجود دارد که آن ها را برای طرح های تحقیقاتی مختلف مناسب می کند.
تحلیل مضمون یا تحلیل تم، روشی برای تجزیه و تحلیل داده های کیفی است. این رویکرد از این جهت انعطاف پذیر است که می توان از آن با طرح های تحقیقاتی مختلف استفاده کرد. تحلیل مضمون برای کاوش الگوها در میان داده های کیفی شرکت کنندگان خوب است و محققان اغلب از آن برای تجزیه و تحلیل مصاحبه ها استفاده می کنند. مضامین یا تم ها ، طبقات کلی داده های مشترک در بین شرکت کنندگان متعدد هستند. تمام داده های متنی موجود در یک موضوع، داستانی را در مورد آن موضوع بیان می کند و به نحوی مرتبط است و ابعاد مختلف یک پدیده را نشان می دهد. تحلیل مضمون یا تماتیک به محققان کمک می کند تا جنبه هایی از یک پدیده را که شرکت کنندگان به طور مکرر یا عمیق درباره آن صحبت می کنند و راه هایی که آن جنبه های یک پدیده ممکن است به هم مرتبط شوند، درک کنند.
در تفاوت تحلیل مضمون و تحلیل محتوا از سوی دیگر، تحلیل محتوا می تواند به عنوان روش کمی یا کیفی تحلیل داده ها مورد استفاده قرار گیرد. حتی در تحلیل محتوای کیفی، کمی سازی داده ها وجود دارد، زیرا تحلیل محتوا به محققان کمک می کند تا نمونه هایی از کدها را بشمارند. تحلیل محتوا را می توان برای سایر داده های متنی و نه فقط مصاحبه ها اعمال کرد. تحلیل محتوا همچنین برای تحلیل تصاویر دیداری مانند تصاویر یا فیلم ها مناسب است. این نوع تحلیل ممکن است به محققین با مقادیر زیادی از داده ها ی متنی کمک کند، زیرا تجزیه و تحلیل محتوا برای تعیین نحوه استفاده از کلمات و الگوهای کلمات در بستر خاص مفید است.
فرآیند تحلیلی هم برای تحلیل مضمون و هم برای تحلیل محتوا از این نظر مشابه است که محقق با داده ها آشنا می شود و روی همه داده ها کدگذاری را انجام می دهد. در تحلیل محتوای مضمونی، محقق به طور سیستماتیک همه داده ها را کدگذاری می کند و سپس شروع به سازماندهی کدها، بر اساس برخی شباهت ها، به طبقات بزرگ تر و بزرگ تر می کند که ممکن است منجر به ساختار سلسله مراتبی کد، مضمون فرعی و مضمون اصلی شود. در تفاوت تحلیل محتوا و تحلیل مضمون و تحلیل تم در تحلیل محتوا، محقق داده ها را کدگذاری می کند و طبقات و زیر طبقات را تولید می کند. ارائه یافته ها در تحلیل مضمون و تحلیل محتوا کمی متفاوت است. مضامین، همراه با گزیده هایی از داده ها، در گزارش نهایی ارائه می شوند که شامل شرح آن موضوعات در رابطه با سوالات تحقیق است، در حالیکه در تحلیل محتوا، محققان اغلب نتایج را به صورت نقشه یا مدل مفهومی ارائه می کنند.
در تفاوت تحلیل مضمون و تحلیل محتوا هر دو ابزار مفیدی در تحقیقات کیفی هستند. علاوه بر این، تحلیل محتوا برای کمی کردن داده های کیفی مفید است. هر دو برای طرح های تحقیقاتی توصیفی نیز مفید هستند. با این حال، تفاوت هایی بین این دو رویکرد وجود دارد، به عبارت دیگر در مورد آنچه محققان در داده های خود به دنبال آن بوده، نحوه تجزیه و تحلیل داده ها و ارائه داده ها، دارای تفاوت هایی هستند.
نمونه مقاله کیفی با رویکرد تحلیل مضمون یا تحلیل تماتیک
The problem with picking: Permittance, escape and shame in problematic skin picking
نمونه پایان نامه با تحلیل مضمون یا تحلیل تم
:Title of thesis
Permittance, Escape and Shame in Problematic Skin Picking
برگرفته از آکادمی پژوهش کیفی – دکتر فریده فراهانی
نوشته
تحلیل شبکه های اجتماعی (Social Network Analysis) — به زبان ساده و جامع
نوشته
فصل 5 : آموزش انویوو: جستجو و بازیابی اطلاعات
نوشته
نوشته
تحلیل شبکه های اجتماعی (Social Network Analysis)
نوشته

















 با تجربهی بیش از 17 سال و ارائهی بهترین خدمات
با تجربهی بیش از 17 سال و ارائهی بهترین خدمات


 با ما در ارتباط باشید:
با ما در ارتباط باشید: تماس: 09143444846 (پیامک، ایتا، واتساپ، تلگرام)
تماس: 09143444846 (پیامک، ایتا، واتساپ، تلگرام) کانال تلگرام:
کانال تلگرام:  کیفیت بالا، قیمت مناسب و خدماتی که به نیازهای شما پاسخ میدهند!
کیفیت بالا، قیمت مناسب و خدماتی که به نیازهای شما پاسخ میدهند!